Exploring a New Competency Modeling Process with Large Language Models
作者: Silin Du, Manqing Xin, Raymond Jia Wang
分类: cs.CL
发布日期: 2026-02-13
💡 一句话要点
提出基于大语言模型的新型胜任力建模流程,提升人才管理的效率与客观性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 胜任力建模 大语言模型 人力资源管理 文本分析 信息融合
📋 核心要点
- 传统胜任力建模依赖专家手工分析,存在成本高、主观性强、可重复性差等问题。
- 利用大语言模型提取行为和心理描述,并映射到胜任力库,实现自动化建模。
- 通过可学习参数自适应整合信息,并提出离线评估方法,验证模型有效性。
📝 摘要(中文)
胜任力建模广泛应用于人力资源管理中,用于人才的选拔、培养和评估。然而,传统的专家驱动方法严重依赖于对大量访谈记录的手工分析,成本高昂,且容易出现随机性、模糊性和可重复性差的问题。本研究提出了一种基于大语言模型(LLM)的新型胜任力建模流程。该流程并非简单地自动化孤立的步骤,而是通过将专家实践分解为结构化的计算组件来重构工作流程。具体而言,我们利用LLM从原始文本数据中提取行为和心理描述,并通过基于嵌入的相似性将其映射到预定义的胜任力库。我们进一步引入了一个可学习的参数,自适应地整合不同的信息来源,使模型能够确定行为和心理信号的相对重要性。为了解决长期存在的验证难题,我们开发了一种离线评估程序,可以在不需要额外大规模数据收集的情况下进行系统的模型选择。来自软件外包公司真实实施的经验结果表明,该方法具有很强的预测有效性、跨库一致性和结构鲁棒性。总的来说,我们的框架将胜任力建模从一种很大程度上依赖于定性和专家的实践转变为一种透明、数据驱动和可评估的分析过程。
🔬 方法详解
问题定义:传统胜任力建模方法依赖于人工分析大量的访谈记录,这不仅耗时耗力,而且容易受到专家主观判断的影响,导致结果的随机性和模糊性,同时难以保证结果的可重复性。因此,需要一种更高效、客观、可验证的胜任力建模方法。
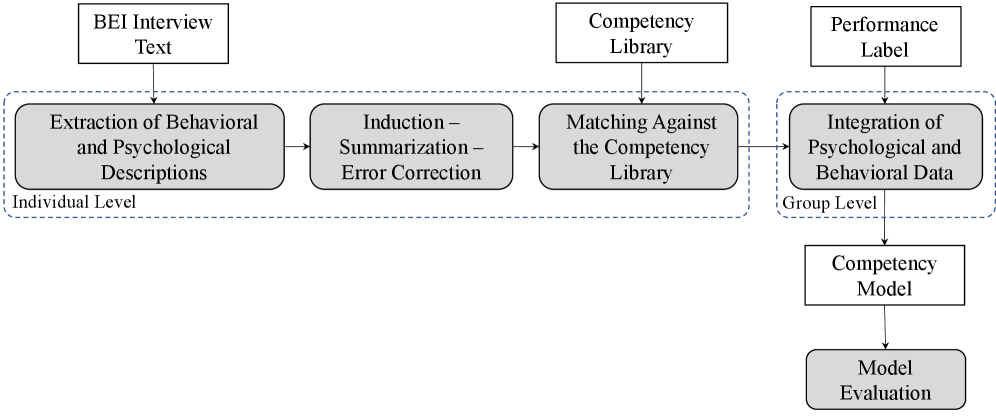
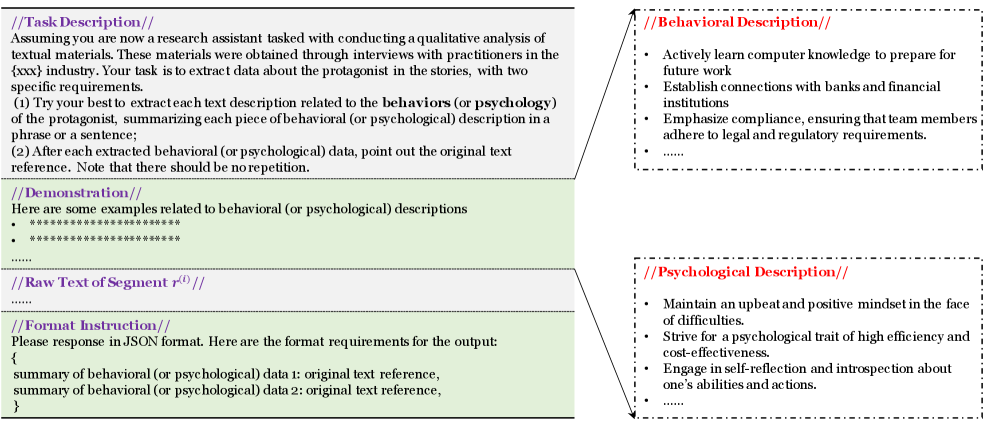
核心思路:本研究的核心思路是利用大语言模型(LLM)强大的文本理解和生成能力,将专家在胜任力建模中的实践经验转化为结构化的计算流程。通过LLM自动提取文本中的行为和心理描述,并将其与预定义的胜任力库进行匹配,从而实现胜任力建模的自动化。
技术框架:该框架主要包含以下几个模块:1) 数据预处理:对原始文本数据进行清洗和格式化;2) 特征提取:利用LLM从文本中提取行为和心理描述;3) 胜任力映射:将提取的特征映射到预定义的胜任力库;4) 信息融合:通过可学习参数自适应地整合不同信息来源;5) 模型评估:采用离线评估程序对模型进行系统评估和选择。
关键创新:该研究的关键创新在于:1) 将胜任力建模流程分解为结构化的计算组件,实现了流程的自动化和可解释性;2) 引入可学习参数,自适应地整合行为和心理信号,提高了模型的准确性;3) 提出离线评估程序,解决了胜任力建模中长期存在的验证难题。
关键设计:在特征提取阶段,使用了预训练的大语言模型,并通过微调使其更适应胜任力建模的任务。在信息融合阶段,使用了一个可学习的权重参数,用于调整行为和心理信号的相对重要性。在模型评估阶段,设计了一种离线评估指标,用于衡量模型的预测有效性、跨库一致性和结构鲁棒性。
🖼️ 关键图片
📊 实验亮点
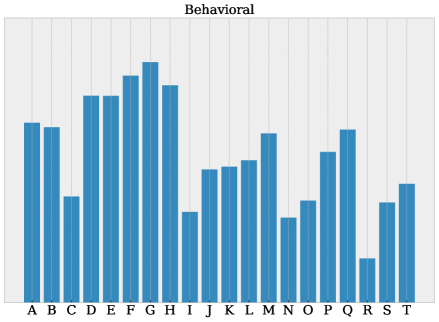
在软件外包公司的真实数据上进行了实验,结果表明该方法具有很强的预测有效性、跨库一致性和结构鲁棒性。该方法能够显著提高胜任力建模的效率和客观性,并为企业提供更科学的人才管理决策支持。
🎯 应用场景
该研究成果可广泛应用于人力资源管理领域,例如人才招聘、绩效评估、职业发展规划等。通过自动化胜任力建模,企业可以更高效、客观地选拔和培养人才,提升组织绩效。此外,该方法还可以应用于教育培训领域,用于评估学生的综合素质和能力。
📄 摘要(原文)
Competency modeling is widely used in human resource management to select, develop, and evaluate talent. However, traditional expert-driven approaches rely heavily on manual analysis of large volumes of interview transcripts, making them costly and prone to randomness, ambiguity, and limited reproducibility. This study proposes a new competency modeling process built on large language models (LLMs). Instead of merely automating isolated steps, we reconstruct the workflow by decomposing expert practices into structured computational components. Specifically, we leverage LLMs to extract behavioral and psychological descriptions from raw textual data and map them to predefined competency libraries through embedding-based similarity. We further introduce a learnable parameter that adaptively integrates different information sources, enabling the model to determine the relative importance of behavioral and psychological signals. To address the long-standing challenge of validation, we develop an offline evaluation procedure that allows systematic model selection without requiring additional large-scale data collection. Empirical results from a real-world implementation in a software outsourcing company demonstrate strong predictive validity, cross-library consistency, and structural robustness. Overall, our framework transforms competency modeling from a largely qualitative and expert-dependent practice into a transparent, data-driven, and evaluable analytical process.