Disentangling Ambiguity from Instability in Large Language Models: A Clinical Text-to-SQL Case Study
作者: Angelo Ziletti, Leonardo D'Ambrosi
分类: cs.CL
发布日期: 2026-02-12
💡 一句话要点
提出CLUES框架,用于临床Text-to-SQL中区分歧义性和不稳定性,提升错误预测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 大型语言模型 不确定性量化 歧义性检测 临床数据 舒尔补 错误预测
📋 核心要点
- 现有Text-to-SQL方法难以区分输入歧义和模型不稳定性,导致无法针对性地进行干预。
- CLUES框架将Text-to-SQL分解为解释和答案两阶段,分别计算歧义性和不稳定性得分。
- 实验表明,CLUES在错误预测方面优于现有方法,并能有效定位需要人工审核的查询。
📝 摘要(中文)
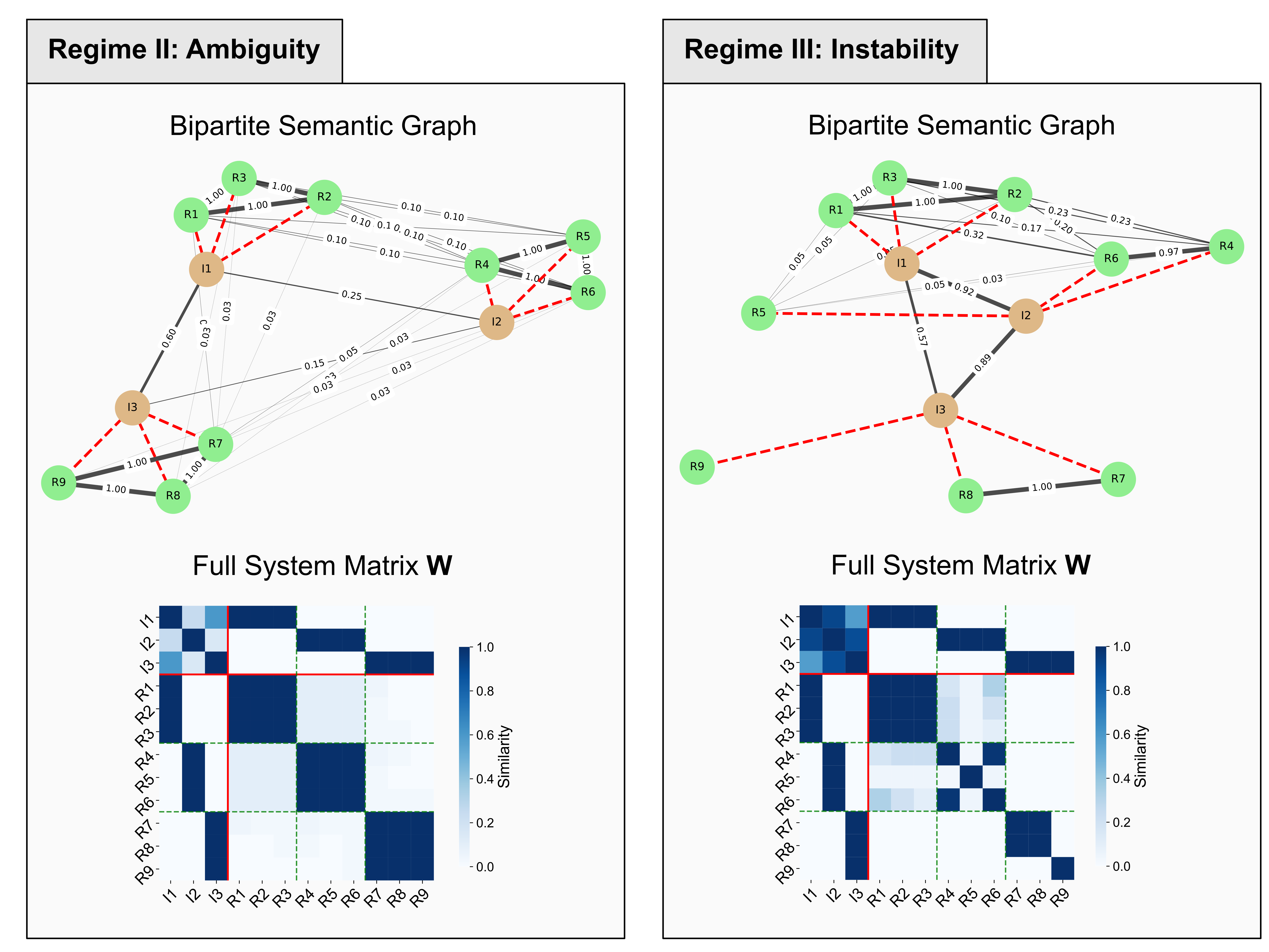
本文针对临床Text-to-SQL中大型语言模型部署时,输出多样性的两种不同原因:(i)应触发澄清的输入歧义,以及(ii)应触发人工审核的模型不稳定性,提出了CLUES框架。CLUES将Text-to-SQL建模为两阶段过程(解释 --> 答案),并将语义不确定性分解为歧义性得分和不稳定性得分。不稳定性得分通过二分语义图矩阵的舒尔补计算。在AmbigQA/SituatedQA(黄金解释)和临床Text-to-SQL基准(已知解释)上,CLUES改进了优于最先进的内核语言熵的失败预测。在部署设置中,它保持了竞争力,同时提供了单分无法提供的诊断分解。由此产生的不确定性状态映射到有针对性的干预措施——针对歧义的查询细化,针对不稳定性的模型改进。高歧义/高不稳定状态包含51%的错误,同时覆盖25%的查询,从而实现高效的分类。
🔬 方法详解
问题定义:在临床Text-to-SQL任务中,大型语言模型(LLM)的输出多样性可能源于两种根本不同的原因:一是输入查询本身存在歧义,需要进一步澄清;二是模型本身存在不稳定性,导致即使输入清晰,输出也可能不一致。现有方法通常无法区分这两种情况,导致无法采取针对性的干预措施,例如,对于歧义性查询,应该进行查询细化,而对于不稳定性查询,则应该进行模型改进或人工审核。
核心思路:CLUES框架的核心思路是将Text-to-SQL任务分解为两个阶段:首先,LLM将自然语言查询解释为一系列可能的语义表示(interpretations);然后,基于这些语义表示生成最终的SQL查询(answers)。通过分析这两个阶段的不确定性,可以将整体的语义不确定性分解为歧义性得分和不稳定性得分。歧义性得分反映了输入查询本身的不确定性,而不稳定性得分反映了模型在将语义表示转化为SQL查询时的不确定性。
技术框架:CLUES框架包含以下主要模块:1. 解释生成模块:使用LLM生成多个可能的语义解释。2. 答案生成模块:基于每个语义解释,生成对应的SQL查询。3. 歧义性评估模块:评估不同语义解释之间的差异,计算歧义性得分。4. 不稳定性评估模块:评估相同语义解释生成不同SQL查询的一致性,计算不稳定性得分。5. 决策模块:基于歧义性得分和不稳定性得分,决定采取何种干预措施(查询细化、模型改进或人工审核)。
关键创新:CLUES框架的关键创新在于将语义不确定性分解为歧义性和不稳定性两个维度,从而能够更精确地诊断LLM的错误原因。此外,使用舒尔补计算不稳定性得分是一种新颖的方法,能够有效地捕捉模型在语义表示到SQL查询转换过程中的不确定性。
关键设计:不稳定性得分的计算是基于二分语义图矩阵的舒尔补。具体来说,构建一个二分图,其中一侧节点表示语义解释,另一侧节点表示SQL查询。如果某个语义解释可以生成某个SQL查询,则在对应的节点之间建立连接。然后,计算该二分图的邻接矩阵,并使用舒尔补计算不稳定性得分。这种方法能够有效地捕捉模型在将语义表示转化为SQL查询时的不确定性。
🖼️ 关键图片
📊 实验亮点
在AmbigQA/SituatedQA和临床Text-to-SQL基准测试中,CLUES框架在错误预测方面优于最先进的Kernel Language Entropy方法。在高歧义/高不稳定状态下,CLUES能够覆盖51%的错误,同时仅覆盖25%的查询,从而实现高效的错误分类和人工审核。
🎯 应用场景
CLUES框架可应用于各种需要将自然语言转换为结构化查询的场景,例如临床数据查询、客户服务机器人、智能助手等。通过区分歧义性和不稳定性,可以提高查询的准确性和可靠性,减少人工干预的需求,并为模型改进提供有价值的诊断信息。
📄 摘要(原文)
Deploying large language models for clinical Text-to-SQL requires distinguishing two qualitatively different causes of output diversity: (i) input ambiguity that should trigger clarification, and (ii) model instability that should trigger human review. We propose CLUES, a framework that models Text-to-SQL as a two-stage process (interpretations --> answers) and decomposes semantic uncertainty into an ambiguity score and an instability score. The instability score is computed via the Schur complement of a bipartite semantic graph matrix. Across AmbigQA/SituatedQA (gold interpretations) and a clinical Text-to-SQL benchmark (known interpretations), CLUES improves failure prediction over state-of-the-art Kernel Language Entropy. In deployment settings, it remains competitive while providing a diagnostic decomposition unavailable from a single score. The resulting uncertainty regimes map to targeted interventions - query refinement for ambiguity, model improvement for instability. The high-ambiguity/high-instability regime contains 51% of errors while covering 25% of queries, enabling efficient triage.