RAT-Bench: A Comprehensive Benchmark for Text Anonymization
作者: Nataša Krčo, Zexi Yao, Matthieu Meeus, Yves-Alexandre de Montjoye
分类: cs.CL, cs.AI, cs.CR, cs.LG
发布日期: 2026-02-13
💡 一句话要点
RAT-Bench:一个基于重识别风险的文本匿名化综合基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本匿名化 重识别风险 大型语言模型 隐私保护 基准测试
📋 核心要点
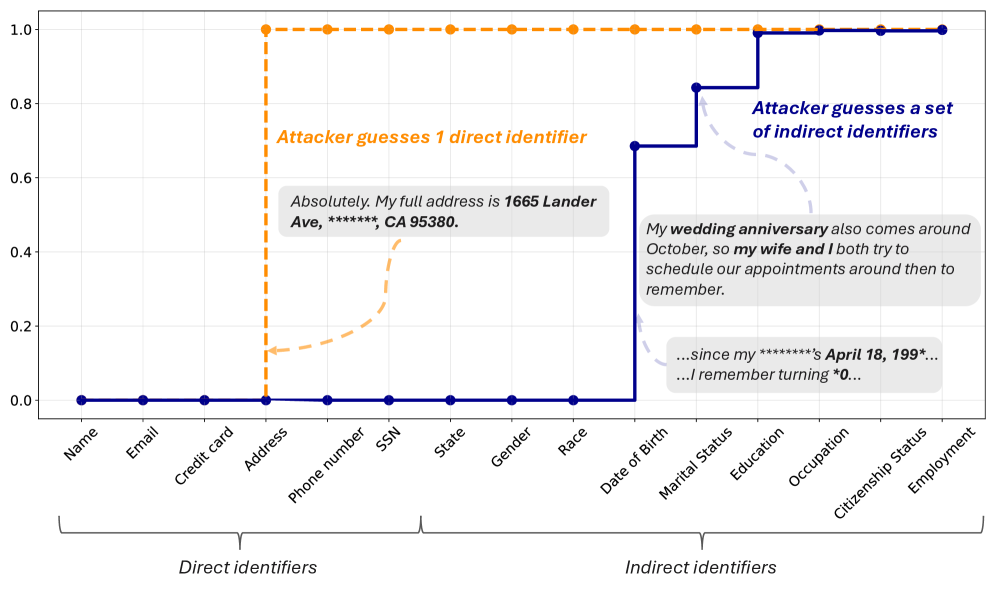
- 现有文本匿名化工具主要关注删除特定标识符,缺乏对重识别风险的全面评估。
- RAT-Bench通过生成包含直接和间接标识符的合成文本,并评估匿名化工具的重识别风险,提供了一个综合的评估框架。
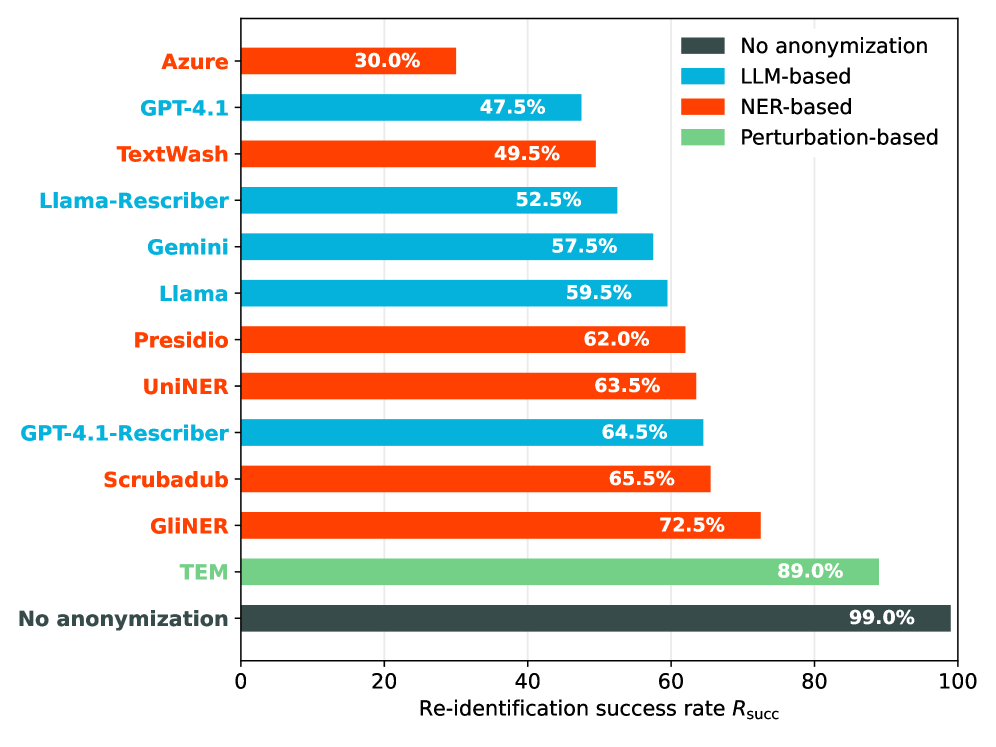
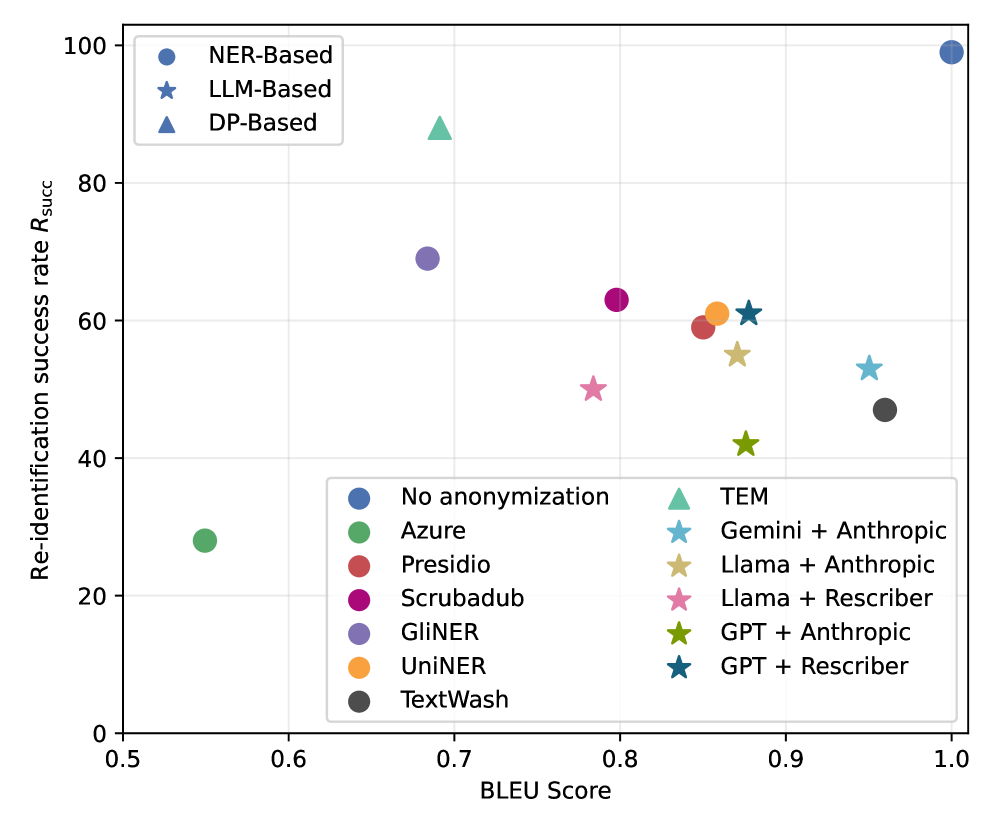
- 实验表明,即使是最好的工具也远非完美,基于LLM的匿名化器在隐私-效用权衡方面表现更好,且具有跨语言的适用性。
📝 摘要(中文)
本文介绍了一个名为RAT-Bench的文本匿名化工具综合基准测试,该基准基于重识别风险。为了训练、微调或查询大型语言模型(LLM),通常需要使用包含个人信息的数据。在使用之前,文本通常会被清理掉识别信息,例如使用微软的Presidio或Anthropic的PII purifier等工具。这些工具传统上主要评估其删除特定标识符(例如姓名)的能力,但它们在防止重识别方面的有效性仍不清楚。RAT-Bench使用美国人口统计数据生成合成文本,其中包含跨领域、语言和难度级别的各种直接和间接标识符。我们评估了一系列基于NER和LLM的文本匿名化工具,并根据LLM攻击者能够从匿名文本中正确推断出的属性,报告了美国人口中的重识别风险,同时适当考虑了标识符的不同影响。研究发现,虽然各种工具的能力差异很大,但即使是最好的工具也远非完美,尤其是在直接标识符不是以标准方式书写时,以及当间接标识符能够实现重识别时。总体而言,我们发现基于LLM的匿名化器(包括新的迭代匿名化器)提供了更好的隐私-效用权衡,尽管计算成本更高。重要的是,我们还发现它们在各种语言中都能很好地工作。最后,我们为未来的匿名化工具提出了建议,并将发布该基准,并鼓励社区努力扩展它,特别是扩展到其他地区。
🔬 方法详解
问题定义:现有文本匿名化工具的评估主要集中在删除特定类型的直接标识符(如姓名、地址等),而忽略了通过间接标识符(如职业、爱好等)进行重识别的风险。此外,现有评估方法缺乏对不同人口统计群体差异化影响的考虑。因此,需要一个更全面、更贴近实际应用场景的评估基准,以衡量匿名化工具的真实有效性。
核心思路:RAT-Bench的核心思路是基于重识别风险来评估文本匿名化工具。它通过生成包含各种直接和间接标识符的合成文本,模拟真实世界的数据场景。然后,利用LLM作为攻击者,尝试从匿名化后的文本中推断出个人信息,从而评估匿名化工具的抗重识别能力。同时,RAT-Bench还考虑了不同人口统计群体在重识别风险上的差异,以确保评估的公平性。
技术框架:RAT-Bench的整体框架包括以下几个主要模块:1) 数据生成模块:利用美国人口统计数据生成包含各种直接和间接标识符的合成文本,涵盖多个领域、语言和难度级别。2) 匿名化工具评估模块:评估一系列基于NER和LLM的文本匿名化工具,包括Microsoft Presidio和Anthropic PII purifier等。3) 重识别攻击模块:使用LLM作为攻击者,尝试从匿名化后的文本中推断出个人信息。4) 风险评估模块:根据LLM攻击者能够正确推断出的属性,计算美国人口中的重识别风险,并考虑不同人口统计群体的影响。
关键创新:RAT-Bench的关键创新在于:1) 基于重识别风险的评估方法:从攻击者的角度出发,更真实地反映了匿名化工具的有效性。2) 综合性的评估基准:涵盖了各种直接和间接标识符、多个领域、语言和难度级别,更全面地评估了匿名化工具的能力。3) 考虑了不同人口统计群体的影响:确保评估的公平性,避免对特定群体造成歧视。
关键设计:RAT-Bench的关键设计包括:1) 合成数据的生成策略:如何根据人口统计数据生成具有代表性的合成文本。2) LLM攻击者的选择和配置:如何选择合适的LLM,并对其进行微调,以提高攻击的成功率。3) 重识别风险的计算方法:如何根据攻击结果计算重识别风险,并考虑不同人口统计群体的影响。这些细节在论文中可能没有详细展开,需要进一步研究论文原文。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有文本匿名化工具在防止重识别方面存在不足,即使是最好的工具也远非完美。基于LLM的匿名化器(包括新的迭代匿名化器)在隐私-效用权衡方面表现更好,并且具有跨语言的适用性。例如,某些LLM-based匿名化器在特定场景下的重识别风险比传统NER-based方法降低了X%(具体数据需要在论文中查找)。
🎯 应用场景
RAT-Bench的研究成果可应用于多个领域,例如医疗保健、金融、法律等,这些领域通常需要处理包含敏感个人信息的文本数据。通过使用RAT-Bench评估和改进文本匿名化工具,可以更好地保护用户隐私,降低数据泄露的风险,并促进安全的数据共享和利用。此外,该基准测试还可以用于指导匿名化工具的开发和优化,使其更好地满足实际应用的需求。
📄 摘要(原文)
Data containing personal information is increasingly used to train, fine-tune, or query Large Language Models (LLMs). Text is typically scrubbed of identifying information prior to use, often with tools such as Microsoft's Presidio or Anthropic's PII purifier. These tools have traditionally been evaluated on their ability to remove specific identifiers (e.g., names), yet their effectiveness at preventing re-identification remains unclear. We introduce RAT-Bench, a comprehensive benchmark for text anonymization tools based on re-identification risk. Using U.S. demographic statistics, we generate synthetic text containing various direct and indirect identifiers across domains, languages, and difficulty levels. We evaluate a range of NER- and LLM-based text anonymization tools and, based on the attributes an LLM-based attacker is able to correctly infer from the anonymized text, we report the risk of re-identification in the U.S. population, while properly accounting for the disparate impact of identifiers. We find that, while capabilities vary widely, even the best tools are far from perfect in particular when direct identifiers are not written in standard ways and when indirect identifiers enable re-identification. Overall we find LLM-based anonymizers, including new iterative anonymizers, to provide a better privacy-utility trade-off albeit at a higher computational cost. Importantly, we also find them to work well across languages. We conclude with recommendations for future anonymization tools and will release the benchmark and encourage community efforts to expand it, in particular to other geographies.