Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
作者: Wei-Lin Chen, Liqian Peng, Tian Tan, Chao Zhao, Blake JianHang Chen, Ziqian Lin, Alec Go, Yu Meng
分类: cs.CL
发布日期: 2026-02-13
备注: Work in progress
💡 一句话要点
提出基于深度思考Token的大语言模型推理努力度量方法,并优化推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 深度思考Token 推理效率 模型评估 自洽性 Think@n策略
📋 核心要点
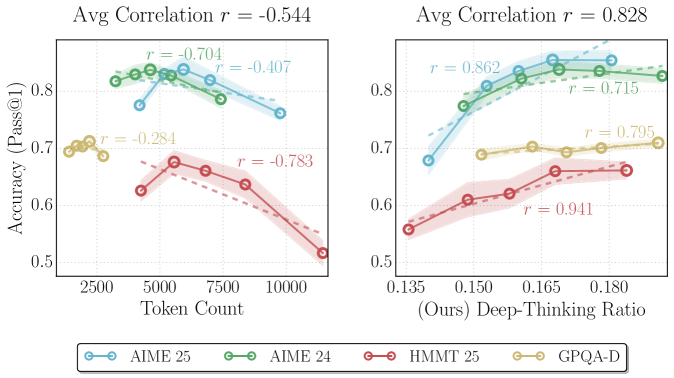
- 现有方法依赖token数量评估LLM推理质量,但token数量与推理准确性并非总是正相关,可能导致“过度思考”。
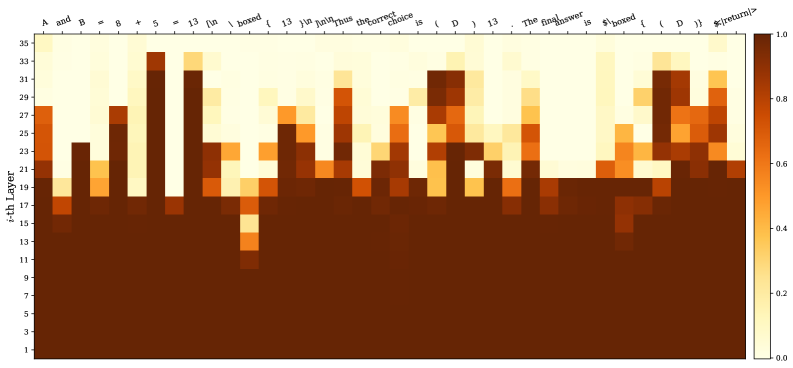
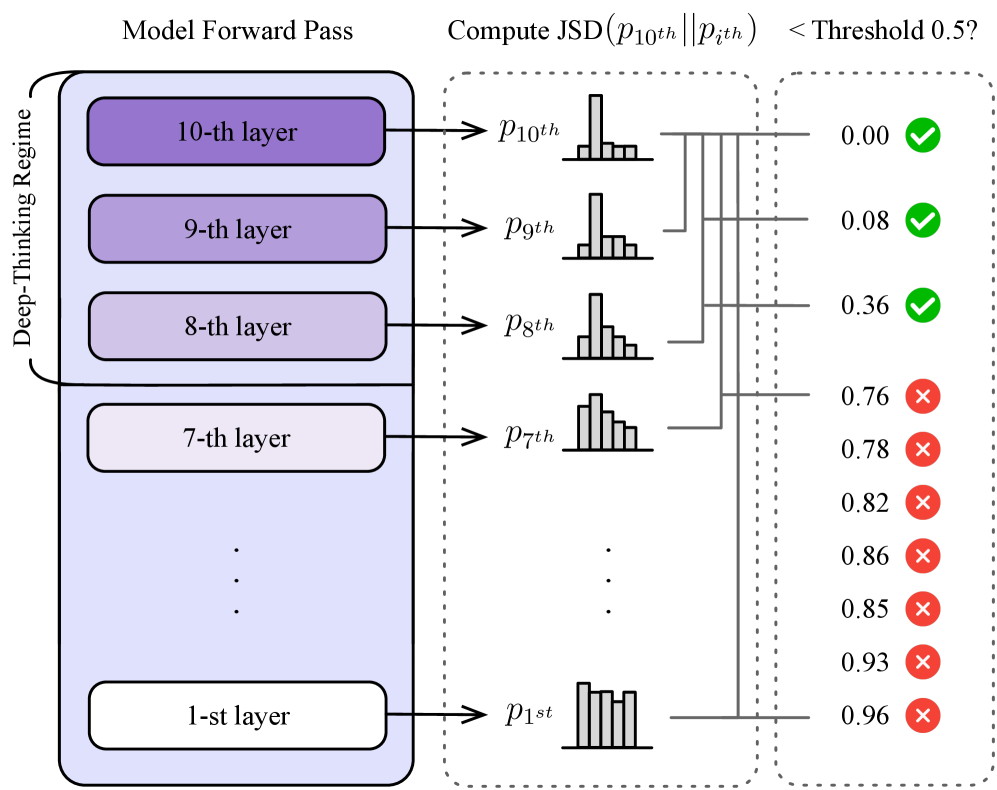
- 论文提出“深度思考token”概念,通过追踪token在模型深层的预测修正程度来量化推理努力程度。
- 实验表明,深度思考率与准确性高度相关,并提出Think@n策略,在保证性能的同时降低推理成本。
📝 摘要(中文)
大型语言模型(LLMs)通过增加推理时的计算量,例如使用长链式思考(CoT),展示了令人印象深刻的推理能力。然而,最近的研究表明,原始token计数并不能可靠地代表推理质量:生成长度的增加并不总是与准确性相关,反而可能表明“过度思考”,导致性能下降。本文通过识别深度思考token来量化推理时的努力程度——这些token在收敛之前,其内部预测在更深的模型层中经历了显著的修正。在四个具有挑战性的数学和科学基准测试(AIME 24/25、HMMT 25和GPQA-diamond)以及一组不同的以推理为中心的模型(GPT-OSS、DeepSeek-R1和Qwen3)上,我们表明深度思考率(生成序列中深度思考token的比例)与准确性呈现出稳健且持续的正相关关系,大大优于基于长度和基于置信度的基线方法。基于这一洞察,我们引入了Think@n,一种测试时扩展策略,优先考虑具有高深度思考率的样本。我们证明Think@n在匹配或超过标准自洽性能的同时,通过基于短前缀提前拒绝没有希望的生成结果,显著降低了推理成本。
🔬 方法详解
问题定义:现有的大语言模型推理评估方法,如token计数,无法准确反映模型的推理努力程度和质量。简单地增加生成token数量并不一定提高准确性,反而可能导致“过度思考”,降低性能。因此,需要一种更精确的方法来衡量模型在推理过程中所付出的努力。
核心思路:论文的核心思路是通过追踪token在模型深层的预测变化来判断其是否为“深度思考token”。如果一个token在模型更深层经历了显著的预测修正,则认为该token代表了模型在进行更深入的推理。通过计算“深度思考率”(即深度思考token在生成序列中的比例),可以更准确地评估模型的推理努力程度。
技术框架:该方法主要包含以下几个阶段:1. Token生成:使用LLM生成一段文本序列。2. 深度预测追踪:对于每个token,追踪其在模型不同层级的预测结果。3. 深度思考Token识别:通过比较不同层级的预测差异,识别出“深度思考token”。4. 深度思考率计算:计算深度思考token在整个序列中的比例。5. Think@n策略:基于深度思考率,动态调整推理过程,例如提前停止低深度思考率的生成。
关键创新:该论文的关键创新在于提出了“深度思考token”这一概念,并将其用于量化LLM的推理努力程度。与传统的基于token数量或置信度的评估方法相比,深度思考率能够更准确地反映模型的推理过程,并与准确性呈现更强的相关性。此外,Think@n策略能够根据深度思考率动态调整推理过程,从而在保证性能的同时降低推理成本。
关键设计:论文中关键的设计包括:1. 预测差异的度量方式:需要选择合适的指标来衡量不同层级预测结果之间的差异,例如KL散度或余弦相似度。2. 深度思考token的阈值设定:需要设定一个阈值来判断一个token是否为“深度思考token”,该阈值可能需要根据不同的模型和数据集进行调整。3. Think@n策略的实现细节:需要确定何时停止生成,以及如何选择具有较高深度思考率的样本。
🖼️ 关键图片
📊 实验亮点
实验结果表明,深度思考率与准确性呈现出稳健且持续的正相关关系,优于基于长度和基于置信度的基线方法。Think@n策略在四个具有挑战性的数学和科学基准测试(AIME 24/25、HMMT 25和GPQA-diamond)上,在匹配或超过标准自洽性能的同时,显著降低了推理成本。
🎯 应用场景
该研究成果可应用于提升大语言模型的推理效率和可靠性。例如,在资源受限的场景下,可以使用Think@n策略提前停止低质量的生成,从而节省计算资源。此外,深度思考率还可以作为一种评估指标,用于比较不同模型的推理能力,或指导模型的训练和优化。
📄 摘要(原文)
Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal "overthinking," leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens -- tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@n, a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@n matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.