Do Large Language Models Adapt to Language Variation across Socioeconomic Status?
作者: Elisa Bassignana, Mike Zhang, Dirk Hovy, Amanda Cercas Curry
分类: cs.CL
发布日期: 2026-02-12
💡 一句话要点
研究表明大型语言模型在不同社会经济地位人群的语言变体适应性方面存在不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会经济地位 语言变体 社会语言学 风格适应性
📋 核心要点
- 现有大型语言模型在适应不同社会经济地位人群的语言风格方面存在不足,可能加剧社会不平等。
- 该研究通过分析LLM对不同SES群体社交媒体文本的补全,评估其语言风格适应性。
- 实验结果表明LLM在SES风格适应性方面表现不佳,倾向于模仿较高SES风格,存在放大语言等级的风险。
📝 摘要(中文)
人类会根据交流对象调整语言风格。然而,大型语言模型(LLM)在多大程度上适应不同的社会环境在很大程度上是未知的。随着这些模型越来越多地调解人际交流,它们若不能适应多样化的风格,可能会使刻板印象永久化,并将那些语言规范与模型不太匹配的群体边缘化,从而加剧社会分层。本研究探讨了LLM融入不同社会经济地位(SES)群体的社交媒体交流的程度。我们从Reddit和YouTube收集了一个新的数据集,并按SES进行分层。我们使用该语料库中的不完整文本提示四个LLM,并将LLM生成的补全文本与原始文本在94个社会语言学指标(包括句法、修辞和词汇特征)上进行比较。LLM在SES方面的风格调整程度很小,通常导致近似或漫画化,并且更倾向于模仿较高SES的风格。我们的发现(1)表明LLM有放大语言等级制度的风险,(2)质疑了它们在基于代理的社会模拟、调查实验以及任何依赖语言风格作为社会信号的研究中的有效性。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)是否能够适应不同社会经济地位(SES)人群的语言变体。现有方法缺乏对LLM在社会语言学层面的适应性评估,可能导致模型在实际应用中加剧社会不平等,例如在人机交互、社交模拟等场景中。
核心思路:核心思路是通过对比LLM生成的文本与不同SES人群的原始文本,分析LLM在句法、修辞和词汇等社会语言学特征上的差异,从而评估其语言风格适应性。这种对比分析能够揭示LLM是否能够准确捕捉不同SES群体的语言习惯,以及是否存在偏见或刻板印象。
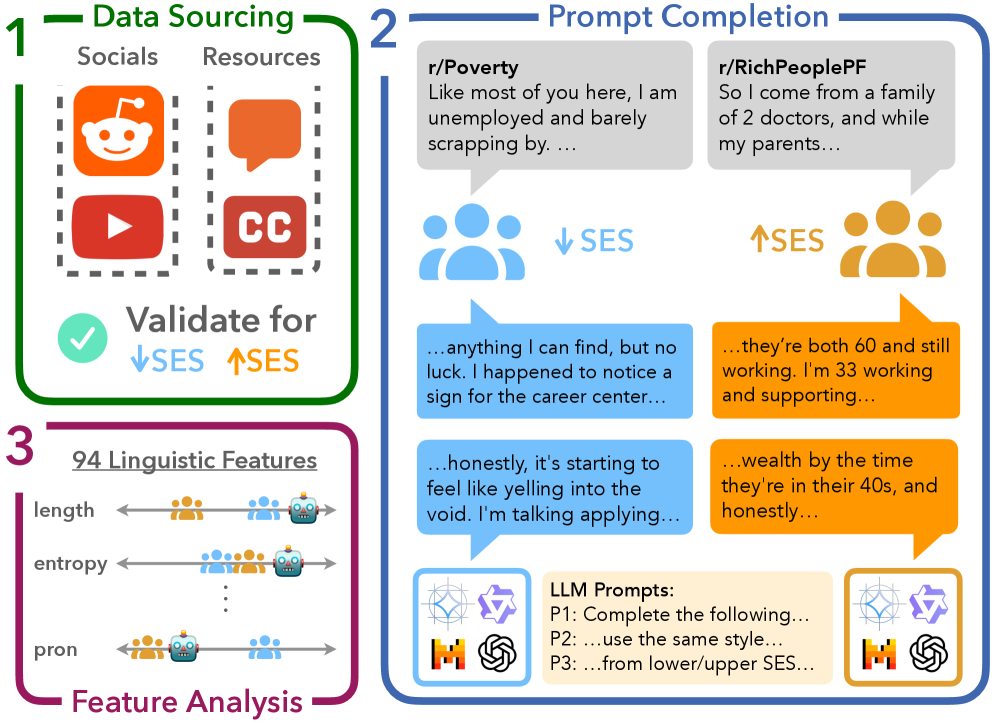
技术框架:整体框架包括以下几个步骤:1) 构建数据集:从Reddit和YouTube收集数据,并按SES进行分层;2) 文本补全:使用收集到的不完整文本提示四个LLM(具体模型未知)进行文本补全;3) 特征提取:提取LLM生成文本和原始文本的94个社会语言学特征;4) 对比分析:对比LLM生成文本和原始文本在这些特征上的差异,评估LLM的适应性。
关键创新:该研究的关键创新在于其对LLM社会语言学适应性的系统性评估。以往的研究主要关注LLM在语法、语义等方面的表现,而忽略了其在社会语言学层面的影响。该研究通过构建新的数据集和设计详细的评估指标,填补了这一空白,为LLM的社会影响研究提供了新的视角。
关键设计:关键设计包括:1) 数据集构建:确保数据集在SES上的代表性和平衡性;2) 特征选择:选择具有代表性的社会语言学特征,例如句法复杂度、修辞风格、词汇使用等;3) 评估指标:设计合适的评估指标来量化LLM生成文本与原始文本之间的差异。具体的参数设置、损失函数和网络结构等技术细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
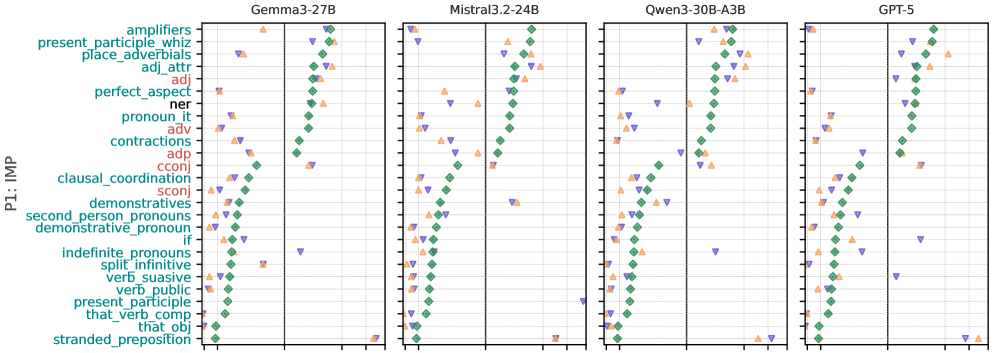
实验结果表明,LLM在SES方面的风格调整程度很小,通常导致近似或漫画化,并且更倾向于模仿较高SES的风格。这意味着LLM在理解和生成不同社会群体的语言方面存在显著偏差,可能加剧社会不平等。具体的性能数据和提升幅度未在摘要中明确给出。
🎯 应用场景
该研究结果对LLM在人机交互、社交模拟、教育等领域的应用具有重要意义。若LLM无法有效适应不同社会群体的语言风格,可能导致沟通障碍、刻板印象强化等问题。未来的研究可以基于此,开发更具社会意识的LLM,促进更公平、包容的社会交流。
📄 摘要(原文)
Humans adjust their linguistic style to the audience they are addressing. However, the extent to which LLMs adapt to different social contexts is largely unknown. As these models increasingly mediate human-to-human communication, their failure to adapt to diverse styles can perpetuate stereotypes and marginalize communities whose linguistic norms are less closely mirrored by the models, thereby reinforcing social stratification. We study the extent to which LLMs integrate into social media communication across different socioeconomic status (SES) communities. We collect a novel dataset from Reddit and YouTube, stratified by SES. We prompt four LLMs with incomplete text from that corpus and compare the LLM-generated completions to the originals along 94 sociolinguistic metrics, including syntactic, rhetorical, and lexical features. LLMs modulate their style with respect to SES to only a minor extent, often resulting in approximation or caricature, and tend to emulate the style of upper SES more effectively. Our findings (1) show how LLMs risk amplifying linguistic hierarchies and (2) call into question their validity for agent-based social simulation, survey experiments, and any research relying on language style as a social signal.