DeepSight: An All-in-One LM Safety Toolkit
作者: Bo Zhang, Jiaxuan Guo, Lijun Li, Dongrui Liu, Sujin Chen, Guanxu Chen, Zhijie Zheng, Qihao Lin, Lewen Yan, Chen Qian, Yijin Zhou, Yuyao Wu, Shaoxiong Guo, Tianyi Du, Jingyi Yang, Xuhao Hu, Ziqi Miao, Xiaoya Lu, Jing Shao, Xia Hu
分类: cs.CL, cs.AI, cs.CR, cs.CV
发布日期: 2026-02-12
备注: Technical report, 29 pages, 24 figures
💡 一句话要点
DeepSight:一个一体化的大模型安全工具包,集成评估与诊断。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大模型安全 安全评估 安全诊断 开源工具包 风险评估
📋 核心要点
- 现有大模型安全工具分散,评估侧重外部风险,诊断缺乏内部原因分析,对齐缺少机制解释,导致安全能力受限。
- DeepSight通过集成评估与诊断,统一任务和数据协议,将安全评估从黑盒转化为白盒,提供更深入的安全洞察。
- DeepSight包含DeepSafe和DeepScan两个工具包,支持前沿AI风险评估以及联合安全评估和诊断,是首个开源的此类工具。
📝 摘要(中文)
随着大模型(LMs)的快速发展,其安全性也日益重要。目前,大型语言模型(LLMs)和多模态大型语言模型(MLLMs)的安全工作流程中,评估、诊断和对齐通常由独立的工具处理。具体而言,安全评估只能定位外部行为风险,而无法找出内部根本原因。同时,安全诊断常常偏离具体的风险场景,停留在可解释的层面。这样,安全对齐缺乏对内部机制变化的专门解释,可能降低通用能力。为了系统地解决这些问题,我们提出了一个开源项目DeepSight,以实践一种新的安全评估-诊断集成范式。DeepSight是一个低成本、可复现、高效且高度可扩展的大规模模型安全评估项目,由评估工具包DeepSafe和诊断工具包DeepScan组成。通过统一任务和数据协议,我们构建了两个阶段之间的连接,并将安全评估从黑盒转化为白盒洞察。此外,DeepSight是第一个支持前沿AI风险评估以及联合安全评估和诊断的开源工具包。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)和多模态大型语言模型(MLLMs)安全工作流程中,安全评估、安全诊断和安全对齐通常是分离的。安全评估主要关注外部行为风险的识别,缺乏对模型内部根本原因的探究。安全诊断则往往脱离具体的风险场景,停留在可解释性层面,难以指导实际的安全改进。安全对齐缺乏对模型内部机制变化的解释,可能导致通用能力的下降。因此,需要一个集成化的工具,能够同时进行安全评估和诊断,并提供对模型内部机制的深入理解。
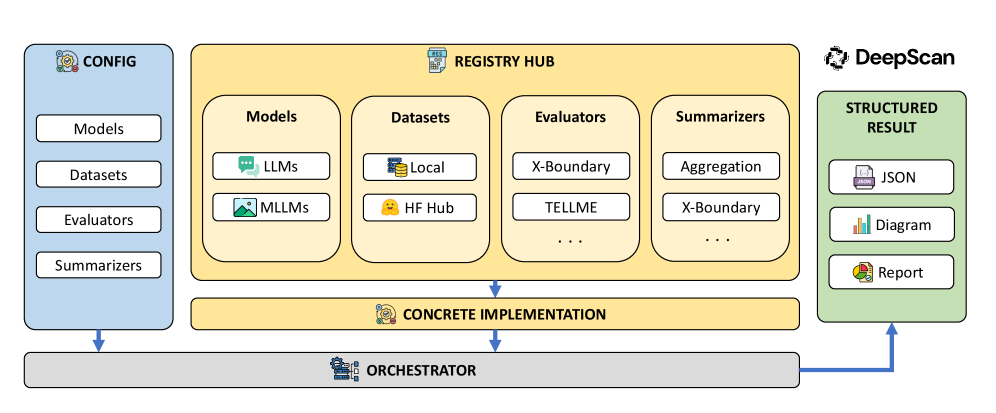
核心思路:DeepSight的核心思路是将安全评估和安全诊断集成到一个统一的框架中,通过统一的任务和数据协议,建立评估和诊断之间的联系。这样,安全评估的结果可以指导安全诊断,而安全诊断的结果可以反过来改进安全评估。通过这种迭代的方式,可以更全面、深入地理解模型的安全风险,并采取有效的安全措施。
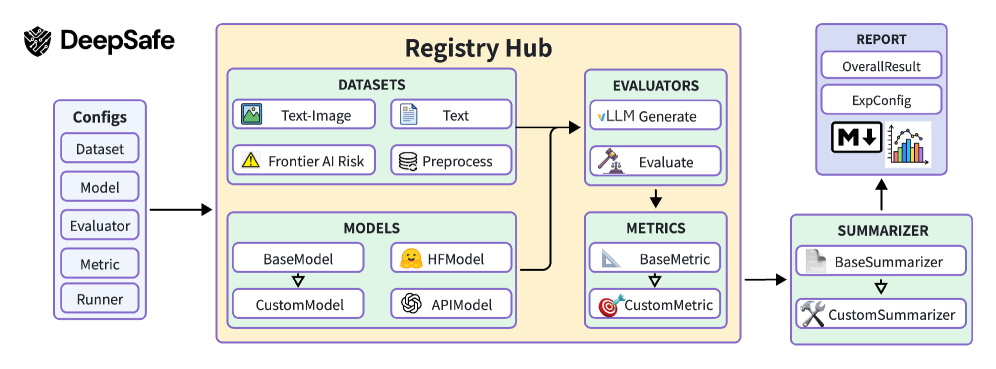
技术框架:DeepSight包含两个主要的工具包:DeepSafe和DeepScan。DeepSafe负责安全评估,用于识别模型存在的外部行为风险。DeepScan负责安全诊断,用于分析模型内部的根本原因。这两个工具包通过统一的任务和数据协议进行连接,实现评估和诊断的协同工作。DeepSight整体流程包括:首先使用DeepSafe进行安全评估,然后使用DeepScan对评估结果进行诊断,最后根据诊断结果进行安全对齐。
关键创新:DeepSight的关键创新在于将安全评估和安全诊断集成到一个统一的框架中,实现了从黑盒到白盒的安全洞察。此外,DeepSight是第一个开源的支持前沿AI风险评估以及联合安全评估和诊断的工具包。通过统一任务和数据协议,DeepSight能够更有效地识别和解决模型存在的安全风险。
关键设计:DeepSight的具体技术细节未知,摘要中没有提及具体的参数设置、损失函数、网络结构等技术细节。但可以推测,DeepSafe可能包含多种安全评估指标和数据集,用于评估模型的安全性。DeepScan可能包含多种诊断方法,用于分析模型内部的激活、梯度等信息,从而找出模型存在的安全漏洞。
🖼️ 关键图片
📊 实验亮点
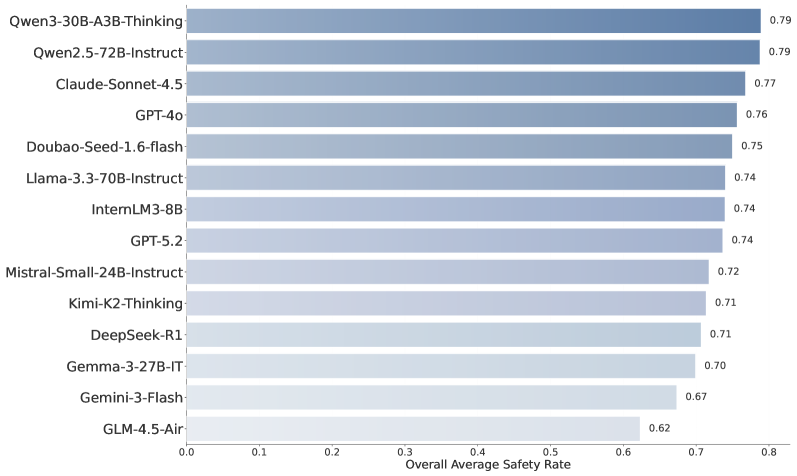
DeepSight是首个开源的支持前沿AI风险评估以及联合安全评估和诊断的工具包,通过集成评估与诊断,实现了从黑盒到白盒的安全洞察。具体性能数据和对比基线未知,但其集成化的设计理念和开源特性,使其具有重要的研究和应用价值。
🎯 应用场景
DeepSight可应用于各种大型语言模型和多模态大型语言模型的安全评估、诊断和对齐。它可以帮助开发者更全面地了解模型的安全风险,并采取有效的安全措施,从而提高模型的安全性和可靠性。该工具包的开源特性,也使得研究人员可以方便地进行安全研究,促进大模型安全领域的发展。
📄 摘要(原文)
As the development of Large Models (LMs) progresses rapidly, their safety is also a priority. In current Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) safety workflow, evaluation, diagnosis, and alignment are often handled by separate tools. Specifically, safety evaluation can only locate external behavioral risks but cannot figure out internal root causes. Meanwhile, safety diagnosis often drifts from concrete risk scenarios and remains at the explainable level. In this way, safety alignment lack dedicated explanations of changes in internal mechanisms, potentially degrading general capabilities. To systematically address these issues, we propose an open-source project, namely DeepSight, to practice a new safety evaluation-diagnosis integrated paradigm. DeepSight is low-cost, reproducible, efficient, and highly scalable large-scale model safety evaluation project consisting of a evaluation toolkit DeepSafe and a diagnosis toolkit DeepScan. By unifying task and data protocols, we build a connection between the two stages and transform safety evaluation from black-box to white-box insight. Besides, DeepSight is the first open source toolkit that support the frontier AI risk evaluation and joint safety evaluation and diagnosis.