DistillLens: Symmetric Knowledge Distillation Through Logit Lens
作者: Manish Dhakal, Uthman Jinadu, Anjila Budathoki, Rajshekhar Sunderraman, Yi Ding
分类: cs.CL
发布日期: 2026-02-14
备注: Knowledge Distillation in LLMs
🔗 代码/项目: GITHUB
💡 一句话要点
DistillLens:通过Logit Lens实现对称知识蒸馏,提升LLM指令跟随能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 Logit Lens 指令跟随 模型压缩 对称散度 中间层表示
📋 核心要点
- 现有知识蒸馏方法通常忽略教师模型中间层的思考过程,特征蒸馏方法也未能充分利用中间层的不确定性信息。
- DistillLens通过Logit Lens将中间隐藏状态投影到词汇空间,使用对称散度目标对齐学生和教师模型的思考过程。
- 实验表明,DistillLens在GPT-2和Llama等架构上,相比标准KD和特征迁移方法,在指令跟随任务上表现更优。
📝 摘要(中文)
标准的知识蒸馏(KD)通过优化最终输出来压缩大型语言模型(LLM),但通常将教师模型的中间层思考过程视为黑盒。虽然基于特征的蒸馏试图弥补这一差距,但现有方法(例如,MSE和非对称KL散度)忽略了最终输出所需的丰富不确定性分布。本文提出了DistillLens,一个对称地对齐学生和教师模型演进的思考过程的框架。通过Logit Lens将中间隐藏状态投影到词汇空间,我们使用对称散度目标来强制结构对齐。我们的分析证明,这种约束施加了双向惩罚,防止了过度自信和不自信,同时保留了最终推导所需的高熵信息通道。在GPT-2和Llama架构上的大量实验表明,DistillLens在各种指令跟随基准测试中始终优于标准KD和特征迁移基线。
🔬 方法详解
问题定义:现有知识蒸馏方法,尤其是针对大型语言模型的蒸馏,通常只关注最终输出的对齐,而忽略了教师模型在中间层的推理过程。基于特征的蒸馏方法虽然尝试利用中间层信息,但常用的MSE或非对称KL散度等损失函数,无法有效捕捉和传递中间层隐藏状态中蕴含的丰富不确定性信息,导致学生模型难以学习到教师模型的完整推理过程。
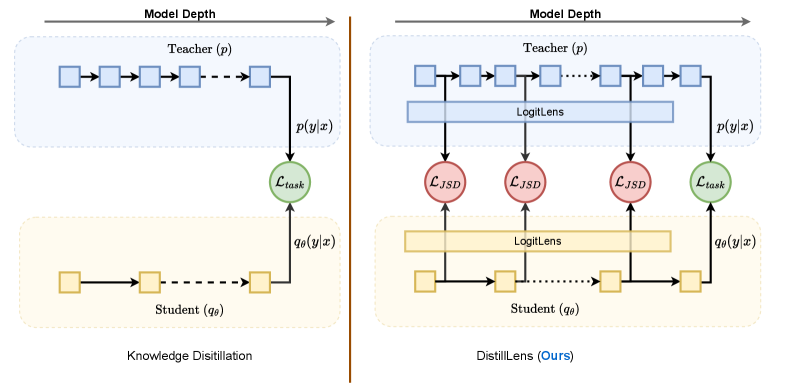
核心思路:DistillLens的核心思想是通过Logit Lens将中间层的隐藏状态投影到词汇空间,从而显式地观察和对齐学生模型和教师模型的“思考”过程。通过在词汇空间上施加对称的散度约束,可以同时避免学生模型过度自信和不自信,并保留重要的信息通道,从而更有效地传递教师模型的知识。
技术框架:DistillLens框架主要包含以下几个步骤:1) 提取教师模型和学生模型在特定中间层的隐藏状态;2) 使用Logit Lens将这些隐藏状态投影到词汇空间,得到每个词的logits;3) 计算教师模型和学生模型在词汇空间上的对称散度(例如,对称KL散度);4) 将该散度作为损失函数的一部分,用于训练学生模型。整个过程旨在对齐学生和教师模型在中间层的“思考”过程,而不仅仅是最终输出。
关键创新:DistillLens的关键创新在于:1) 使用Logit Lens将隐藏状态投影到词汇空间,从而可以显式地对齐中间层的推理过程;2) 采用对称散度作为损失函数,可以同时防止学生模型过度自信和不自信,从而更有效地传递知识。这种对称性是与现有非对称KL散度方法的主要区别。
关键设计:DistillLens的关键设计包括:1) Logit Lens的具体实现,即如何将隐藏状态有效地投影到词汇空间;2) 对称散度的选择,例如,可以使用KL散度的对称版本;3) 中间层的选择,需要根据具体的模型架构和任务进行调整;4) 损失函数的权重,需要平衡最终输出损失和中间层对齐损失。
🖼️ 关键图片
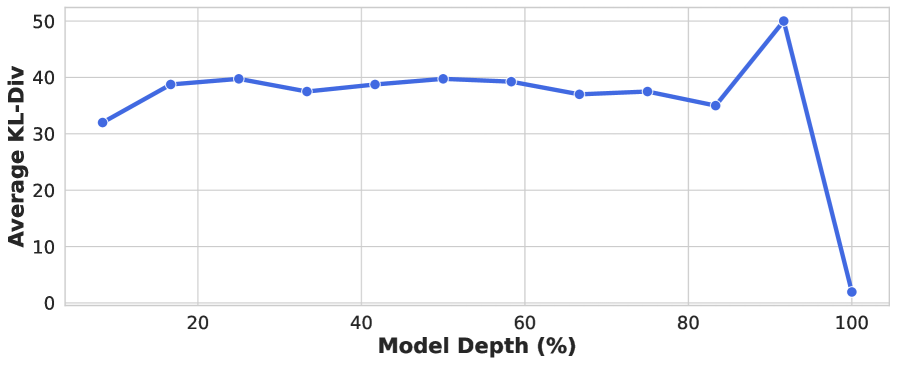
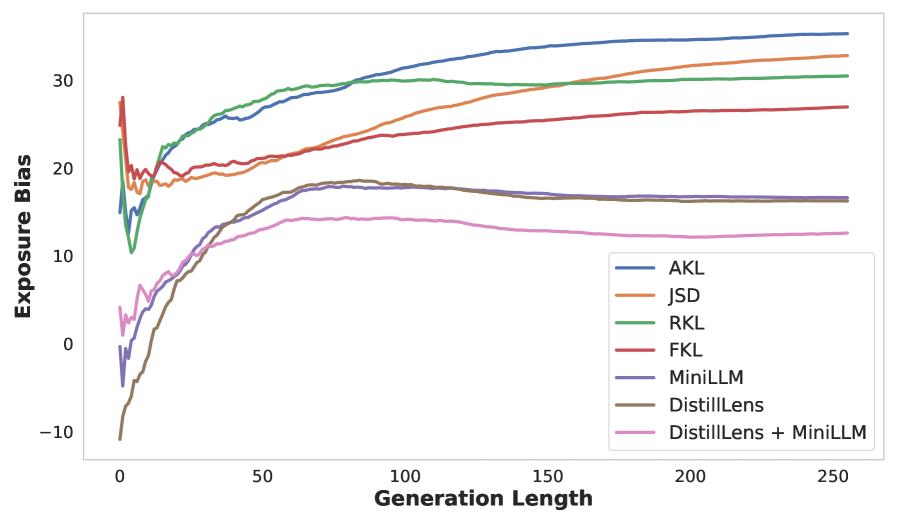
📊 实验亮点
实验结果表明,DistillLens在GPT-2和Llama等架构上,相比标准知识蒸馏和特征迁移方法,在指令跟随任务上取得了显著的性能提升。具体而言,DistillLens在多个基准测试中都优于现有方法,证明了其有效性。代码已开源,方便研究人员复现和进一步研究。
🎯 应用场景
DistillLens可应用于各种需要压缩大型语言模型的场景,例如在资源受限的设备上部署LLM,或者加速LLM的推理速度。该方法可以提升小型模型在指令跟随、文本生成等任务上的性能,使其更接近大型教师模型的水平。未来,DistillLens可以扩展到其他类型的模型和任务,例如视觉语言模型和多模态任务。
📄 摘要(原文)
Standard Knowledge Distillation (KD) compresses Large Language Models (LLMs) by optimizing final outputs, yet it typically treats the teacher's intermediate layer's thought process as a black box. While feature-based distillation attempts to bridge this gap, existing methods (e.g., MSE and asymmetric KL divergence) ignore the rich uncertainty profiles required for the final output. In this paper, we introduce DistillLens, a framework that symmetrically aligns the evolving thought processes of student and teacher models. By projecting intermediate hidden states into the vocabulary space via the Logit Lens, we enforce structural alignment using a symmetric divergence objective. Our analysis proves that this constraint imposes a dual-sided penalty, preventing both overconfidence and underconfidence while preserving the high-entropy information conduits essential for final deduction. Extensive experiments on GPT-2 and Llama architectures demonstrate that DistillLens consistently outperforms standard KD and feature-transfer baselines on diverse instruction-following benchmarks. The code is available at https://github.com/manishdhakal/DistillLens.