Elo-Evolve: A Co-evolutionary Framework for Language Model Alignment
作者: Jing Zhao, Ting Zhen, Junwei bao, Hongfei Jiang, Yang song
分类: cs.CL, cs.AI
发布日期: 2026-02-14
💡 一句话要点
提出Elo-Evolve框架以解决大语言模型对齐问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 对齐方法 共进化框架 动态学习 成对比较 Elo调度 自动课程学习
📋 核心要点
- 现有对齐方法依赖静态奖励函数,导致数据稀缺和训练不稳定。
- Elo-Evolve框架通过动态多智能体竞争和对手选择实现对齐,提升学习效率。
- 实验结果表明,Elo-Evolve在多个基准测试中显著优于传统方法,验证了其有效性。
📝 摘要(中文)
当前的大语言模型对齐方法依赖于将大量人类偏好数据压缩为静态的绝对奖励函数,这导致数据稀缺、噪声敏感性和训练不稳定性。我们提出了Elo-Evolve,一个将对齐重新定义为动态多智能体竞争的共进化框架。该方法的两个关键创新是:1) 通过直接从成对竞争中的二元胜负结果学习,消除对Bradley-Terry模型的依赖;2) 实施Elo调度的对手选择,通过温度控制采样提供自动课程学习。我们基于PAC学习理论,证明成对比较在样本复杂性上具有优势,并实证验证与绝对评分方法相比,噪声减少了4.5倍。实验中,我们使用该框架训练了Qwen2.5-7B模型,结果显示Elo-Evolve在Alpaca Eval 2.0和MT-Bench上表现优于其他方法。
🔬 方法详解
问题定义:本论文旨在解决当前大语言模型对齐方法的不足,尤其是静态奖励函数导致的数据稀缺、噪声敏感性和训练不稳定性问题。
核心思路:Elo-Evolve框架通过将对齐视为动态的多智能体竞争,利用成对竞争的胜负结果进行学习,避免了对传统模型的依赖,从而实现更高效的对齐过程。
技术框架:该框架包括一个适应性对手池,采用Elo调度机制进行对手选择,结合温度控制的采样策略,形成一个动态学习环境。
关键创新:最重要的创新在于通过成对比较直接学习胜负结果,消除了对Bradley-Terry模型的依赖,并实现了自动课程学习的对手选择机制。
关键设计:在实现过程中,采用了温度控制的采样策略来调节对手的选择,同时优化了损失函数以适应成对比较的学习需求。
🖼️ 关键图片
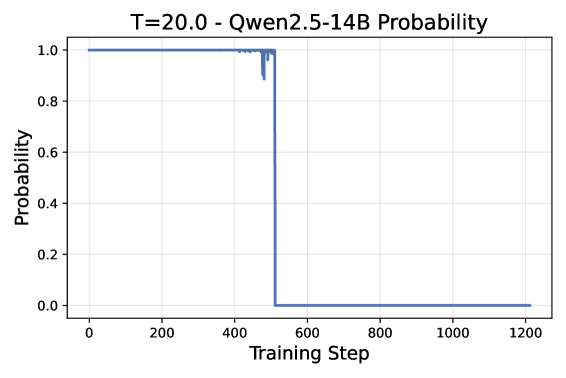
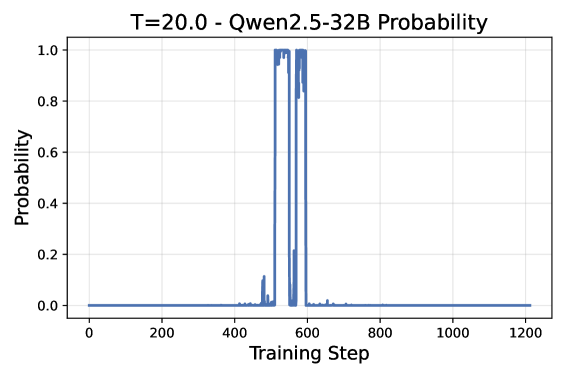
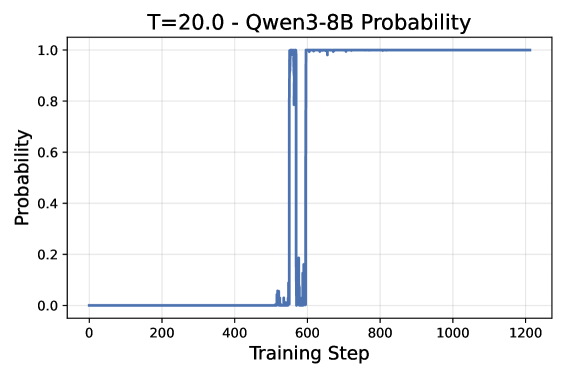
📊 实验亮点
实验结果显示,Elo-Evolve在Alpaca Eval 2.0和MT-Bench基准测试中表现优于点基方法和静态成对训练,验证了成对比较和动态对手选择的逐步优势,噪声减少幅度达到4.5倍,显著提升了模型的对齐效果。
🎯 应用场景
Elo-Evolve框架在大语言模型的对齐任务中具有广泛的应用潜力,能够提升模型在自然语言处理、对话系统等领域的性能。未来,该方法可能推动更高效的模型训练和更准确的用户偏好捕捉,促进人机交互的智能化发展。
📄 摘要(原文)
Current alignment methods for Large Language Models (LLMs) rely on compressing vast amounts of human preference data into static, absolute reward functions, leading to data scarcity, noise sensitivity, and training instability. We introduce Elo-Evolve, a co-evolutionary framework that redefines alignment as dynamic multi-agent competition within an adaptive opponent pool. Our approach makes two key innovations: (1) eliminating Bradley-Terry model dependencies by learning directly from binary win/loss outcomes in pairwise competitions, and (2) implementing Elo-orchestrated opponent selection that provides automatic curriculum learning through temperature-controlled sampling. We ground our approach in PAC learning theory, demonstrating that pairwise comparison achieves superior sample complexity and empirically validate a 4.5x noise reduction compared to absolute scoring approaches. Experimentally, we train a Qwen2.5-7B model using our framework with opponents including Qwen2.5-14B, Qwen2.5-32B, and Qwen3-8B models. Results demonstrate a clear performance hierarchy: point-based methods < static pairwise training < Elo-Evolve across Alpaca Eval 2.0 and MT-Bench, validating the progressive benefits of pairwise comparison and dynamic opponent selection for LLM alignment.