dVoting: Fast Voting for dLLMs
作者: Sicheng Feng, Zigeng Chen, Xinyin Ma, Gongfan Fang, Xinchao Wang
分类: cs.CL, cs.AI
发布日期: 2026-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
dVoting:一种加速扩散大语言模型推理的快速投票技术,无需训练即可提升性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 大语言模型 推理加速 投票算法 一致性分析
📋 核心要点
- 自回归模型推理效率低,限制了并行测试时扩展。扩散模型虽有潜力,但如何有效利用其并行能力仍是挑战。
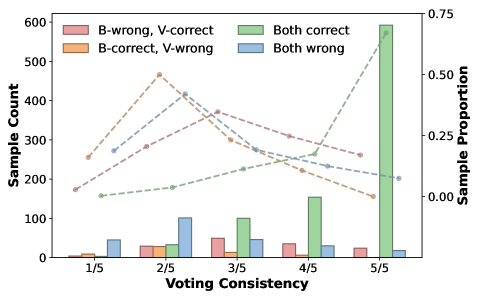
- dVoting通过一致性分析识别不确定tokens,利用扩散模型的任意位置生成能力,迭代地投票优化这些tokens。
- 实验表明,dVoting在多个推理基准测试中显著提升了性能,无需额外训练,仅需少量计算开销。
📝 摘要(中文)
扩散大语言模型(dLLMs)代表了一种超越自回归建模的新范式,它在提供有竞争力的性能的同时,自然地实现了灵活的解码过程。特别地,dLLMs可以并行地在任意位置生成tokens,使其具有并行测试时扩展的巨大潜力,而这在以前受到自回归建模严重低效率的限制。本文介绍了一种快速投票技术dVoting,它无需训练即可提高推理能力,且仅带来可接受的额外计算开销。dVoting的动机是观察到,对于同一prompt的多个样本,token预测保持高度一致,而性能是由表现出跨样本可变性的一小部分tokens决定的。利用dLLMs的任意位置生成能力,dVoting通过采样执行迭代细化,通过一致性分析识别不确定的tokens,通过投票重新生成它们,并重复此过程直到收敛。广泛的评估表明,dVoting在各种基准测试中始终如一地提高了性能。在GSM8K上实现了6.22%-7.66%的增益,在MATH500上实现了4.40%-7.20%的增益,在ARC-C上实现了3.16%-14.84%的增益,在MMLU上实现了4.83%-5.74%的增益。代码已开源。
🔬 方法详解
问题定义:论文旨在解决扩散大语言模型(dLLMs)推理过程中,如何更有效地利用其并行生成能力,从而在不增加过多计算开销的前提下,提升模型的推理性能。现有方法,特别是直接采样,可能因为部分token预测的不确定性而导致最终结果不佳。
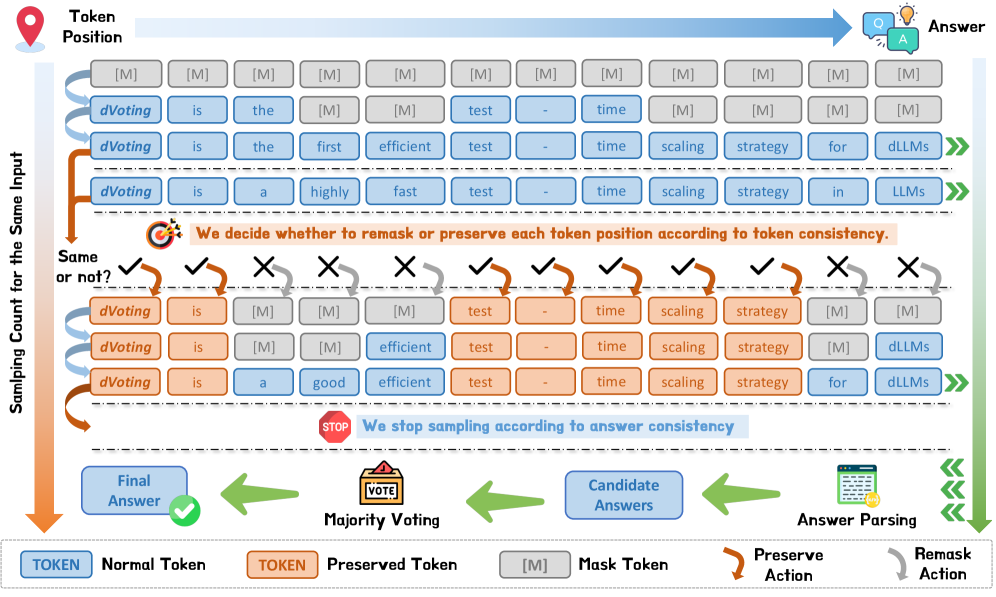
核心思路:论文的核心思路是,通过多次采样,并分析不同样本间token预测的一致性,来识别那些不确定的、对最终结果影响较大的token。然后,利用dLLMs的任意位置生成能力,对这些不确定的token进行重新生成和投票,从而提高其预测的准确性。
技术框架:dVoting的整体流程如下:1) 对给定的prompt进行多次采样,得到多个输出序列;2) 对每个位置的token,计算其在不同样本中的一致性得分;3) 识别一致性得分低的token,即不确定token;4) 对这些不确定token进行重新生成,并进行投票,得到新的token预测;5) 将新的token预测替换原序列中的对应token,重复步骤1-4,直到收敛或达到最大迭代次数。
关键创新:dVoting的关键创新在于,它利用了dLLMs的任意位置生成能力,实现了对不确定token的迭代优化。与传统的自回归模型不同,dVoting不需要从头开始重新生成整个序列,而是可以只针对那些影响结果的关键token进行优化,从而大大提高了效率。此外,一致性分析提供了一种无需ground truth即可识别不确定token的有效方法。
关键设计:dVoting的关键设计包括:1) 一致性得分的计算方法,例如可以使用token在不同样本中出现的频率作为一致性得分;2) 重新生成token时使用的采样策略,例如可以使用不同的温度参数来控制生成的多样性;3) 投票策略,例如可以使用多数投票或加权投票;4) 收敛条件的设定,例如可以设定一个一致性得分的阈值,当所有token的一致性得分都高于该阈值时,停止迭代。
🖼️ 关键图片
📊 实验亮点
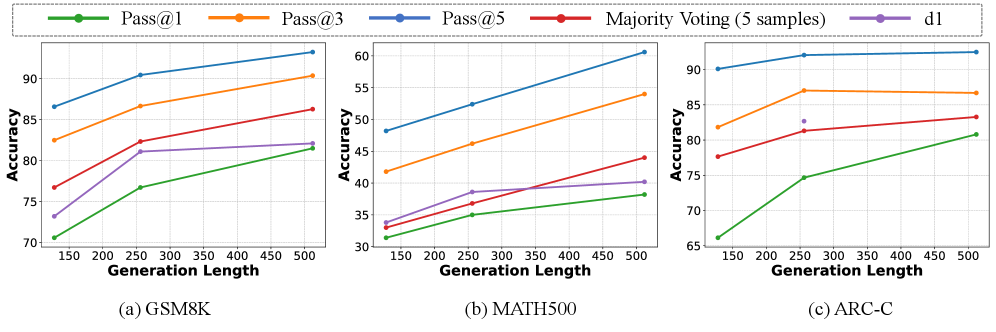
实验结果表明,dVoting在GSM8K、MATH500、ARC-C和MMLU等多个基准测试中均取得了显著的性能提升。例如,在GSM8K上,dVoting实现了6.22%-7.66%的增益;在MATH500上,实现了4.40%-7.20%的增益。这些结果表明,dVoting是一种有效的、通用的推理加速技术。
🎯 应用场景
dVoting可应用于各种需要高性能和高可靠性的大语言模型推理场景,例如智能客服、机器翻译、文本摘要、代码生成等。通过提高模型的推理准确性和效率,dVoting可以提升用户体验,降低计算成本,并推动大语言模型在实际应用中的广泛部署。
📄 摘要(原文)
Diffusion Large Language Models (dLLMs) represent a new paradigm beyond autoregressive modeling, offering competitive performance while naturally enabling a flexible decoding process. Specifically, dLLMs can generate tokens at arbitrary positions in parallel, endowing them with significant potential for parallel test-time scaling, which was previously constrained by severe inefficiency in autoregressive modeling. In this work, we introduce dVoting, a fast voting technique that boosts reasoning capability without training, with only an acceptable extra computational overhead. dVoting is motivated by the observation that, across multiple samples for the same prompt, token predictions remain largely consistent, whereas performance is determined by a small subset of tokens exhibiting cross-sample variability. Leveraging the arbitrary-position generation capability of dLLMs, dVoting performs iterative refinement by sampling, identifying uncertain tokens via consistency analysis, regenerating them through voting, and repeating this process until convergence. Extensive evaluations demonstrate that dVoting consistently improves performance across various benchmarks. It achieves gains of 6.22%-7.66% on GSM8K, 4.40%-7.20% on MATH500, 3.16%-14.84% on ARC-C, and 4.83%-5.74% on MMLU. Our code is available at https://github.com/fscdc/dVoting