AdaptEvolve: Improving Efficiency of Evolutionary AI Agents through Adaptive Model Selection
作者: Pretam Ray, Pratik Prabhanjan Brahma, Zicheng Liu, Emad Barsoum
分类: cs.CL, cs.AI
发布日期: 2026-02-12
备注: 8 pages, 2 Figues
🔗 代码/项目: GITHUB
💡 一句话要点
AdaptEvolve:通过自适应模型选择提升进化AI代理的效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 进化AI代理 自适应模型选择 大型语言模型 计算效率 生成置信度
📋 核心要点
- 进化AI代理面临计算效率与推理能力的权衡,现有方法难以动态选择合适的LLM。
- AdaptEvolve利用LLM的内在生成置信度,自适应地选择合适的LLM进行进化细化。
- 实验表明,AdaptEvolve在降低推理成本的同时,保持了较高的准确率,实现了帕累托最优。
📝 摘要(中文)
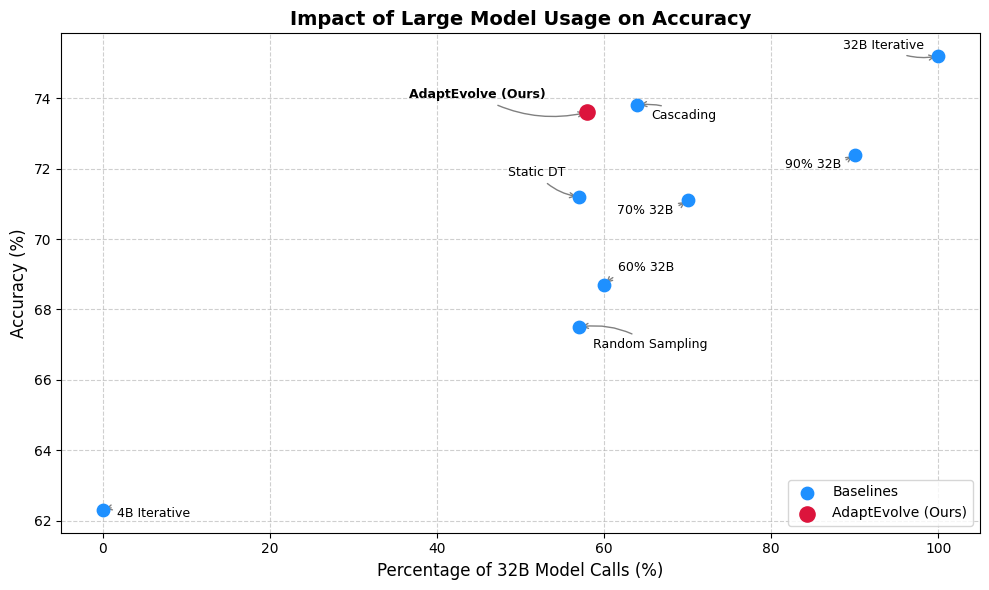
进化代理系统通过在推理过程中重复调用大型语言模型(LLM),加剧了计算效率和推理能力之间的权衡。本文提出了一个核心问题:代理如何动态地选择一个既能满足当前生成步骤的需求,又能保持计算效率的LLM?虽然模型级联提供了一种平衡这种权衡的实用机制,但现有的路由策略通常依赖于静态启发式方法或外部控制器,并且没有明确考虑模型的不确定性。我们引入了AdaptEvolve:一种用于多LLM进化细化的自适应LLM选择方法,它利用内在生成置信度来估计实时可解性。实验结果表明,置信度驱动的选择产生了一个有利的帕累托前沿,在基准测试中平均降低了37.9%的总推理成本,同时保留了静态大型模型基线97.5%的上限精度。代码已开源。
🔬 方法详解
问题定义:进化AI代理在推理过程中频繁调用LLM,计算开销巨大。现有方法如静态启发式或外部控制器,无法根据任务难度动态选择合适的LLM,导致计算资源浪费或推理能力不足。因此,需要一种方法能够根据当前任务的难度,自适应地选择合适的LLM,以平衡计算效率和推理能力。
核心思路:AdaptEvolve的核心思路是利用LLM自身的生成置信度来估计任务的实时可解性。置信度高的输出表明任务相对简单,可以使用较小的LLM;置信度低的输出表明任务复杂,需要更大的LLM。通过这种方式,AdaptEvolve可以动态地选择最适合当前任务的LLM,从而提高计算效率。
技术框架:AdaptEvolve构建于一个进化序列细化框架之上。该框架包含多个LLM,每个LLM具有不同的规模和能力。在每个生成步骤中,AdaptEvolve首先使用一个较小的LLM生成候选输出,并计算其置信度。然后,根据置信度选择一个合适的LLM进行细化。如果置信度高,则直接输出结果;如果置信度低,则使用更大的LLM进行进一步细化。这个过程可以重复多次,直到达到预定的置信度阈值或最大迭代次数。
关键创新:AdaptEvolve的关键创新在于使用LLM的内在生成置信度来驱动模型选择。与传统的静态启发式或外部控制器相比,这种方法能够更准确地估计任务的实时可解性,从而实现更高效的模型选择。此外,AdaptEvolve将模型选择集成到进化序列细化框架中,使得模型选择能够与进化过程协同优化。
关键设计:AdaptEvolve的关键设计包括:1) 使用softmax概率作为生成置信度的度量;2) 设计了一个置信度阈值,用于判断是否需要使用更大的LLM进行细化;3) 定义了一个成本函数,用于平衡计算成本和准确率。具体的参数设置和损失函数可能需要根据具体的应用场景进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,AdaptEvolve在多个基准测试中实现了显著的性能提升。与静态大型模型基线相比,AdaptEvolve平均降低了37.9%的总推理成本,同时保留了97.5%的上限精度。这表明AdaptEvolve能够在保证准确率的前提下,显著提高计算效率,实现了有利的帕累托前沿。
🎯 应用场景
AdaptEvolve可应用于各种需要进化AI代理的场景,例如机器人控制、自然语言处理和游戏AI。通过自适应地选择LLM,AdaptEvolve可以显著降低计算成本,提高代理的响应速度和可扩展性,使其更适用于资源受限的环境。该方法还可用于开发更智能、更高效的AI系统,推动人工智能技术的进步。
📄 摘要(原文)
Evolutionary agentic systems intensify the trade-off between computational efficiency and reasoning capability by repeatedly invoking large language models (LLMs) during inference. This setting raises a central question: how can an agent dynamically select an LLM that is sufficiently capable for the current generation step while remaining computationally efficient? While model cascades offer a practical mechanism for balancing this trade-off, existing routing strategies typically rely on static heuristics or external controllers and do not explicitly account for model uncertainty. We introduce AdaptEvolve: Adaptive LLM Selection for Multi-LLM Evolutionary Refinement within an evolutionary sequential refinement framework that leverages intrinsic generation confidence to estimate real-time solvability. Empirical results show that confidence-driven selection yields a favourable Pareto frontier, reducing total inference cost by an average of 37.9% across benchmarks while retaining 97.5% of the upper-bound accuracy of static large-model baselines. Our code is available at https://github.com/raypretam/adaptive_llm_selection.