Detecting Overflow in Compressed Token Representations for Retrieval-Augmented Generation
作者: Julia Belikova, Danila Rozhevskii, Dennis Svirin, Konstantin Polev, Alexander Panchenko
分类: cs.CL
发布日期: 2026-02-12
备注: Accepted to EACL 2026 Student Research Workshop. 14 pages, 6 tables, 1 figure
💡 一句话要点
提出检测压缩令牌表示中的溢出以改善生成检索性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长上下文处理 压缩令牌 信息检索 问答系统 生成模型
📋 核心要点
- 现有方法在处理长上下文时面临压缩极限的问题,可能导致任务相关信息的丢失。
- 论文提出了一种新的检测方法,通过分析压缩令牌的饱和统计来识别令牌溢出现象。
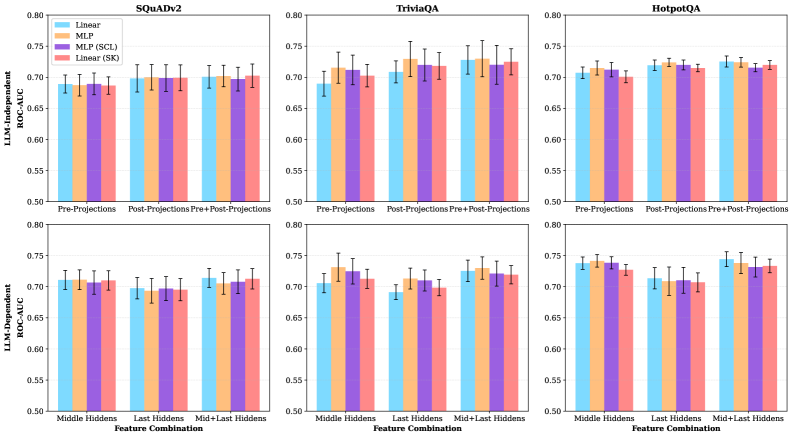
- 实验结果表明,结合查询信息的轻量级探测分类器在多个数据集上实现了0.72的AUC-ROC,显著提升了溢出检测性能。
📝 摘要(中文)
高效的长上下文处理仍然是当代大型语言模型面临的关键挑战,尤其是在资源受限的环境中。软压缩架构通过用较小的学习压缩令牌集替代长令牌序列,承诺扩展有效上下文长度。然而,压缩的极限及其何时开始抹去任务相关内容仍未得到充分探索。本文定义了“令牌溢出”,并提出了一种方法来表征和检测它。在xRAG软压缩设置中,我们发现查询无关的饱和统计数据能够可靠地区分压缩和未压缩的令牌表示,提供了一种识别压缩令牌的实用工具,但其溢出检测能力有限。轻量级探测分类器在HotpotQA、SQuADv2和TriviaQA数据集上平均检测溢出时的AUC-ROC为0.72,表明结合查询信息可以提高检测性能。这些结果从查询无关的诊断进展到查询感知的检测器,使得在LLM之前进行低成本的门控以减轻压缩引起的错误成为可能。
🔬 方法详解
问题定义:本文解决的是在压缩令牌表示中,如何有效检测令牌溢出的问题。现有方法在压缩过程中可能会丢失重要的任务相关信息,导致生成检索性能下降。
核心思路:论文的核心思路是定义“令牌溢出”并提出一种基于饱和统计的检测方法,通过分析压缩表示的特征来识别信息丢失的情况。
技术框架:整体架构包括两个主要模块:首先是压缩令牌的生成,其次是基于查询和上下文的轻量级探测分类器,用于检测令牌溢出。
关键创新:最重要的技术创新在于从查询无关的饱和统计转向查询感知的检测器,这一转变显著提高了溢出检测的准确性。
关键设计:在设计中,使用了轻量级的探测分类器,并在HotpotQA、SQuADv2和TriviaQA数据集上进行了验证,设置了适当的参数以优化AUC-ROC性能。实验显示,结合查询信息的设计显著提升了检测效果。
🖼️ 关键图片
📊 实验亮点
实验结果显示,轻量级探测分类器在HotpotQA、SQuADv2和TriviaQA数据集上实现了平均0.72的AUC-ROC,相较于传统方法有显著提升,表明结合查询信息能够有效改善溢出检测性能。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的信息检索、问答系统和对话生成等。通过有效检测压缩令牌中的溢出,可以提高生成模型在长上下文场景下的准确性和可靠性,具有重要的实际价值和未来影响。
📄 摘要(原文)
Efficient long-context processing remains a crucial challenge for contemporary large language models (LLMs), especially in resource-constrained environments. Soft compression architectures promise to extend effective context length by replacing long token sequences with smaller sets of learned compressed tokens. Yet, the limits of compressibility -- and when compression begins to erase task-relevant content -- remain underexplored. In this paper, we define \emph{token overflow} as a regime in which compressed representations no longer contain sufficient information to answer a given query, and propose a methodology to characterize and detect it. In the xRAG soft-compression setting, we find that query-agnostic saturation statistics reliably separate compressed from uncompressed token representations, providing a practical tool for identifying compressed tokens but showing limited overflow detection capability. Lightweight probing classifiers over both query and context xRAG representations detect overflow with 0.72 AUC-ROC on average on HotpotQA, SQuADv2, and TriviaQA datasets, demonstrating that incorporating query information improves detection performance. These results advance from query-independent diagnostics to query-aware detectors, enabling low-cost pre-LLM gating to mitigate compression-induced errors.