Benchmark Illusion: Disagreement among LLMs and Its Scientific Consequences
作者: Eddie Yang, Dashun Wang
分类: cs.CL
发布日期: 2026-02-12
💡 一句话要点
揭示大语言模型基准测试的幻觉:模型间存在显著分歧,影响科学研究可复现性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 基准测试 模型分歧 科学可重复性 数据标注 推理任务 模型评估
📋 核心要点
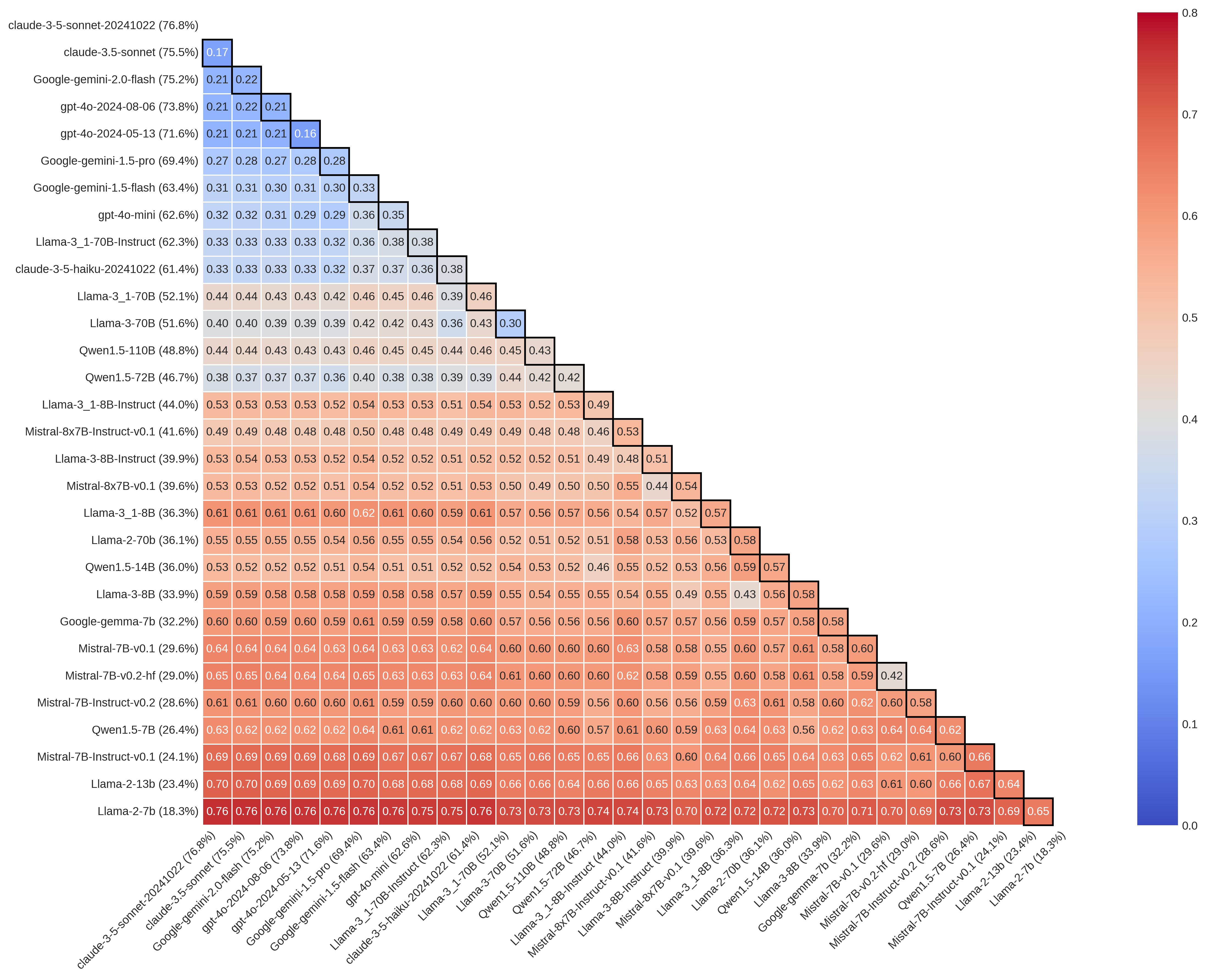
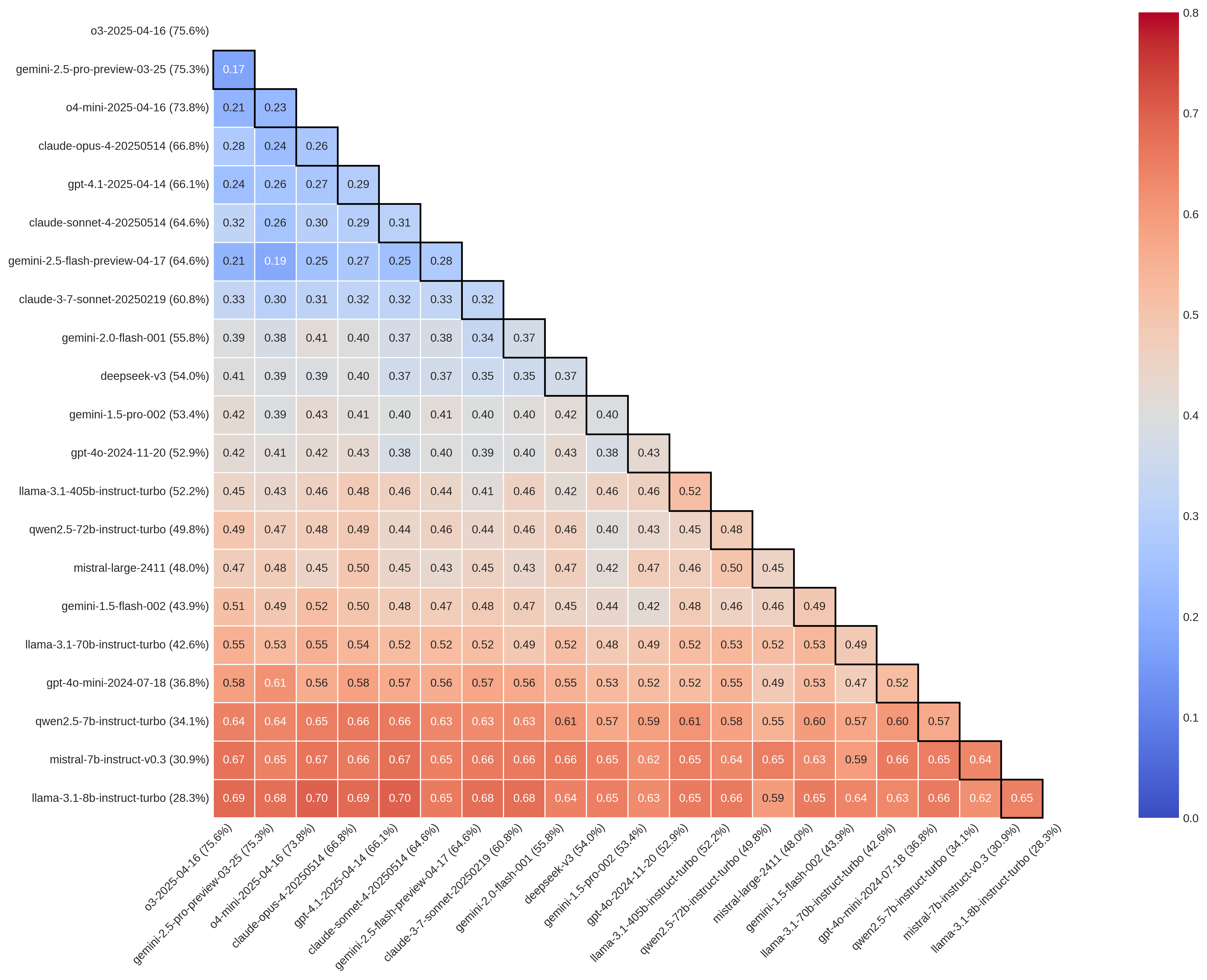
- 现有基准测试虽然显示LLM准确率收敛,但忽略了模型间在具体样本上的认知分歧。
- 论文核心在于揭示这种“基准幻觉”,即表面一致的准确率掩盖了模型间的实质性分歧。
- 实验表明,模型分歧会严重影响下游科学研究结果,例如改变治疗效果的估计值。
📝 摘要(中文)
基准测试是衡量和信任大型语言模型(LLMs)进展的基础。然而,我们的分析表明,基准测试准确率的表面收敛可能掩盖了深刻的认知分歧。通过使用两个主要的推理基准——MMLU-Pro和GPQA,我们发现,即使LLMs达到了相当的准确率,它们在16-66%的项目上仍然存在分歧,并且在表现最佳的前沿模型中,这种分歧也达到了16-38%。这些差异表明不同LLMs具有不同的错误特征。当这些模型用于科学数据注释和推理时,它们隐藏的分歧会传播到研究结果中:在对已发表的教育学和政治学研究的重新分析中,切换注释模型可以使估计的治疗效果改变超过80%,在某些情况下甚至会逆转其符号。总之,这些发现揭示了一种基准幻觉,即相等的准确率可能掩盖分歧,模型选择成为科学可重复性的一个隐藏但重要的变量。
🔬 方法详解
问题定义:现有的大语言模型(LLMs)在基准测试中表现出相似的准确率,但这种表面上的一致性掩盖了模型之间在具体样本上的分歧。这种分歧导致在下游任务中,特别是科学研究的数据标注和推理中,模型选择成为一个重要的混淆因素,影响研究结果的可重复性和可靠性。现有方法没有充分考虑这种模型间的差异性,导致研究结果可能受到模型选择偏差的影响。
核心思路:论文的核心思路是揭示LLM在基准测试中存在的“基准幻觉”,即表面上相似的准确率掩盖了模型之间的实质性分歧。通过分析LLM在不同基准测试样本上的预测结果,量化模型之间的分歧程度,并进一步研究这种分歧对下游科学研究的影响。
技术框架:论文主要通过以下步骤进行分析:1) 选择两个主要的推理基准测试(MMLU-Pro和GPQA);2) 收集多个LLM在这些基准测试上的预测结果;3) 计算模型之间的分歧程度,例如计算模型之间预测结果不一致的样本比例;4) 将LLM应用于下游科学研究的数据标注和推理任务,例如教育学和政治学研究中的治疗效果估计;5) 分析模型选择对下游任务结果的影响,例如比较不同模型标注数据后得到的治疗效果估计值。
关键创新:论文最重要的技术创新点在于揭示了LLM在基准测试中存在的“基准幻觉”,并量化了这种幻觉对下游科学研究的影响。与现有方法不同,论文关注的是模型之间的分歧,而不是模型的绝对准确率,从而更全面地评估了LLM的性能。
关键设计:论文的关键设计包括:1) 选择具有代表性的推理基准测试(MMLU-Pro和GPQA);2) 采用多种LLM进行对比分析,包括不同架构和训练数据的模型;3) 使用统计方法量化模型之间的分歧程度;4) 将LLM应用于真实的科学研究场景,评估模型选择对研究结果的影响。
🖼️ 关键图片

📊 实验亮点
研究发现,即使在MMLU-Pro和GPQA等基准测试中达到相似准确率的LLM,在16-66%的样本上仍然存在分歧。在教育学和政治学研究的重新分析中,切换LLM进行数据标注,可以使估计的治疗效果改变超过80%,甚至逆转其符号。这些结果表明,模型选择对科学研究的可重复性具有显著影响。
🎯 应用场景
该研究成果对LLM的评估和应用具有重要意义。它提醒研究人员在选择LLM进行科学研究时,需要考虑模型之间的分歧,并采取措施减轻模型选择偏差的影响。此外,该研究也为开发更可靠的LLM评估方法提供了思路,例如可以设计新的基准测试,更加关注模型之间的分歧。
📄 摘要(原文)
Benchmarks underpin how progress in large language models (LLMs) is measured and trusted. Yet our analyses reveal that apparent convergence in benchmark accuracy can conceal deep epistemic divergence. Using two major reasoning benchmarks - MMLU-Pro and GPQA - we show that LLMs achieving comparable accuracy still disagree on 16-66% of items, and 16-38% among top-performing frontier models. These discrepancies suggest distinct error profiles for different LLMs. When such models are used for scientific data annotation and inference, their hidden disagreements propagate into research results: in re-analyses of published studies in education and political science, switching the annotation model can change estimated treatment effects by more than 80%, and in some cases reverses their sign. Together, these findings illustrate a benchmark illusion, where equal accuracy may conceal disagreement, with model choice becoming a hidden yet consequential variable for scientific reproducibility.