P-GenRM: Personalized Generative Reward Model with Test-time User-based Scaling
作者: Pinyi Zhang, Ting-En Lin, Yuchuan Wu, Jingyang Chen, Zongqi Wang, Hua Yang, Ze Xu, Fei Huang, Kai Zhang, Yongbin Li
分类: cs.CL
发布日期: 2026-02-12
备注: Accepted as ICLR 2026 Oral
💡 一句话要点
提出P-GenRM,通过测试时用户自适应缩放实现个性化生成奖励模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化奖励模型 生成模型 用户偏好 测试时自适应 用户原型 强化学习 语言模型
📋 核心要点
- 现有个性化奖励模型难以捕捉用户偏好的多样性和场景依赖性,且泛化能力有限。
- P-GenRM通过生成式奖励模型,将用户偏好转化为结构化评估链,并利用用户原型进行偏好迁移。
- 实验表明,P-GenRM在个性化奖励模型基准上取得了SOTA结果,并在分布外数据上表现出强大的泛化能力。
📝 摘要(中文)
大型语言模型的个性化对齐旨在根据个体用户偏好调整响应,通常通过强化学习实现。一个关键挑战是在开放场景中获得准确的、用户特定的奖励信号。现有的个性化奖励模型面临两个持续的局限性:(1)将多样化的、场景特定的偏好过度简化为一小组固定的评估原则;(2)难以泛化到反馈有限的新用户。为此,我们提出了P-GenRM,这是第一个具有测试时用户自适应缩放的个性化生成奖励模型。P-GenRM将偏好信号转换为结构化的评估链,从而在各种场景中推导出自适应的角色和评分标准。它进一步将用户聚类为用户原型,并引入双粒度缩放机制:在个体层面,自适应地缩放和聚合每个用户的评分方案;在原型层面,整合来自相似用户的偏好。这种设计减轻了推断偏好中的噪声,并通过基于原型的迁移增强了对未见用户的泛化能力。实验结果表明,P-GenRM在广泛使用的个性化奖励模型基准测试中取得了最先进的结果,平均提高了2.31%,并在分布外数据集上表现出强大的泛化能力。值得注意的是,测试时用户自适应缩放提供了额外的3%的提升,表明与测试时可扩展性更强的个性化对齐。
🔬 方法详解
问题定义:现有个性化奖励模型无法充分捕捉用户偏好的多样性,通常将复杂的偏好简化为固定的评估原则。此外,对于反馈数据有限的新用户,模型的泛化能力较差,难以准确预测其偏好。因此,如何构建一个能够适应不同用户和场景,且具有良好泛化能力的个性化奖励模型是一个关键问题。
核心思路:P-GenRM的核心思路是将用户偏好转化为结构化的评估链,从而更细粒度地捕捉用户在不同场景下的偏好。同时,通过用户聚类构建用户原型,利用相似用户的偏好信息来增强对新用户的泛化能力。测试时用户自适应缩放则进一步提升了个性化对齐效果。
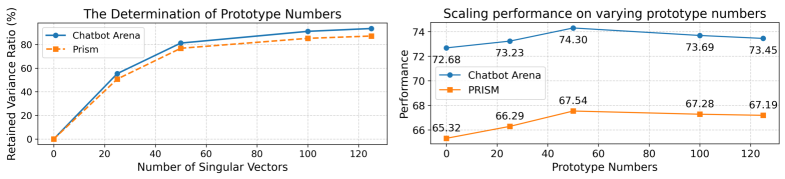
技术框架:P-GenRM的整体框架包括以下几个主要模块:1) 偏好信号转换模块,将用户反馈转化为结构化的评估链,生成自适应的角色和评分标准。2) 用户聚类模块,将用户聚类成不同的用户原型。3) 双粒度缩放模块,在个体层面自适应地缩放和聚合每个用户的评分方案,在原型层面整合来自相似用户的偏好。4) 奖励预测模块,基于上述信息预测奖励值。
关键创新:P-GenRM的关键创新在于以下几点:1) 提出了个性化生成奖励模型,能够生成更细粒度的用户偏好表示。2) 引入了双粒度缩放机制,同时考虑个体用户和用户原型的偏好信息。3) 提出了测试时用户自适应缩放,进一步提升了个性化对齐效果。与现有方法相比,P-GenRM能够更好地捕捉用户偏好的多样性和场景依赖性,并具有更强的泛化能力。
关键设计:P-GenRM的关键设计包括:1) 使用生成模型生成评估链,具体模型结构未知。2) 使用聚类算法(具体算法未知)将用户聚类成不同的用户原型。3) 设计了双粒度缩放机制,具体缩放函数和参数设置未知。4) 损失函数的设计目标是最小化预测奖励与真实奖励之间的差异,具体形式未知。
🖼️ 关键图片


📊 实验亮点
P-GenRM在广泛使用的个性化奖励模型基准测试中取得了最先进的结果,平均提高了2.31%。在分布外数据集上表现出强大的泛化能力。测试时用户自适应缩放提供了额外的3%的性能提升,表明与测试时可扩展性更强的个性化对齐。
🎯 应用场景
P-GenRM可应用于各种需要个性化推荐和内容生成的场景,例如个性化新闻推荐、个性化电影推荐、个性化对话系统等。通过学习用户的个性化偏好,P-GenRM可以生成更符合用户需求的内容,提升用户体验,并带来更高的用户满意度和参与度。未来,该技术有望在智能客服、教育、医疗等领域发挥重要作用。
📄 摘要(原文)
Personalized alignment of large language models seeks to adapt responses to individual user preferences, typically via reinforcement learning. A key challenge is obtaining accurate, user-specific reward signals in open-ended scenarios. Existing personalized reward models face two persistent limitations: (1) oversimplifying diverse, scenario-specific preferences into a small, fixed set of evaluation principles, and (2) struggling with generalization to new users with limited feedback. To this end, we propose P-GenRM, the first Personalized Generative Reward Model with test-time user-based scaling. P-GenRM transforms preference signals into structured evaluation chains that derive adaptive personas and scoring rubrics across various scenarios. It further clusters users into User Prototypes and introduces a dual-granularity scaling mechanism: at the individual level, it adaptively scales and aggregates each user's scoring scheme; at the prototype level, it incorporates preferences from similar users. This design mitigates noise in inferred preferences and enhances generalization to unseen users through prototype-based transfer. Empirical results show that P-GenRM achieves state-of-the-art results on widely-used personalized reward model benchmarks, with an average improvement of 2.31%, and demonstrates strong generalization on an out-of-distribution dataset. Notably, Test-time User-based scaling provides an additional 3% boost, demonstrating stronger personalized alignment with test-time scalability.