Composition-RL: Compose Your Verifiable Prompts for Reinforcement Learning of Large Language Models
作者: Xin Xu, Clive Bai, Kai Yang, Tianhao Chen, Yangkun Chen, Weijie Liu, Hao Chen, Yang Wang, Saiyong Yang, Can Yang
分类: cs.CL
发布日期: 2026-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出Composition-RL,通过组合可验证提示来提升大语言模型强化学习的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 可验证提示 组合推理 课程学习 跨领域学习 奖励函数 提示工程
📋 核心要点
- 现有RLVR方法难以有效利用通过率为1的简单提示,导致有效数据量减少。
- Composition-RL通过自动组合多个问题生成新的可验证提示,增加训练数据的多样性。
- 实验表明,Composition-RL在不同模型尺寸上均能提升推理能力,且跨领域强化学习效果更佳。
📝 摘要(中文)
大规模可验证提示是基于可验证奖励的强化学习(RLVR)成功的关键,但它们包含许多无信息量的例子,并且扩展成本高昂。最近的研究侧重于通过优先考虑通过率为0的困难提示来更好地利用有限的训练数据。然而,随着训练的进行,通过率为1的简单提示也变得越来越普遍,从而降低了有效数据量。为了缓解这个问题,我们提出了Composition-RL,这是一种简单而有效的方法,可以更好地利用针对通过率为1的提示的有限可验证提示。更具体地说,Composition-RL自动将多个问题组合成一个新的可验证问题,并将这些组合提示用于强化学习训练。在从4B到30B的模型尺寸上进行的大量实验表明,Composition-RL始终如一地提高了基于原始数据集训练的强化学习的推理能力。通过逐步增加训练过程中组合深度的课程变体,可以进一步提高性能。此外,Composition-RL通过组合来自不同领域的提示,实现了更有效的跨领域强化学习。代码、数据集和模型可在https://github.com/XinXU-USTC/Composition-RL 获得。
🔬 方法详解
问题定义:现有基于可验证奖励的强化学习(RLVR)方法依赖于大规模的可验证提示,但随着训练的进行,大量简单提示(通过率为1)变得冗余,导致有效训练数据减少,模型难以进一步提升推理能力。
核心思路:Composition-RL的核心思路是通过自动组合多个简单问题,生成更复杂、更具挑战性的新问题,从而更有效地利用这些原本冗余的简单提示。这样可以增加训练数据的多样性,并迫使模型学习更通用的推理策略。
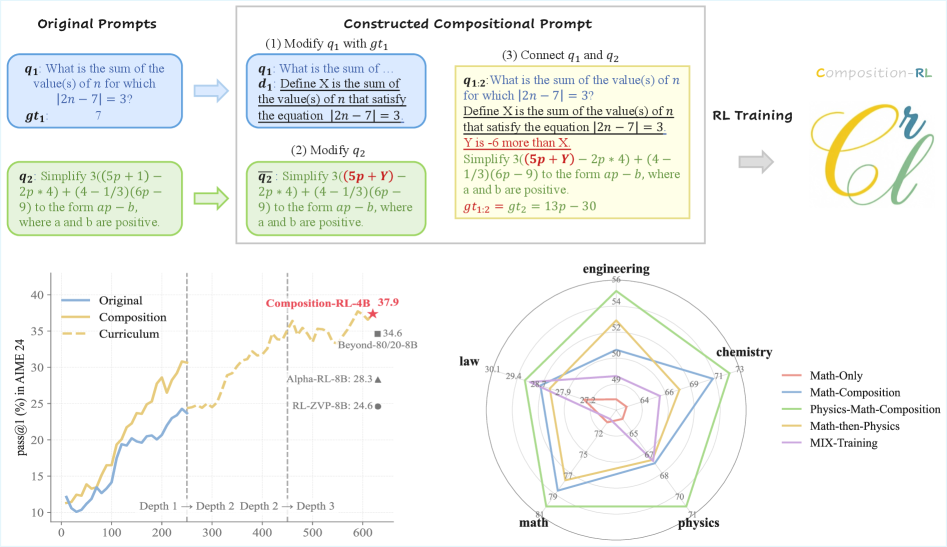
技术框架:Composition-RL的整体流程如下:1. 从现有的可验证提示数据集中,选择多个简单提示(通过率为1)。2. 将这些简单提示组合成一个新的、更复杂的提示。组合方式可以是简单的拼接,也可以是更复杂的逻辑组合。3. 使用这些组合后的提示进行强化学习训练,优化大语言模型的策略。4. (可选) 使用课程学习策略,逐渐增加组合的深度,让模型逐步适应更复杂的问题。
关键创新:Composition-RL的关键创新在于它能够自动生成新的、更具挑战性的训练数据,而无需人工标注。这使得它可以更有效地利用现有的可验证提示数据集,并提升模型的推理能力。与现有方法相比,Composition-RL关注的是如何利用“简单”数据,而不是仅仅关注“困难”数据。
关键设计:组合深度(compositional depth)是Composition-RL的一个关键参数,它决定了每次组合多少个简单提示。论文中还提到了一种课程学习策略,即在训练初期使用较小的组合深度,随着训练的进行逐渐增加组合深度。具体的损失函数和网络结构与基础的RLVR方法相同,重点在于如何生成新的训练数据。
🖼️ 关键图片
📊 实验亮点
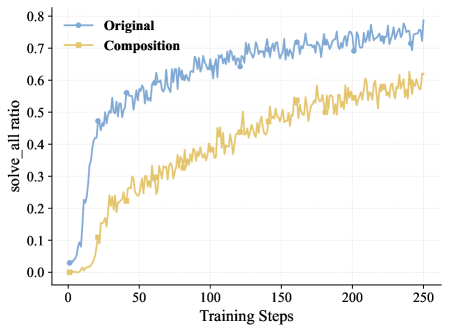
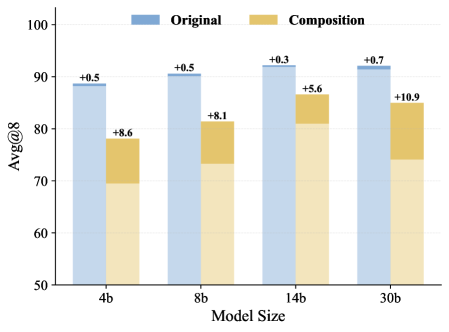
实验结果表明,Composition-RL在4B到30B的不同模型尺寸上均能显著提升推理能力。与在原始数据集上训练的强化学习模型相比,Composition-RL能够取得一致的性能提升。通过引入课程学习策略,逐步增加组合深度,可以进一步提高性能。此外,Composition-RL还展示了在跨领域强化学习方面的有效性。
🎯 应用场景
Composition-RL可应用于各种需要大语言模型进行复杂推理的任务,例如数学问题求解、代码生成、知识图谱推理等。该方法能够提升模型在这些任务上的性能,并降低对大规模人工标注数据的依赖。此外,Composition-RL的跨领域组合能力使其能够应用于更广泛的场景,例如将自然语言处理和计算机视觉任务结合起来。
📄 摘要(原文)
Large-scale verifiable prompts underpin the success of Reinforcement Learning with Verifiable Rewards (RLVR), but they contain many uninformative examples and are costly to expand further. Recent studies focus on better exploiting limited training data by prioritizing hard prompts whose rollout pass rate is 0. However, easy prompts with a pass rate of 1 also become increasingly prevalent as training progresses, thereby reducing the effective data size. To mitigate this, we propose Composition-RL, a simple yet useful approach for better utilizing limited verifiable prompts targeting pass-rate-1 prompts. More specifically, Composition-RL automatically composes multiple problems into a new verifiable question and uses these compositional prompts for RL training. Extensive experiments across model sizes from 4B to 30B show that Composition-RL consistently improves reasoning capability over RL trained on the original dataset. Performance can be further boosted with a curriculum variant of Composition-RL that gradually increases compositional depth over training. Additionally, Composition-RL enables more effective cross-domain RL by composing prompts drawn from different domains. Codes, datasets, and models are available at https://github.com/XinXU-USTC/Composition-RL.