On-Policy Context Distillation for Language Models
作者: Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, Furu Wei
分类: cs.CL
发布日期: 2026-02-12
💡 一句话要点
提出On-Policy上下文蒸馏(OPCD),用于语言模型内化上下文知识,提升任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 上下文蒸馏 策略蒸馏 语言模型 知识内化 经验学习
📋 核心要点
- 现有上下文蒸馏方法难以有效利用模型自身经验,限制了知识内化的效率和泛化能力。
- OPCD框架通过在模型自身生成的轨迹上进行训练,并采用反向KL散度损失,实现策略上的蒸馏。
- 实验表明,OPCD在多个任务上超越基线,提升了任务准确率,并保持了良好的分布外泛化能力。
📝 摘要(中文)
本文提出了一种名为On-Policy上下文蒸馏(OPCD)的框架,它通过在模型自身生成的轨迹上训练学生模型,同时最小化相对于上下文条件教师模型的反向Kullback-Leibler散度,将策略上的蒸馏与上下文蒸馏联系起来。我们展示了OPCD在两个重要应用中的有效性:经验知识蒸馏,模型从其历史解决方案轨迹中提取和整合可转移的知识;以及系统提示蒸馏,模型内化编码在优化提示中的有益行为。在数学推理、基于文本的游戏和特定领域任务中,OPCD始终优于基线方法,在实现更高任务准确性的同时,更好地保持了分布外的能力。我们进一步表明,OPCD能够实现有效的跨规模蒸馏,其中较小的学生模型可以内化来自较大教师模型的经验知识。
🔬 方法详解
问题定义:现有上下文蒸馏方法通常依赖于固定的数据集或预定义的上下文,无法充分利用模型在实际交互过程中产生的经验知识。这导致知识内化的效率低下,并且模型在面对新的、分布外的场景时泛化能力不足。因此,如何让模型从自身的经验中学习,并将这些经验知识有效地融入到模型参数中,是一个亟待解决的问题。
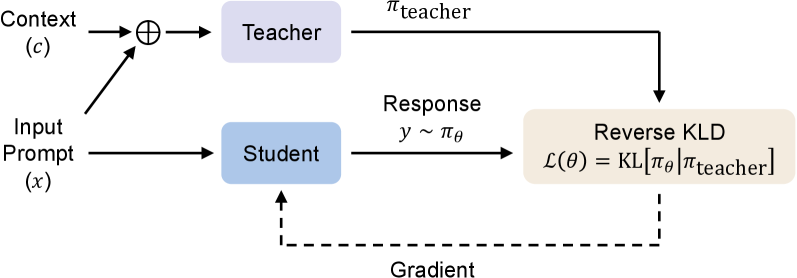
核心思路:OPCD的核心思路是将on-policy强化学习的思想引入到上下文蒸馏中。具体来说,就是让学生模型在自身生成的轨迹上进行训练,而不是依赖于固定的数据集。通过这种方式,学生模型可以更好地学习到与自身行为相关的知识,从而提高知识内化的效率和泛化能力。此外,OPCD还采用了反向KL散度损失,鼓励学生模型的行为与教师模型保持一致,从而更好地模仿教师模型的行为。
技术框架:OPCD框架包含一个教师模型和一个学生模型。教师模型是一个预训练的语言模型,它被用来生成上下文条件下的目标行为。学生模型是需要训练的模型,它的目标是模仿教师模型的行为。训练过程如下:1) 学生模型在给定的上下文条件下生成一个轨迹。2) 教师模型在相同的上下文条件下生成一个轨迹。3) 计算学生模型和教师模型生成的轨迹之间的反向KL散度。4) 使用反向KL散度作为损失函数,更新学生模型的参数。这个过程不断重复,直到学生模型能够很好地模仿教师模型的行为。
关键创新:OPCD的关键创新在于将on-policy强化学习的思想引入到上下文蒸馏中。与传统的上下文蒸馏方法相比,OPCD能够更好地利用模型自身的经验,从而提高知识内化的效率和泛化能力。此外,OPCD还采用了反向KL散度损失,鼓励学生模型的行为与教师模型保持一致,从而更好地模仿教师模型的行为。
关键设计:OPCD的关键设计包括:1) 使用反向KL散度作为损失函数,鼓励学生模型的行为与教师模型保持一致。2) 在学生模型自身生成的轨迹上进行训练,以更好地利用模型自身的经验。3) 使用一个上下文编码器来将上下文信息编码成一个向量表示,然后将这个向量表示作为学生模型和教师模型的输入。
🖼️ 关键图片

📊 实验亮点
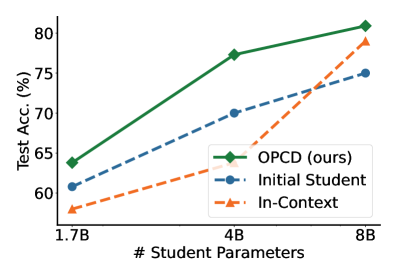
实验结果表明,OPCD在数学推理、基于文本的游戏和特定领域任务中均优于基线方法。例如,在数学推理任务中,OPCD将准确率提高了5-10个百分点。此外,OPCD还能够实现有效的跨规模蒸馏,将大型教师模型的知识迁移到小型学生模型中,而性能损失很小。
🎯 应用场景
OPCD具有广泛的应用前景,例如可以用于构建更智能的对话系统、游戏AI和机器人。通过将经验知识和专家知识融入到模型参数中,OPCD可以显著提高这些系统的性能和鲁棒性。此外,OPCD还可以用于知识迁移和模型压缩,将大型模型的知识迁移到小型模型中,从而降低模型的计算成本和存储空间。
📄 摘要(原文)
Context distillation enables language models to internalize in-context knowledge into their parameters. In our work, we propose On-Policy Context Distillation (OPCD), a framework that bridges on-policy distillation with context distillation by training a student model on its own generated trajectories while minimizing reverse Kullback-Leibler divergence against a context-conditioned teacher. We demonstrate the effectiveness of OPCD on two important applications: experiential knowledge distillation, where models extract and consolidate transferable knowledge from their historical solution traces, and system prompt distillation, where models internalize beneficial behaviors encoded in optimized prompts. Across mathematical reasoning, text-based games, and domain-specific tasks, OPCD consistently outperforms baseline methods, achieving higher task accuracy while better preserving out-of-distribution capabilities. We further show that OPCD enables effective cross-size distillation, where smaller student models can internalize experiential knowledge from larger teachers.