MentalBench: A Benchmark for Evaluating Psychiatric Diagnostic Capability of Large Language Models
作者: Hoyun Song, Migyeong Kang, Jisu Shin, Jihyun Kim, Chanbi Park, Hangyeol Yoo, Jihyun An, Alice Oh, Jinyoung Han, KyungTae Lim
分类: cs.CL
发布日期: 2026-02-13
💡 一句话要点
MentalBench:用于评估大型语言模型精神疾病诊断能力的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 精神疾病诊断 基准测试 知识图谱 DSM-5 置信度校准 临床案例 人工智能
📋 核心要点
- 现有精神健康基准依赖社交媒体数据,难以评估基于DSM的精神疾病诊断能力。
- MentalBench构建了MentalKG知识图谱,包含DSM-5诊断标准和鉴别诊断规则,作为评估LLM的逻辑骨干。
- 实验表明,LLM在结构化查询中表现良好,但在区分临床重叠疾病时,诊断置信度校准存在困难。
📝 摘要(中文)
本文介绍MentalBench,一个用于评估大型语言模型(LLMs)在精神疾病诊断决策方面的能力的基准。现有的精神健康基准主要依赖社交媒体数据,限制了它们评估基于DSM的诊断判断的能力。MentalBench的核心是MentalKG,一个由精神科医生构建和验证的知识图谱,它编码了DSM-5的诊断标准和23种精神疾病的鉴别诊断规则。利用MentalKG作为黄金标准的逻辑骨干,我们生成了24,750个合成临床案例,这些案例在信息完整性和诊断复杂性方面系统地变化,从而实现了低噪声和可解释的评估。实验表明,虽然最先进的LLM在探测DSM-5知识的结构化查询中表现良好,但它们在区分临床上重叠的疾病时,难以校准诊断决策的置信度。这些发现揭示了现有基准未捕获的评估差距。
🔬 方法详解
问题定义:现有精神健康评估基准主要依赖社交媒体数据,缺乏对LLM基于DSM-5诊断标准进行精神疾病诊断能力的有效评估。现有方法难以区分临床表现相似的精神疾病,无法准确评估LLM在复杂诊断场景下的置信度校准能力。
核心思路:论文的核心思路是构建一个高质量的、基于DSM-5标准的知识图谱MentalKG,并利用该知识图谱生成系统性的、可控的合成临床案例。通过在这些案例上评估LLM的诊断能力,可以更准确地衡量LLM在精神疾病诊断方面的表现,并发现其在复杂诊断场景下的不足。
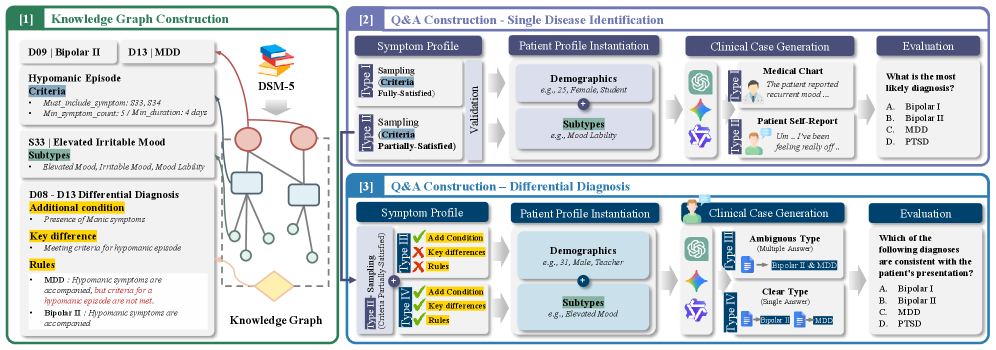
技术框架:MentalBench的整体框架包括以下几个主要模块:1) 构建MentalKG知识图谱,该图谱编码了DSM-5的诊断标准和鉴别诊断规则。2) 基于MentalKG生成合成临床案例,这些案例在信息完整性和诊断复杂性方面系统地变化。3) 使用这些案例评估LLM的诊断能力,并分析其在不同诊断场景下的表现。4) 分析LLM的诊断置信度,并评估其置信度校准能力。
关键创新:该论文的关键创新在于构建了MentalKG知识图谱,并利用该图谱生成合成临床案例。与以往依赖社交媒体数据的基准相比,MentalBench能够更准确地评估LLM基于DSM-5标准的诊断能力。此外,MentalBench还能够评估LLM在区分临床表现相似的精神疾病时的置信度校准能力,这在以往的基准中很少被关注。
关键设计:MentalKG知识图谱的设计关键在于准确地编码DSM-5的诊断标准和鉴别诊断规则。合成临床案例的生成关键在于系统地控制信息完整性和诊断复杂性,以确保评估的全面性和可解释性。评估指标的设计关键在于能够准确地衡量LLM的诊断准确率和置信度校准能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,虽然最先进的LLM在结构化查询中表现良好,但在区分临床上重叠的疾病时,难以校准诊断决策的置信度。这表明现有LLM在复杂诊断场景下的表现仍有待提高,MentalBench能够有效地揭示这些不足,为未来的研究提供指导。
🎯 应用场景
MentalBench可用于评估和改进LLM在精神健康领域的应用,例如辅助诊断、个性化治疗推荐等。通过提高LLM在精神疾病诊断方面的准确性和可靠性,可以帮助精神科医生更好地为患者提供服务,并降低误诊和漏诊的风险。该研究为开发更智能、更可靠的精神健康AI系统奠定了基础。
📄 摘要(原文)
We introduce MentalBench, a benchmark for evaluating psychiatric diagnostic decision-making in large language models (LLMs). Existing mental health benchmarks largely rely on social media data, limiting their ability to assess DSM-grounded diagnostic judgments. At the core of MentalBench is MentalKG, a psychiatrist-built and validated knowledge graph encoding DSM-5 diagnostic criteria and differential diagnostic rules for 23 psychiatric disorders. Using MentalKG as a golden-standard logical backbone, we generate 24,750 synthetic clinical cases that systematically vary in information completeness and diagnostic complexity, enabling low-noise and interpretable evaluation. Our experiments show that while state-of-the-art LLMs perform well on structured queries probing DSM-5 knowledge, they struggle to calibrate confidence in diagnostic decision-making when distinguishing between clinically overlapping disorders. These findings reveal evaluation gaps not captured by existing benchmarks.