Towards Fair and Comprehensive Evaluation of Routers in Collaborative LLM Systems
作者: Wanxing Wu, He Zhu, Yixia Li, Lei Yang, Jiehui Zhao, Hongru Wang, Jian Yang, Benyou Wang, Bingyi Jing, Guanhua Chen
分类: cs.CL, cs.AI
发布日期: 2026-02-12
备注: Our code is publicly available at https://github.com/zhuchichi56/RouterXBench
💡 一句话要点
提出RouterXBench评估框架与ProbeDirichlet路由方法,提升协同LLM系统中路由器的公平性和全面性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 协同系统 路由器 模型路由 不确定性估计 Dirichlet分布 RouterXBench
📋 核心要点
- 现有LLM路由器评估缺乏系统性,忽略了场景特定需求和分布外数据的鲁棒性。
- 论文提出RouterXBench评估框架和ProbeDirichlet路由方法,利用模型内部隐藏状态捕捉不确定性。
- ProbeDirichlet在路由器能力和高精度场景中显著优于现有方法,并在多种设置下表现稳定。
📝 摘要(中文)
大型语言模型(LLM)取得了显著成功,但成本和隐私限制使得在本地部署较小模型,同时将复杂查询卸载到云端模型成为必要。现有的路由器评估不够系统,忽略了特定场景的需求和分布外(out-of-distribution)的鲁棒性。我们提出了RouterXBench,一个包含三个维度的原则性评估框架:路由器能力、场景对齐和跨域鲁棒性。与依赖输出概率或外部嵌入的先前工作不同,我们利用内部隐藏状态来捕捉答案生成前的模型不确定性。我们引入了ProbeDirichlet,一种轻量级路由器,它通过具有概率训练的可学习Dirichlet分布聚合跨层隐藏状态。经过多域数据训练,它在域内和分布外场景中都能稳健地泛化。结果表明,ProbeDirichlet在路由器能力和高精度场景中,相对于最佳基线分别实现了16.68%和18.86%的相对改进,并在模型家族、模型规模、异构任务和代理工作流中保持一致的性能。
🔬 方法详解
问题定义:论文旨在解决协同LLM系统中路由器评估不公平、不全面的问题。现有方法主要依赖输出概率或外部嵌入,无法有效捕捉模型在生成答案前的不确定性,并且缺乏对场景适应性和跨域鲁棒性的系统评估。
核心思路:论文的核心思路是利用LLM的内部隐藏状态来表征模型的不确定性,并基于此进行路由决策。通过学习不同层隐藏状态的Dirichlet分布,可以更准确地估计模型对不同输入的置信度,从而实现更有效的路由。
技术框架:整体框架包含RouterXBench评估框架和ProbeDirichlet路由器。RouterXBench从路由器能力、场景对齐和跨域鲁棒性三个维度进行评估。ProbeDirichlet路由器首先提取LLM不同层的隐藏状态,然后通过可学习的Dirichlet分布对这些隐藏状态进行加权聚合,最后基于聚合后的表示进行路由决策。
关键创新:关键创新在于利用内部隐藏状态来捕捉模型的不确定性,并使用可学习的Dirichlet分布进行加权聚合。这种方法避免了对输出概率或外部嵌入的依赖,能够更准确地估计模型对不同输入的置信度。此外,RouterXBench评估框架的提出,为路由器的公平和全面评估提供了标准。
关键设计:ProbeDirichlet的关键设计包括:1) 提取LLM多个Transformer层的隐藏状态;2) 使用可学习的Dirichlet分布参数化每个隐藏状态的权重;3) 使用概率训练方法优化Dirichlet分布的参数,使得模型能够更好地捕捉不同输入的置信度;4) 使用交叉熵损失函数进行路由决策的训练。
🖼️ 关键图片
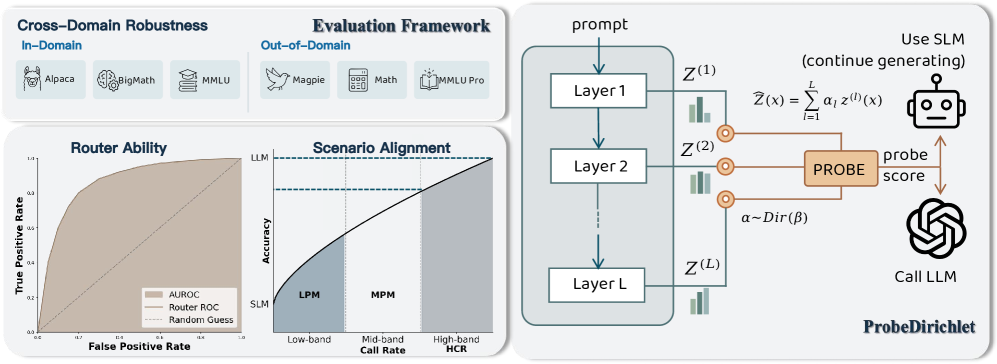
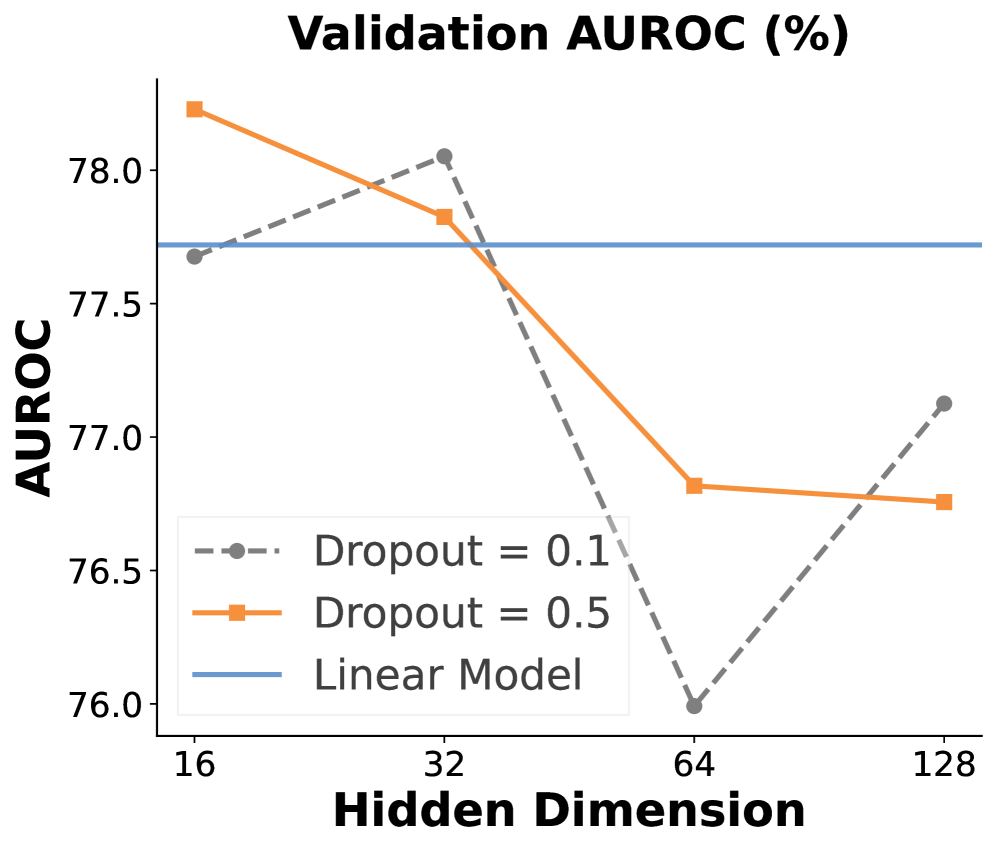
📊 实验亮点
ProbeDirichlet在路由器能力和高精度场景中,相对于最佳基线分别实现了16.68%和18.86%的相对改进。实验结果表明,ProbeDirichlet在不同的模型家族、模型规模、异构任务和代理工作流中都表现出一致的性能,验证了其鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于各种需要协同LLM系统的场景,例如智能客服、智能问答、内容生成等。通过更智能的路由,可以降低计算成本、保护用户隐私,并提升系统的整体性能和用户体验。未来,该方法还可以扩展到更复杂的任务和模型架构中。
📄 摘要(原文)
Large language models (LLMs) have achieved success, but cost and privacy constraints necessitate deploying smaller models locally while offloading complex queries to cloud-based models. Existing router evaluations are unsystematic, overlooking scenario-specific requirements and out-of-distribution robustness. We propose RouterXBench, a principled evaluation framework with three dimensions: router ability, scenario alignment, and cross-domain robustness. Unlike prior work that relies on output probabilities or external embeddings, we utilize internal hidden states that capture model uncertainty before answer generation. We introduce ProbeDirichlet, a lightweight router that aggregates cross-layer hidden states via learnable Dirichlet distributions with probabilistic training. Trained on multi-domain data, it generalizes robustly across in-domain and out-of-distribution scenarios. Our results show ProbeDirichlet achieves 16.68% and 18.86% relative improvements over the best baselines in router ability and high-accuracy scenarios, with consistent performance across model families, model scales, heterogeneous tasks, and agentic workflows.