LiveNewsBench: Evaluating LLM Web Search Capabilities with Freshly Curated News
作者: Yunfan Zhang, Kathleen McKeown, Smaranda Muresan
分类: cs.IR, cs.CL, cs.LG
发布日期: 2026-02-14
备注: An earlier version of this work was publicly available on OpenReview as an ICLR 2026 submission in September 2025
💡 一句话要点
LiveNewsBench:利用新鲜新闻评估LLM的Web搜索能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Web搜索 信息检索 基准测试 实时信息 代理式搜索 问答系统
📋 核心要点
- 现有LLM在实时信息检索方面潜力巨大,但缺乏有效评估其Web搜索能力的基准。
- LiveNewsBench通过从最新新闻中自动生成问答对,评估LLM的代理式Web搜索能力。
- 该基准包含多跳搜索、页面访问和推理等复杂问题,并提供大规模训练数据和人工验证集。
📝 摘要(中文)
具备代理式Web搜索能力的大型语言模型(LLM)在需要实时信息访问和复杂事实检索的任务中显示出强大的潜力,但评估此类系统仍然具有挑战性。我们引入了LiveNewsBench,这是一个严格且定期更新的基准,旨在评估LLM的代理式Web搜索能力。LiveNewsBench自动从最近的新闻文章中生成新鲜的问答对,确保问题需要超出LLM训练数据的信息,并能够清楚地区分内部知识和搜索能力。该基准包含需要多跳搜索查询、页面访问和推理的有意设计的难题,使其非常适合评估代理式搜索行为。我们的自动化数据管理和问题生成流程能够频繁更新基准,并支持构建用于代理式Web搜索模型的大规模训练数据集,从而解决研究社区中此类数据稀缺的问题。为了确保可靠的评估,我们在测试集中包含人工验证样本的子集。我们使用LiveNewsBench评估了广泛的系统,包括商业和开源LLM以及基于LLM的Web搜索API。排行榜、数据集和代码可在livenewsbench.com上公开获取。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)虽然具备一定的Web搜索能力,但缺乏一个能够有效、可靠地评估其在实时信息检索任务中表现的基准。已有的基准往往无法区分LLM的内部知识和实际搜索能力,并且难以模拟真实世界中需要多步骤推理和信息整合的复杂搜索场景。此外,缺乏高质量的训练数据也限制了代理式Web搜索模型的发展。
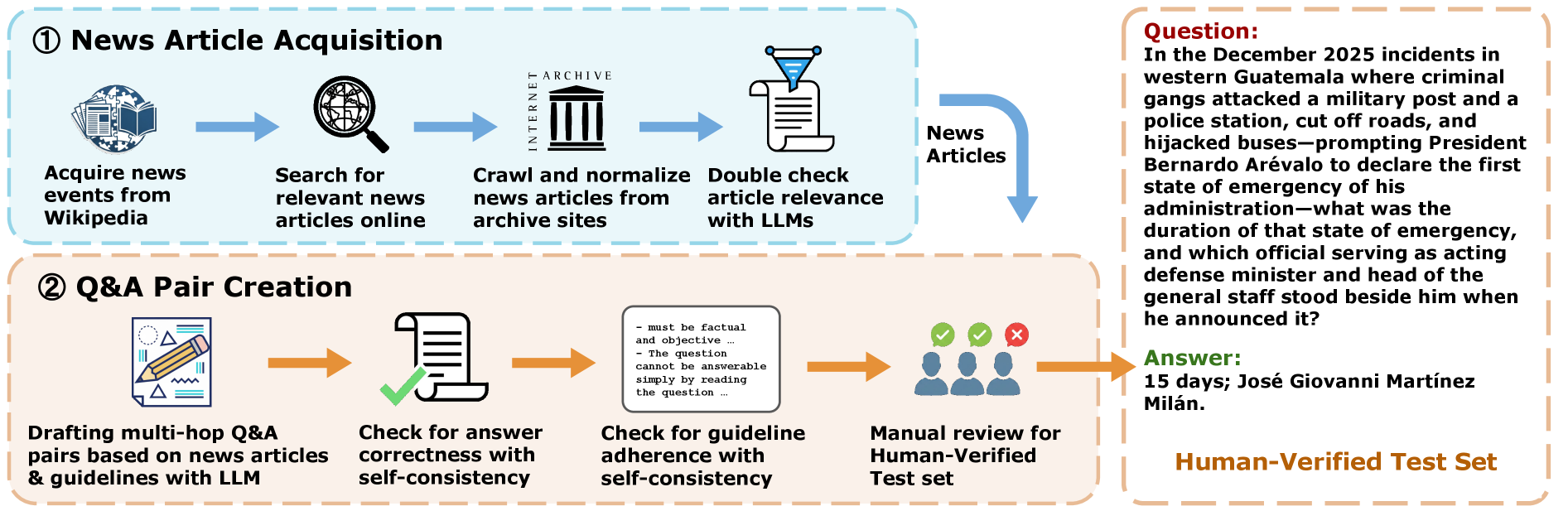
核心思路:LiveNewsBench的核心思路是利用新鲜的新闻文章作为信息来源,自动生成需要LLM进行Web搜索才能回答的问题。通过这种方式,可以确保问题答案不在LLM的预训练知识中,从而真实地评估其搜索能力。同时,该基准设计了需要多跳搜索、页面访问和推理的复杂问题,以考察LLM在复杂信息检索场景下的表现。
技术框架:LiveNewsBench的整体框架包括以下几个主要模块:1) 新闻文章抓取模块:定期抓取最新的新闻文章,作为问题生成的数据来源。2) 问答对生成模块:基于新闻文章的内容,自动生成问答对。该模块采用多种策略,包括关键词提取、关系抽取等,以生成不同类型的、具有挑战性的问题。3) 人工验证模块:对自动生成的问答对进行人工验证,确保其质量和准确性。4) 评估模块:使用生成的问答对评估LLM的Web搜索能力,并生成排行榜。
关键创新:LiveNewsBench的关键创新在于其自动化数据管理和问题生成流程,能够频繁更新基准,并支持构建大规模训练数据集。与现有的基准相比,LiveNewsBench更加关注LLM在实时信息检索任务中的表现,并且能够更好地模拟真实世界中的复杂搜索场景。此外,该基准还提供了人工验证的样本,以确保评估的可靠性。
关键设计:LiveNewsBench在问题生成方面采用了多种策略,包括:1) 多跳问题生成:生成需要LLM进行多次搜索才能找到答案的问题。2) 页面访问问题生成:生成需要LLM访问多个网页才能找到答案的问题。3) 推理问题生成:生成需要LLM进行推理才能找到答案的问题。此外,该基准还提供了多种评估指标,包括准确率、召回率等,以全面评估LLM的Web搜索能力。
🖼️ 关键图片
📊 实验亮点
LiveNewsBench评估了包括商业和开源LLM在内的多种系统,结果显示,即使是最先进的LLM在处理需要多跳搜索和复杂推理的问题时,性能仍有待提高。该基准的排行榜和数据集已公开,为研究人员提供了一个有价值的资源,促进了LLM Web搜索能力的研究和发展。
🎯 应用场景
LiveNewsBench可应用于评估和提升LLM在信息检索、问答系统、智能助手等领域的性能。通过该基准,研究人员可以更好地了解LLM的Web搜索能力,并开发出更有效的搜索策略和模型。此外,LiveNewsBench提供的大规模训练数据集也有助于推动代理式Web搜索模型的发展,促进相关技术的进步。
📄 摘要(原文)
Large Language Models (LLMs) with agentic web search capabilities show strong potential for tasks requiring real-time information access and complex fact retrieval, yet evaluating such systems remains challenging. We introduce \bench, a rigorous and regularly updated benchmark designed to assess the agentic web search abilities of LLMs. \bench automatically generates fresh question-answer pairs from recent news articles, ensuring that questions require information beyond an LLM's training data and enabling clear separation between internal knowledge and search capability. The benchmark features intentionally difficult questions requiring multi-hop search queries, page visits, and reasoning, making it well-suited for evaluating agentic search behavior. Our automated data curation and question generation pipeline enables frequent benchmark updates and supports construction of a large-scale training dataset for agentic web search models, addressing the scarcity of such data in the research community. To ensure reliable evaluation, we include a subset of human-verified samples in the test set. We evaluate a broad range of systems using \bench, including commercial and open-weight LLMs as well as LLM-based web search APIs. The leaderboard, datasets, and code are publicly available at livenewsbench.com.