BaziQA-Benchmark: Evaluating Symbolic and Temporally Compositional Reasoning in Large Language Models
作者: Jiangxi Chen, Qian Liu
分类: cs.CL
发布日期: 2026-02-13
💡 一句话要点
提出BaziQA-Benchmark,用于评估大语言模型在符号和时间组合推理方面的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 符号推理 时间推理 基准测试 结构化推理
📋 核心要点
- 现有方法缺乏对大语言模型在复杂符号和时间推理能力上的客观评估。
- BaziQA-Benchmark通过结构化推理协议,约束推理顺序,探究模型推理行为。
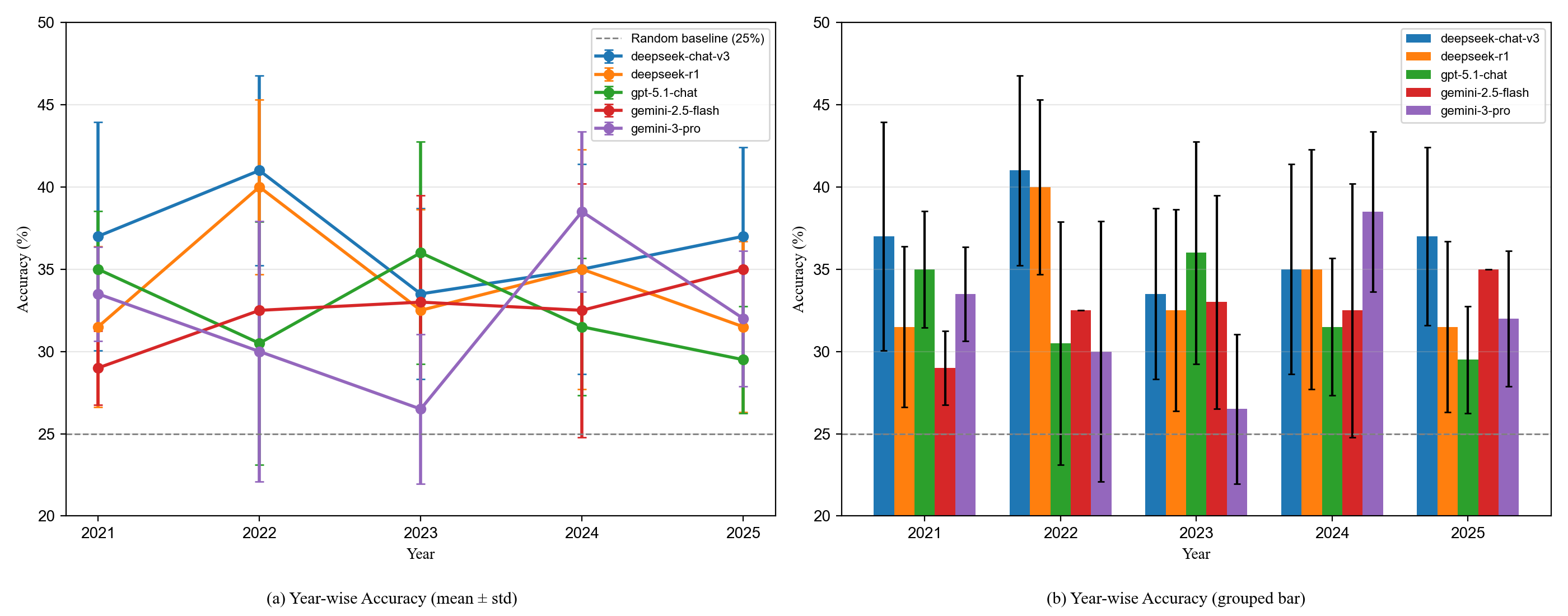
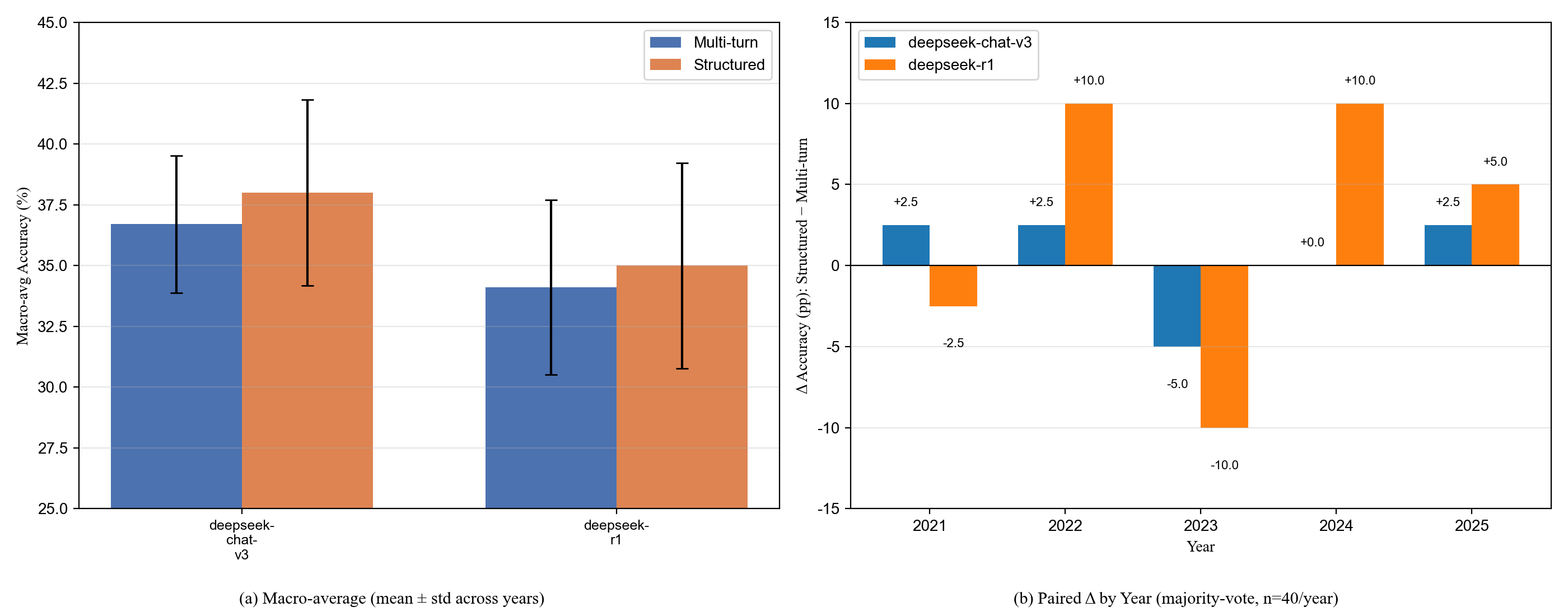
- 实验表明,模型性能远未饱和,对时间组合和推理顺序敏感,存在系统性错误。
📝 摘要(中文)
本文提出了BaziQA-Benchmark,这是一个标准化的基准,用于评估大型语言模型在符号和时间组合推理方面的能力。该基准来源于全球命理师竞赛(2021-2025)中200个专业策划的多项选择题,每个实例都需要对固定的符号图表和交互的时间条件进行结构化推理。与轶事或提示驱动的评估不同,BaziQA-Benchmark能够实现客观评分,并在年份、领域和模型系列之间进行受控比较。我们在多轮设置下评估了当代语言模型,并分析了时间难度、推理领域和推理协议之间的性能变化。为了进一步探究推理行为,我们引入了一种轻量级的结构化推理协议,该协议在不增加领域知识的情况下约束推理顺序。结果表明,模型始终优于随机水平,但远未达到饱和,对时间组合和推理顺序表现出明显的敏感性,并且在精确的时间定位和多条件符号判断方面存在系统性错误。
🔬 方法详解
问题定义:论文旨在解决如何客观、系统地评估大型语言模型在涉及符号和时间组合推理方面的能力。现有方法通常依赖于轶事或提示驱动的评估,缺乏标准化和可控性,难以进行跨模型、跨领域的比较。此外,现有方法难以深入探究模型的推理过程和潜在缺陷。
核心思路:论文的核心思路是构建一个标准化的基准测试集BaziQA-Benchmark,该基准基于专业的命理学问题,这些问题需要模型进行结构化的符号推理和时间推理。同时,引入结构化推理协议,通过约束推理顺序来探究模型的推理行为,而无需引入额外的领域知识。
技术框架:BaziQA-Benchmark包含200个多项选择题,每个问题都基于一个固定的符号图表和交互的时间条件。评估过程采用多轮对话的形式,模型需要根据问题逐步进行推理。为了探究推理行为,论文引入了结构化推理协议,该协议预定义了推理的步骤和顺序,模型需要按照指定的顺序进行推理。评估指标包括准确率等。
关键创新:该论文的关键创新在于:1) 提出了一个标准化的、具有挑战性的基准测试集BaziQA-Benchmark,用于评估大型语言模型在符号和时间组合推理方面的能力。2) 引入了结构化推理协议,可以在不增加领域知识的情况下约束推理顺序,从而更深入地探究模型的推理行为。3) 通过实验分析了模型在不同时间难度、推理领域和推理协议下的性能变化,揭示了模型在时间推理和符号判断方面的局限性。
关键设计:结构化推理协议是关键设计之一,它通过预定义推理步骤,约束模型的推理顺序。具体的推理步骤根据命理学问题的特点进行设计,例如,可能包括首先确定时间条件,然后根据时间条件查询符号图表,最后进行逻辑判断等。该协议的设计目标是在不引入额外领域知识的情况下,尽可能地控制推理过程,从而更准确地评估模型的推理能力。
🖼️ 关键图片
📊 实验亮点
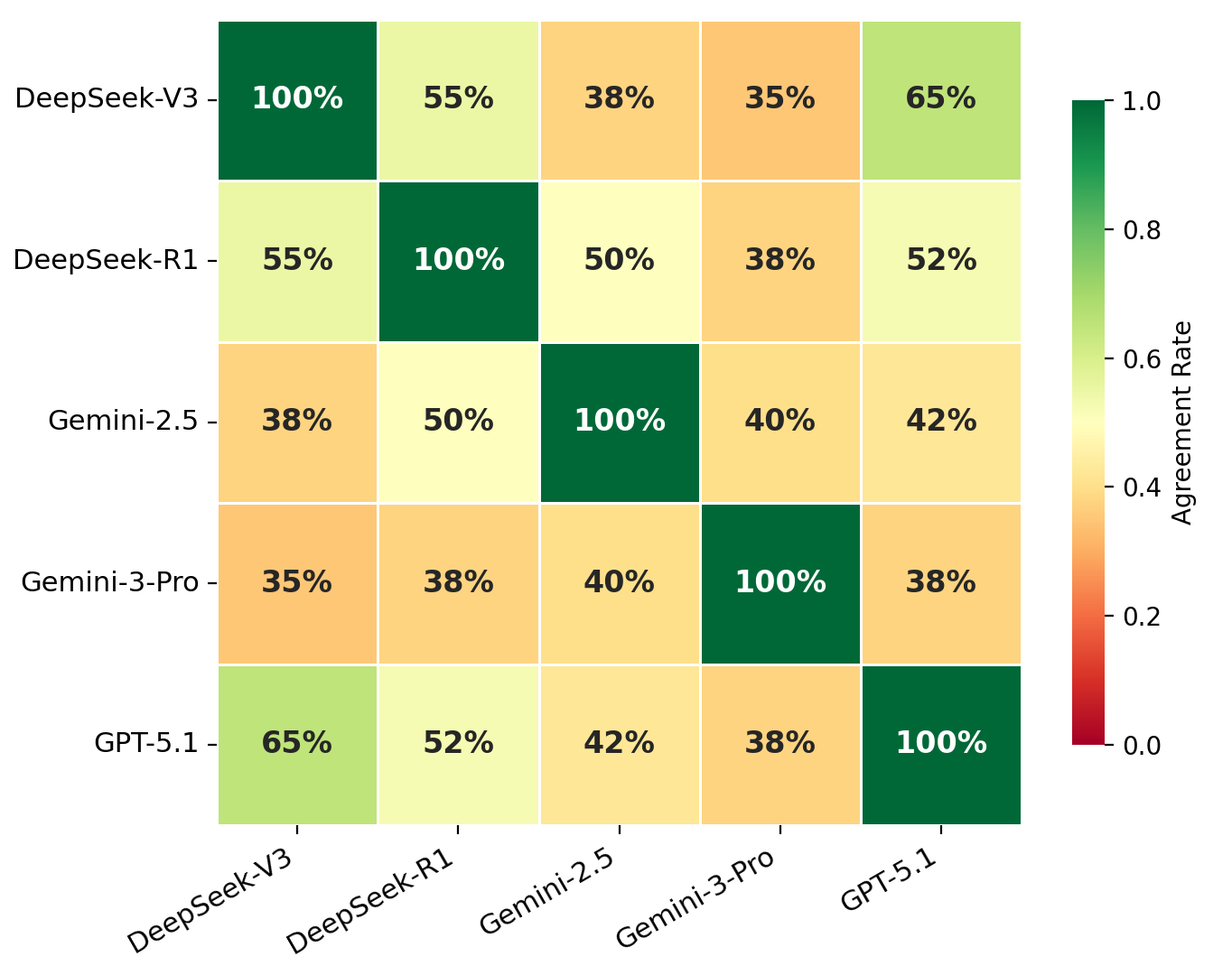
实验结果表明,现有的大语言模型在BaziQA-Benchmark上的表现远未达到饱和,虽然优于随机水平,但对时间组合和推理顺序非常敏感。模型在精确的时间定位和多条件符号判断方面存在系统性错误。结构化推理协议的引入,进一步揭示了模型在推理过程中的局限性。
🎯 应用场景
该研究成果可应用于评估和提升大语言模型在需要复杂推理能力的场景中的表现,例如金融分析、法律咨询、智能客服等领域。通过BaziQA-Benchmark,可以更全面地了解模型的推理能力,并针对性地进行优化,提高模型在实际应用中的可靠性和准确性。
📄 摘要(原文)
We present BaziQA-Benchmark, a standardized benchmark for evaluating symbolic and temporally compositional reasoning in large language models. The benchmark is derived from 200 professionally curated, multiple-choice problems from the Global Fortune-teller Competition (2021--2025), where each instance requires structured inference over a fixed symbolic chart and interacting temporal conditions. Unlike anecdotal or prompt-driven evaluations, BaziQA-Benchmark enables objective scoring and controlled comparison across years, domains, and model families. We evaluate contemporary language models under a multi-turn setting and analyze performance variation across temporal difficulty, reasoning domains, and inference protocols.To further probe reasoning behavior, we introduce a lightweight Structured Reasoning Protocol that constrains inference order without adding domain knowledge. Results show that models consistently outperform chance but remain far from saturation, exhibiting pronounced sensitivity to temporal composition and reasoning order, as well as systematic failures on precise temporal localization and multi-condition symbolic judgments.