Semantic Chunking and the Entropy of Natural Language
作者: Weishun Zhong, Doron Sivan, Tankut Can, Mikhail Katkov, Misha Tsodyks
分类: cs.CL, cond-mat.dis-nn, cond-mat.stat-mech, cs.AI
发布日期: 2026-02-13 (更新: 2026-02-18)
备注: 29 pages, 9 figures; typos fixed
💡 一句话要点
提出基于语义分块的自然语言熵模型,解释语言冗余度并预测熵率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 语义分块 熵率 语言模型 信息论
📋 核心要点
- 现有方法难以从根本上解释自然语言的高冗余度,以及不同语义复杂度的文本熵率差异。
- 论文提出一种基于语义分块的统计模型,将文本自相似地分割成语义连贯的块,从而捕捉多尺度结构。
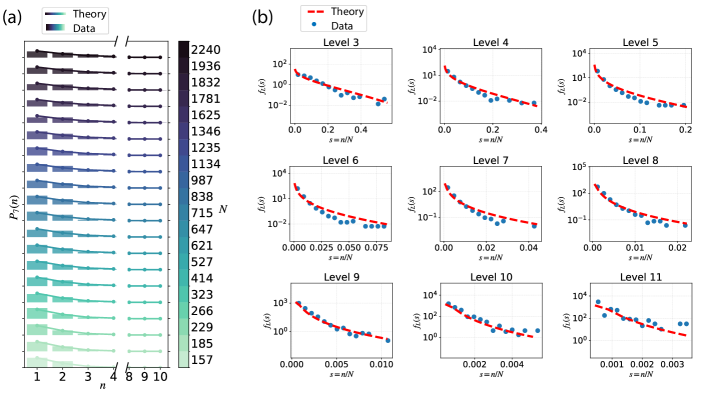
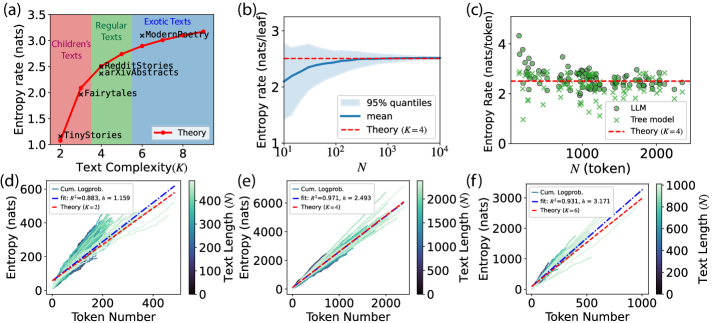
- 实验表明,该模型能定量捕捉真实文本在不同语义层次上的结构,预测的熵率与实际相符,并揭示了熵率与语义复杂度的关系。
📝 摘要(中文)
本文提出了一种统计模型,旨在捕捉自然语言复杂的、多尺度的结构,从而从第一性原理的角度解释其冗余度。该模型描述了一个将文本自相似地分割成语义连贯的块(直至单字级别)的过程。文本的语义结构可以被分层分解,从而进行分析处理。通过现代大型语言模型和开放数据集进行的数值实验表明,该模型能够定量地捕捉真实文本在不同语义层次上的结构。该模型预测的熵率与印刷英语的估计熵率相符。此外,该理论还揭示了自然语言的熵率不是固定的,而是应该随着语料库的语义复杂性而系统地增加,而语料库的语义复杂性由模型中唯一的自由参数捕获。
🔬 方法详解
问题定义:论文旨在解决自然语言的冗余度问题,即英语文本的熵率远低于随机文本的熵率。现有方法未能充分解释这种冗余度,也未能解释不同语义复杂度的文本熵率的差异。现有的语言模型虽然在生成文本方面表现出色,但缺乏对语言内在结构和信息量的理论解释。
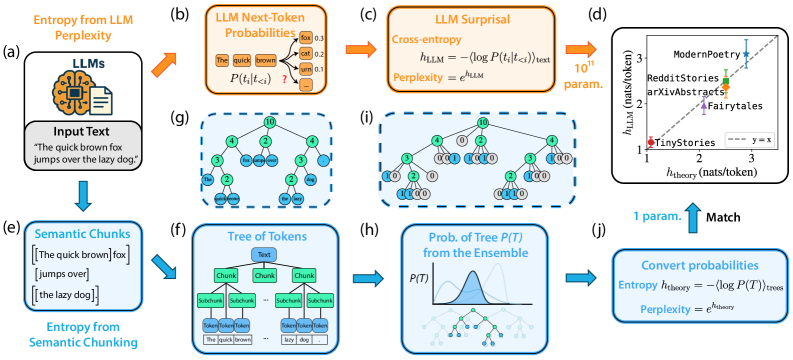
核心思路:论文的核心思路是将文本分解为具有语义连贯性的块(chunks),并构建一个层次化的语义结构。通过这种分块和层次化,可以更好地理解文本的内在结构,并从第一性原理的角度推导出文本的熵率。这种方法类似于人类理解语言的方式,即通过将句子分解为更小的语义单元来理解其含义。
技术框架:该模型包含以下几个主要步骤:1. 文本分块:将文本自相似地分割成语义连贯的块,直到单字级别。2. 语义层次构建:将分块后的文本组织成一个层次化的语义结构,反映不同层次的语义关系。3. 熵率计算:基于构建的语义层次结构,计算文本的熵率。该模型使用一个自由参数来捕捉语料库的语义复杂性。
关键创新:该论文的关键创新在于提出了一个基于语义分块的统计模型,能够从第一性原理的角度解释自然语言的冗余度。与传统的基于字符或单词的统计模型不同,该模型考虑了文本的语义结构,并能够捕捉不同层次的语义关系。此外,该模型还揭示了自然语言的熵率与语义复杂性之间的关系。
关键设计:模型的关键设计在于自相似分块算法和层次化语义结构的构建。具体的分块算法和层次结构构建方法在论文中可能没有详细描述,需要参考相关文献或作者的进一步解释。自由参数的选择和优化也是一个关键的设计细节,它决定了模型对不同语义复杂度的文本的适应能力。损失函数和网络结构等技术细节未知,因为摘要中没有提及。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该模型能够定量地捕捉真实文本在不同语义层次上的结构,预测的熵率与印刷英语的估计熵率相符。更重要的是,该模型揭示了自然语言的熵率不是固定的,而是应该随着语料库的语义复杂性而系统地增加,这为理解自然语言的本质提供了新的视角。
🎯 应用场景
该研究成果可应用于自然语言处理的多个领域,例如文本压缩、信息检索、机器翻译等。通过理解自然语言的内在结构和信息量,可以设计更有效的文本压缩算法,提高信息检索的准确率,以及改进机器翻译的质量。此外,该研究还可以帮助我们更好地理解人类语言的认知机制。
📄 摘要(原文)
The entropy rate of printed English is famously estimated to be about one bit per character, a benchmark that modern large language models (LLMs) have only recently approached. This entropy rate implies that English contains nearly 80 percent redundancy relative to the five bits per character expected for random text. We introduce a statistical model that attempts to capture the intricate multi-scale structure of natural language, providing a first-principles account of this redundancy level. Our model describes a procedure of self-similarly segmenting text into semantically coherent chunks down to the single-word level. The semantic structure of the text can then be hierarchically decomposed, allowing for analytical treatment. Numerical experiments with modern LLMs and open datasets suggest that our model quantitatively captures the structure of real texts at different levels of the semantic hierarchy. The entropy rate predicted by our model agrees with the estimated entropy rate of printed English. Moreover, our theory further reveals that the entropy rate of natural language is not fixed but should increase systematically with the semantic complexity of corpora, which are captured by the only free parameter in our model.