Scaling Model and Data for Multilingual Machine Translation with Open Large Language Models
作者: Yuzhe Shang, Pengzhi Gao, Wei Liu, Jian Luan, Jinsong Su
分类: cs.CL
发布日期: 2026-02-12
💡 一句话要点
MiLMMT-46:通过模型和数据扩展,利用开放大语言模型提升多语言机器翻译性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言机器翻译 开放大语言模型 模型扩展 数据扩展 持续预训练 指令微调 Gemma模型 MiLMMT-46
📋 核心要点
- 现有方法在多语言机器翻译中面临着模型规模和数据利用效率的挑战,难以充分发挥开放大语言模型的潜力。
- 论文提出通过持续预训练和指令微调,有效扩展模型规模和数据规模,从而提升开放大语言模型在多语言机器翻译中的性能。
- 实验结果表明,MiLMMT-46在46种语言上超越了现有SOTA模型,并与Google Translate等专有系统展现出竞争优势。
📝 摘要(中文)
本文研究了开放大语言模型(LLMs)在多语言机器翻译(MT)中的应用,涵盖多种语言。通过持续预训练和指令微调,研究了模型扩展和数据扩展对开放LLMs适应多语言MT的影响。基于Gemma模型系列,我们开发了MiLMMT-46,它在46种语言中实现了顶级的多语言翻译性能。大量实验表明,MiLMMT-46始终优于最新的state-of-the-art(SOTA)模型,包括Seed-X、HY-MT-1.5和TranslateGemma,并且与强大的专有系统(如Google Translate和Gemini 3 Pro)相比,实现了具有竞争力的性能。
🔬 方法详解
问题定义:论文旨在解决多语言机器翻译任务中,如何有效利用开放大语言模型(LLMs)提升翻译质量的问题。现有方法通常难以充分利用LLMs的潜力,尤其是在模型和数据规模扩展方面存在瓶颈,导致翻译性能受限。
核心思路:论文的核心思路是通过持续预训练和指令微调,将开放LLMs适配到多语言机器翻译任务中。通过扩大模型规模和数据规模,使模型能够更好地学习和理解不同语言之间的复杂关系,从而提升翻译的准确性和流畅性。
技术框架:论文的技术框架主要包括两个阶段:持续预训练和指令微调。首先,在大量的多语言数据上对开放LLMs进行持续预训练,使其具备初步的多语言理解和生成能力。然后,利用指令微调技术,针对机器翻译任务进行优化,使模型能够更好地遵循指令,生成高质量的翻译结果。
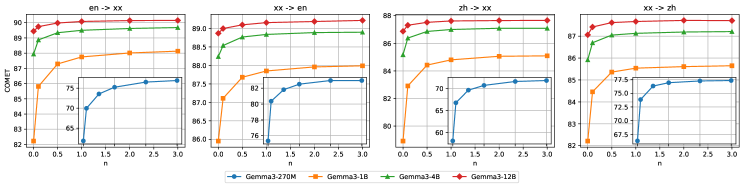
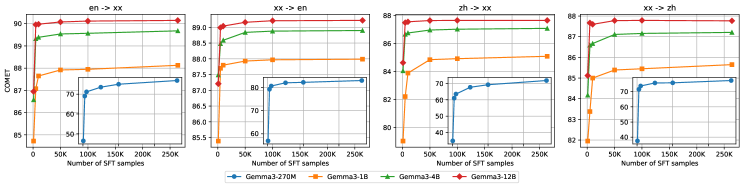
关键创新:论文的关键创新在于探索了模型和数据扩展对开放LLMs在多语言机器翻译任务中的影响。通过系统性的实验,验证了扩大模型规模和数据规模能够显著提升翻译性能。此外,MiLMMT-46模型的提出,证明了通过有效的方法,开放LLMs可以在多语言机器翻译领域达到甚至超越专有系统的性能。
关键设计:论文基于Gemma模型家族,构建了MiLMMT-46模型。在持续预训练阶段,使用了大规模的多语言语料库。在指令微调阶段,设计了特定的指令模板,并使用了高质量的翻译数据。具体的参数设置和损失函数选择未知,但整体目标是使模型能够更好地理解和生成不同语言的翻译。
🖼️ 关键图片

📊 实验亮点
MiLMMT-46在46种语言上实现了顶级的多语言翻译性能,显著优于Seed-X、HY-MT-1.5和TranslateGemma等现有SOTA模型。同时,MiLMMT-46与Google Translate和Gemini 3 Pro等强大的专有系统相比,也展现出具有竞争力的性能,证明了开放LLMs在多语言机器翻译领域的巨大潜力。
🎯 应用场景
该研究成果可广泛应用于机器翻译服务、跨语言信息检索、多语言对话系统等领域。通过提升多语言机器翻译的质量,可以促进不同语言文化之间的交流与合作,降低语言障碍,具有重要的社会和经济价值。未来,该技术有望进一步应用于低资源语言的翻译,实现更广泛的语言覆盖。
📄 摘要(原文)
Open large language models (LLMs) have demonstrated improving multilingual capabilities in recent years. In this paper, we present a study of open LLMs for multilingual machine translation (MT) across a range of languages, and investigate the effects of model scaling and data scaling when adapting open LLMs to multilingual MT through continual pretraining and instruction finetuning. Based on the Gemma3 model family, we develop MiLMMT-46, which achieves top-tier multilingual translation performance across 46 languages. Extensive experiments show that MiLMMT-46 consistently outperforms recent state-of-the-art (SOTA) models, including Seed-X, HY-MT-1.5, and TranslateGemma, and achieves competitive performance with strong proprietary systems such as Google Translate and Gemini 3 Pro.