DiffuRank: Effective Document Reranking with Diffusion Language Models
作者: Qi Liu, Kun Ai, Jiaxin Mao, Yanzhao Zhang, Mingxin Li, Dingkun Long, Pengjun Xie, Fengbin Zhu, Ji-Rong Wen
分类: cs.IR, cs.CL
发布日期: 2026-02-13
备注: The code is available at https://github.com/liuqi6777/DiffusionRank
💡 一句话要点
提出DiffuRank,利用扩散语言模型进行高效文档重排序,克服自回归模型的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档重排序 扩散语言模型 信息检索 自然语言处理 大型语言模型
📋 核心要点
- 现有基于LLM的文档重排序方法依赖自回归生成,存在效率低、易出错且难以修正等问题。
- DiffuRank利用扩散语言模型(dLLMs)进行文档重排序,支持更灵活和高效的解码与生成过程。
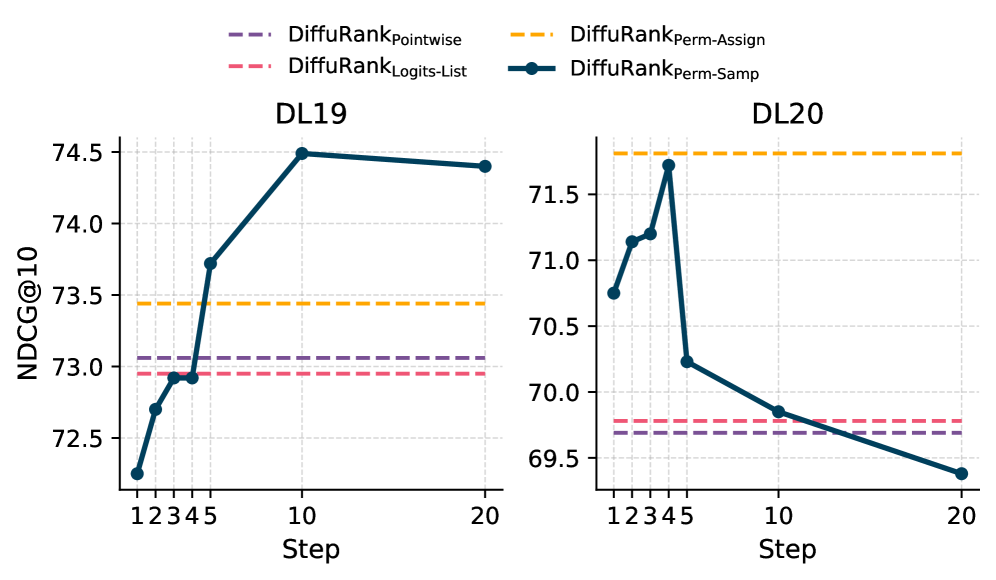
- 实验结果表明,dLLMs在文档重排序任务上达到了与自回归LLMs相当甚至更高的性能。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展为文档重排序带来了新的范式。虽然这种范式更好地利用了LLMs的推理和上下文理解能力,但大多数现有的基于LLM的重排序器依赖于自回归生成,这限制了它们的效率和灵活性。特别是,逐token解码导致高延迟,而固定的从左到右的生成顺序导致早期预测错误传播且难以修改。为了解决这些限制,我们探索了使用扩散语言模型(dLLMs)进行文档重排序,并提出了DiffuRank,一个建立在dLLMs之上的重排序框架。与自回归模型不同,dLLMs支持更灵活的解码和生成过程,不受从左到右顺序的约束,并支持并行解码,这可能提高效率和可控性。具体来说,我们研究了三种基于dLLMs的重排序策略:(1)一种点式方法,使用dLLMs来估计每个查询-文档对的相关性;(2)一种基于logit的列表式方法,提示dLLMs联合评估多个文档的相关性,并直接从模型logits中导出排名列表;(3)一种基于排列的列表式方法,将dLLMs的规范解码过程调整到重排序任务。对于每种方法,我们设计了相应的训练方法,以充分利用dLLMs的优势。我们在多个基准上评估了零样本和微调的重排序性能。实验结果表明,dLLMs实现了与类似模型大小的自回归LLMs相当甚至超过的性能。这些发现证明了基于扩散的语言模型作为文档重排序自回归架构的引人注目的替代方案的前景。
🔬 方法详解
问题定义:论文旨在解决现有基于自回归LLM的文档重排序方法效率低下的问题。自回归模型逐token生成,导致推理速度慢,并且从左到右的生成方式容易累积误差,难以纠正。这些问题限制了LLM在文档重排序中的应用。
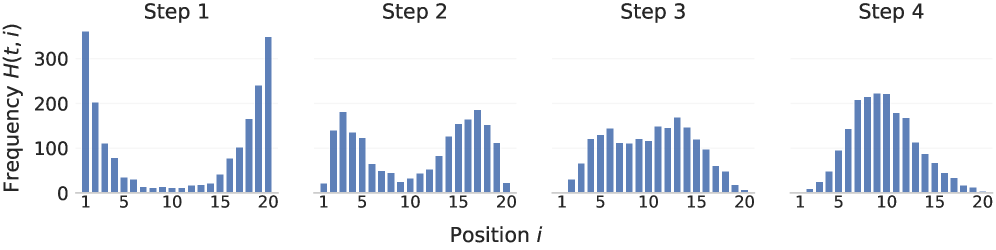
核心思路:论文的核心思路是利用扩散语言模型(dLLMs)的特性来克服自回归模型的局限性。dLLMs支持并行解码,可以显著提高效率。此外,dLLMs的生成过程不依赖于固定的顺序,允许模型在生成过程中进行修正,从而提高准确性。通过将dLLMs应用于文档重排序,可以实现更高效、更准确的排序结果。
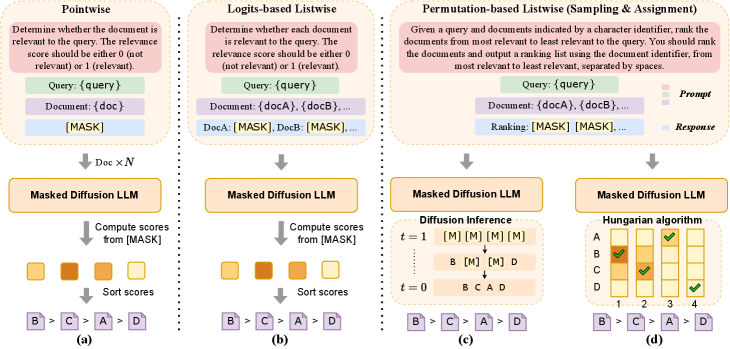
技术框架:DiffuRank框架包含三个主要的重排序策略: 1. 点式方法:使用dLLMs直接评估每个查询-文档对的相关性。 2. 基于logit的列表式方法:提示dLLMs联合评估多个文档的相关性,并从模型logits中导出排名列表。 3. 基于排列的列表式方法:调整dLLMs的规范解码过程以适应重排序任务。
关键创新:该论文的关键创新在于将扩散语言模型(dLLMs)引入到文档重排序任务中。与传统的自回归模型不同,dLLMs具有并行解码和非顺序生成的能力,这使得DiffuRank在效率和准确性方面都具有优势。此外,论文还针对dLLMs的特性设计了三种不同的重排序策略,并提出了相应的训练方法。
关键设计:论文针对三种重排序策略设计了不同的训练方法。对于点式方法,采用回归损失函数来训练dLLMs预测相关性得分。对于基于logit的列表式方法,使用交叉熵损失函数来训练dLLMs生成排名列表。对于基于排列的列表式方法,则采用特定的排列损失函数。此外,论文还探索了不同的prompting策略,以更好地利用dLLMs的上下文理解能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,DiffuRank在多个基准数据集上取得了与自回归LLMs相当甚至更好的性能。例如,在某些数据集上,DiffuRank的性能超过了同等规模的自回归模型,证明了扩散模型在文档重排序任务中的潜力。此外,论文还验证了DiffuRank在零样本设置下的有效性。
🎯 应用场景
DiffuRank具有广泛的应用前景,可应用于搜索引擎、推荐系统、问答系统等领域,提升信息检索的效率和准确性。通过更高效地对文档进行重排序,可以帮助用户更快地找到所需信息,提高用户体验。此外,该研究也为扩散模型在自然语言处理领域的应用提供了新的思路。
📄 摘要(原文)
Recent advances in large language models (LLMs) have inspired new paradigms for document reranking. While this paradigm better exploits the reasoning and contextual understanding capabilities of LLMs, most existing LLM-based rerankers rely on autoregressive generation, which limits their efficiency and flexibility. In particular, token-by-token decoding incurs high latency, while the fixed left-to-right generation order causes early prediction errors to propagate and is difficult to revise. To address these limitations, we explore the use of diffusion language models (dLLMs) for document reranking and propose DiffuRank, a reranking framework built upon dLLMs. Unlike autoregressive models, dLLMs support more flexible decoding and generation processes that are not constrained to a left-to-right order, and enable parallel decoding, which may lead to improved efficiency and controllability. Specifically, we investigate three reranking strategies based on dLLMs: (1) a pointwise approach that uses dLLMs to estimate the relevance of each query-document pair; (2) a logit-based listwise approach that prompts dLLMs to jointly assess the relevance of multiple documents and derives ranking lists directly from model logits; and (3) a permutation-based listwise approach that adapts the canonical decoding process of dLLMs to the reranking tasks. For each approach, we design corresponding training methods to fully exploit the advantages of dLLMs. We evaluate both zero-shot and fine-tuned reranking performance on multiple benchmarks. Experimental results show that dLLMs achieve performance comparable to, and in some cases exceeding, that of autoregressive LLMs with similar model sizes. These findings demonstrate the promise of diffusion-based language models as a compelling alternative to autoregressive architectures for document reranking.