Left-right asymmetry in predicting brain activity from LLMs' representations emerges with their formal linguistic competence
作者: Laurent Bonnasse-Gahot, Christophe Pallier
分类: cs.CL, cs.AI, q-bio.NC
发布日期: 2026-02-13
💡 一句话要点
LLM的语言能力与大脑活动预测的左右半球不对称性相关
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 大脑活动预测 左右半球不对称性 形式语言能力 神经语言学
📋 核心要点
- 现有研究表明,LLM的激活与人类大脑活动存在相关性,但LLM训练过程中大脑活动预测的左右半球不对称性出现的原因尚不明确。
- 该研究的核心思想是探究LLM的何种能力与大脑活动预测的左右半球不对称性相关,通过对比LLM在不同任务上的表现与大脑不对称性的演变。
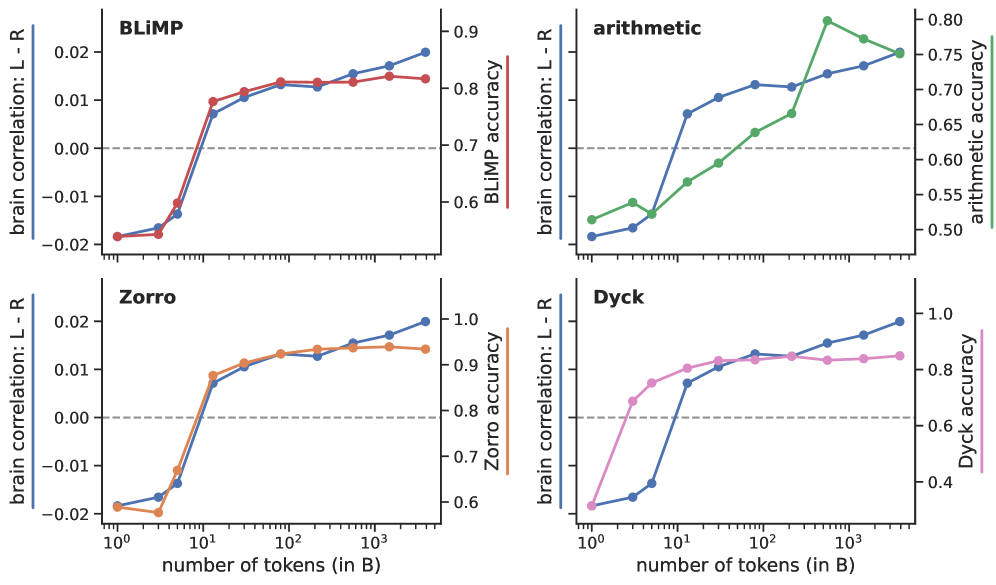
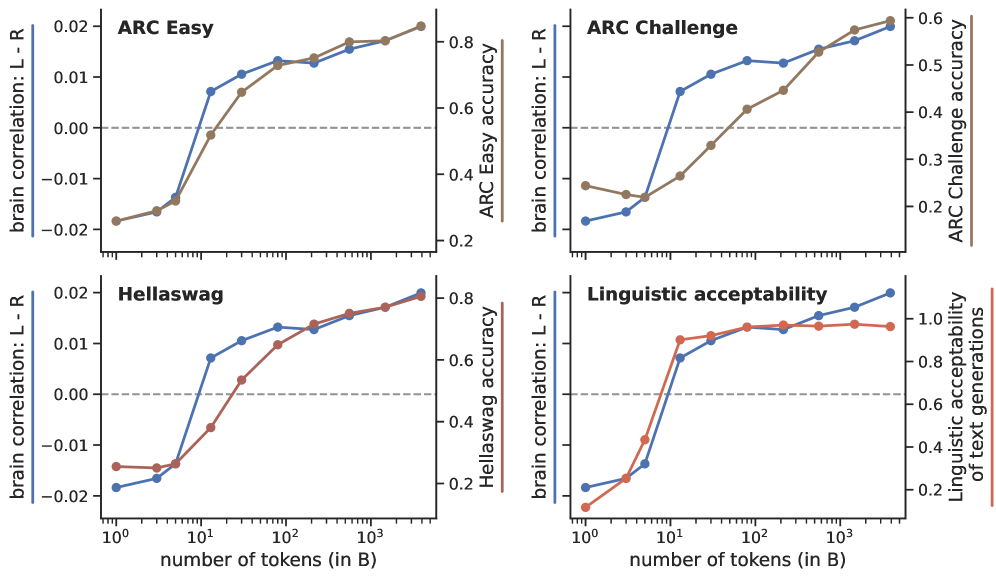
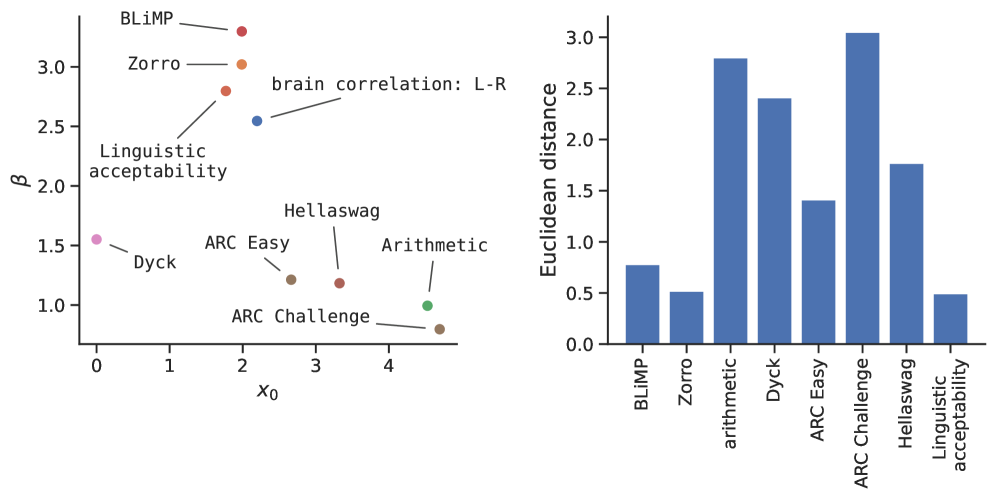
- 实验结果表明,LLM的形式语言能力(如语法判断和文本生成)与大脑活动预测的左右半球不对称性共同出现,而其他能力则不相关。
📝 摘要(中文)
本研究探讨了大型语言模型(LLM)在预测大脑活动时,左右半球不对称性出现的根本原因。研究人员利用不同训练阶段的OLMo-2 7B语言模型和英语参与者的fMRI数据,对比了大脑评分中左右半球不对称性的演变与模型在多个基准测试上的表现。结果表明,这种不对称性与LLM的形式语言能力共同出现,具体体现在模型区分语法正确和错误的句子的能力,以及生成结构良好的文本的能力。相反,这种不对称性与算术、Dyck语言任务或涉及世界知识和推理的文本任务无关。该研究将结果推广到另一个LLM家族(Pythia)和另一种语言(法语)。研究表明,大脑预测的左右不对称性与形式语言能力(语言模式知识)的进步相匹配。
🔬 方法详解
问题定义:现有研究表明LLM的激活与人类大脑活动存在相关性,并且在LLM训练过程中,其内部激活预测大脑活动的能力在左半球的提升比右半球更显著。然而,这种左右半球不对称性出现的根本原因,以及LLM的哪种能力驱动了这种不对称性,尚不清楚。现有方法缺乏对LLM能力与大脑半球不对称性之间关系的深入探究。
核心思路:该研究的核心思路是通过对比LLM在不同训练阶段的表现,以及对应的大脑活动预测的左右半球不对称性,来确定LLM的哪种能力与这种不对称性相关。具体而言,研究人员关注LLM在形式语言能力、算术能力、世界知识和推理能力等方面的表现,并分析这些能力与大脑半球不对称性之间的关系。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择OLMo-2 7B语言模型,并获取其在不同训练阶段的检查点;2) 使用这些检查点对模型进行评估,包括形式语言能力(区分语法正确和错误的句子,生成结构良好的文本)、算术能力、Dyck语言任务、以及涉及世界知识和推理的文本任务;3) 使用fMRI数据,测量英语参与者在处理文本时的脑活动;4) 利用LLM的内部激活预测大脑活动,并计算左右半球的不对称性;5) 分析LLM在不同任务上的表现与大脑半球不对称性之间的相关性。
关键创新:该研究的关键创新在于揭示了LLM的形式语言能力与大脑活动预测的左右半球不对称性之间的关系。以往的研究主要关注LLM的整体性能与大脑活动之间的关系,而忽略了不同类型的能力可能对大脑活动产生不同的影响。该研究通过对比LLM在不同任务上的表现,以及对应的大脑半球不对称性,从而发现了形式语言能力的重要性。
关键设计:该研究的关键设计包括:1) 选择OLMo-2 7B语言模型,并获取其在不同训练阶段的检查点,以便研究LLM能力的演变过程;2) 使用最小对比对来评估LLM区分语法正确和错误的句子的能力;3) 使用fMRI数据,测量英语参与者在处理文本时的脑活动,从而获得大脑活动的客观指标;4) 利用皮尔逊相关系数来衡量LLM的内部激活与大脑活动之间的相关性,并使用左右半球的预测准确率之差来衡量大脑半球的不对称性。
🖼️ 关键图片
📊 实验亮点
研究发现,LLM在区分语法正确和错误的句子,以及生成结构良好的文本方面的能力,与大脑活动预测的左右半球不对称性显著相关。而LLM在算术、Dyck语言任务或涉及世界知识和推理的文本任务上的表现,与这种不对称性无关。该研究还将结果推广到另一个LLM家族(Pythia)和另一种语言(法语),验证了结论的普适性。
🎯 应用场景
该研究成果可应用于神经语言学领域,帮助理解人类大脑处理语言的机制。此外,该研究也为开发更符合人类大脑工作方式的AI模型提供了新的思路,例如,可以针对性地提升AI模型的形式语言能力,从而提高其在自然语言处理任务中的表现。
📄 摘要(原文)
When humans and large language models (LLMs) process the same text, activations in the LLMs correlate with brain activity measured, e.g., with functional magnetic resonance imaging (fMRI). Moreover, it has been shown that, as the training of an LLM progresses, the performance in predicting brain activity from its internal activations improves more in the left hemisphere than in the right one. The aim of the present work is to understand which kind of competence acquired by the LLMs underlies the emergence of this left-right asymmetry. Using the OLMo-2 7B language model at various training checkpoints and fMRI data from English participants, we compare the evolution of the left-right asymmetry in brain scores alongside performance on several benchmarks. We observe that the asymmetry co-emerges with the formal linguistic abilities of the LLM. These abilities are demonstrated in two ways: by the model's capacity to assign a higher probability to an acceptable sentence than to a grammatically unacceptable one within a minimal contrasting pair, or its ability to produce well-formed text. On the opposite, the left-right asymmetry does not correlate with the performance on arithmetic or Dyck language tasks; nor with text-based tasks involving world knowledge and reasoning. We generalize these results to another family of LLMs (Pythia) and another language, namely French. Our observations indicate that the left-right asymmetry in brain predictivity matches the progress in formal linguistic competence (knowledge of linguistic patterns).