DMAP: A Distribution Map for Text
作者: Tom Kempton, Julia Rozanova, Parameswaran Kamalaruban, Maeve Madigan, Karolina Wresilo, Yoann L. Launay, David Sutton, Stuart Burrell
分类: cs.CL, cs.LG
发布日期: 2026-02-12
备注: ICLR 2026
💡 一句话要点
提出DMAP:一种基于分布映射的文本分析方法,用于解决现有方法在文本分析中对上下文考虑不足的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分析 大型语言模型 概率分布 机器生成文本检测 法医学分析 统计指纹 上下文信息
📋 核心要点
- 现有文本分析方法,如困惑度,无法充分考虑上下文信息,导致对token概率的解读不够准确。
- DMAP将文本通过语言模型映射到单位区间样本集,联合编码rank和概率信息,实现模型无关的文本分析。
- 实验表明,DMAP可用于验证生成参数、检测机器生成文本以及进行法医学分析,揭示模型训练痕迹。
📝 摘要(中文)
大型语言模型(LLMs)是强大的统计文本分析工具,其导出的下一个token概率分布序列蕴含着丰富的信息。提取这些信息通常依赖于困惑度等指标,但这些指标没有充分考虑上下文信息;对给定的下一个token概率的解释应取决于条件分布形状所编码的合理选择的数量。本文提出了一种数学上严谨的方法DMAP,它通过语言模型将文本映射到单位区间内的一组样本,这些样本共同编码了rank和概率信息。这种表示能够实现高效的、模型无关的分析,并支持一系列应用。我们通过三个案例研究说明了它的效用:(i)验证生成参数以确保数据完整性,(ii)检查概率曲率在机器生成文本检测中的作用,以及(iii)一项法医学分析,揭示了在经过合成数据后训练的下游模型中留下的统计指纹。我们的结果表明,DMAP提供了一个统一的文本统计视图,它易于在消费级硬件上计算,具有广泛的适用性,并为进一步研究LLM的文本分析奠定了基础。
🔬 方法详解
问题定义:现有文本分析方法,例如困惑度,在评估文本质量或检测机器生成文本时,往往忽略了上下文信息。一个token的概率高低,需要结合其上下文的合理选择数量来判断。因此,如何有效地利用LLM提供的概率分布信息,并充分考虑上下文,是一个关键问题。现有方法缺乏一种统一的、模型无关的文本统计视图。
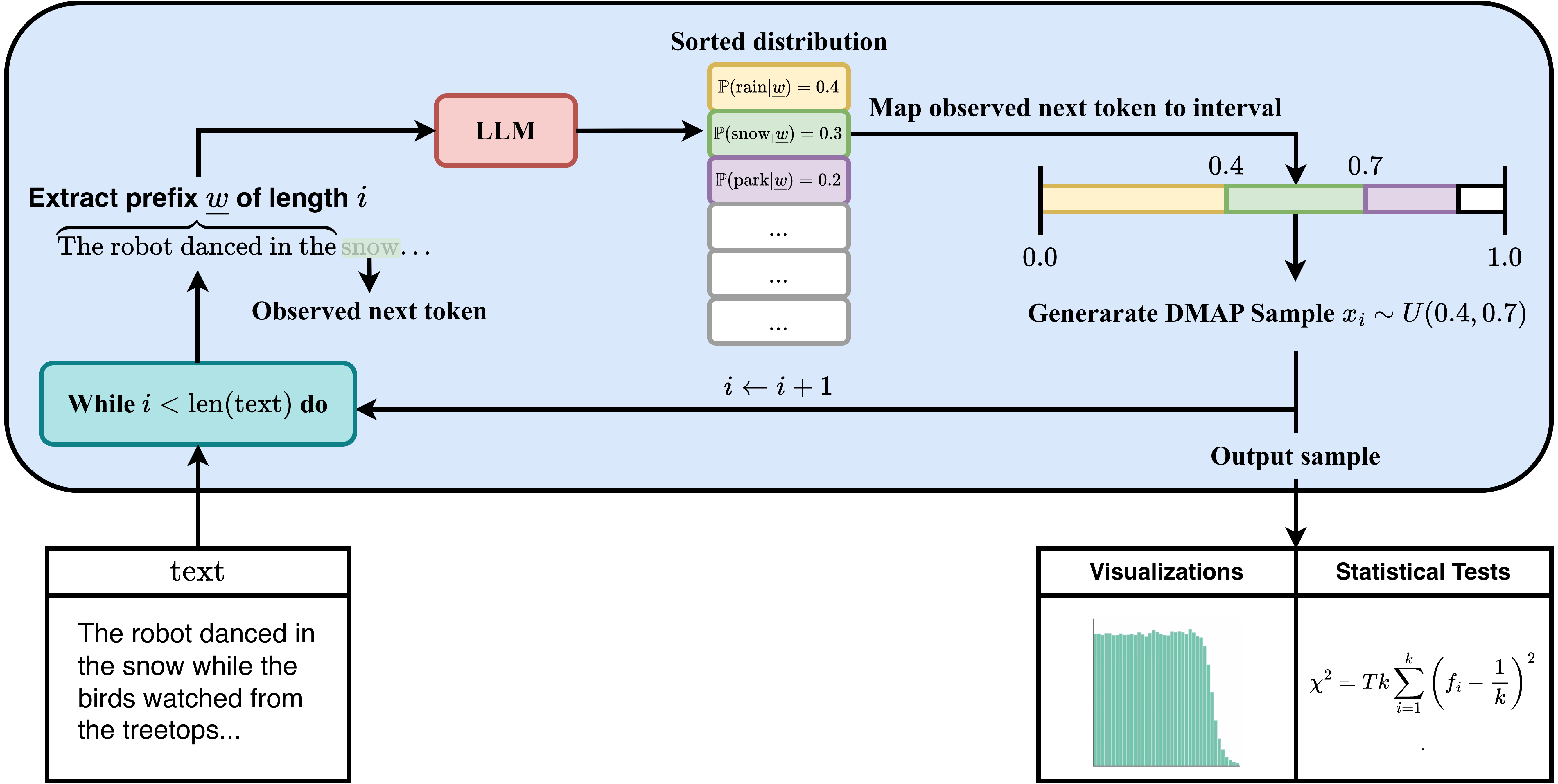
核心思路:DMAP的核心思路是将文本通过LLM转化为一系列的下一个token概率分布,然后将这些分布映射到单位区间[0, 1]上的一组样本点。每个样本点编码了对应token的rank(在概率分布中的排序)和概率信息。通过分析这些样本点的分布,可以推断文本的统计特征,而无需直接依赖困惑度等指标。这种方法的核心在于将离散的概率分布转化为连续的样本分布,从而方便进行统计分析。
技术框架:DMAP的技术框架主要包含以下几个步骤: 1. 文本输入:输入待分析的文本序列。 2. LLM处理:使用预训练的LLM,逐个token预测下一个token的概率分布。 3. 概率排序:对每个token的概率分布进行排序,得到每个token的rank。 4. 映射到单位区间:将每个token的rank和概率信息映射到单位区间[0, 1]上的一个样本点。具体的映射方式可以根据具体应用选择。 5. 统计分析:对单位区间上的样本点进行统计分析,例如计算分布的形状、曲率等特征。
关键创新:DMAP最重要的技术创新在于它提供了一种统一的、模型无关的文本统计视图。与传统的基于困惑度的方法不同,DMAP直接利用LLM提供的概率分布信息,并将其转化为连续的样本分布。这种方法不仅考虑了token的概率,还考虑了其在概率分布中的排序(rank),从而更好地反映了上下文信息。此外,DMAP的设计使其可以应用于不同的LLM,而无需进行特定的模型训练。
关键设计:DMAP的关键设计在于如何将rank和概率信息有效地映射到单位区间[0, 1]上。论文中可能探讨了不同的映射函数,例如线性映射、非线性映射等。具体的映射函数需要根据具体应用进行选择,以最大程度地保留原始概率分布的信息。此外,对单位区间上的样本点进行统计分析时,可以选择不同的统计指标,例如均值、方差、分位数等。这些统计指标可以用于描述文本的统计特征,例如文本的流畅度、可预测性等。
🖼️ 关键图片

📊 实验亮点
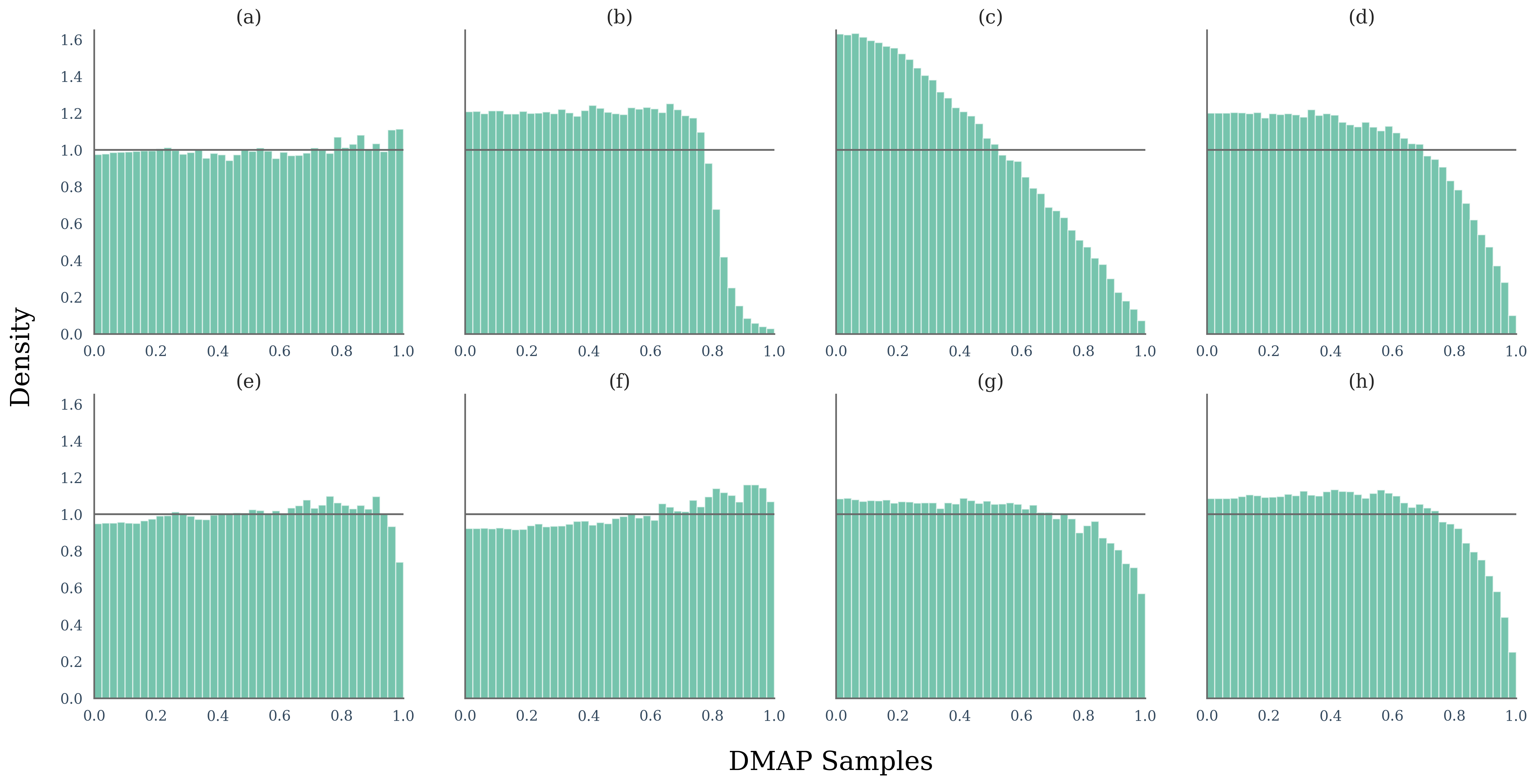
论文通过三个案例研究展示了DMAP的有效性:(1) 验证生成参数以确保数据完整性;(2) 检查概率曲率在机器生成文本检测中的作用,表明DMAP能够有效区分人类撰写和机器生成的文本;(3) 法医学分析揭示了在经过合成数据后训练的下游模型中留下的统计指纹,证明DMAP可以用于追踪模型的训练历史。
🎯 应用场景
DMAP具有广泛的应用前景,包括:文本生成质量评估、机器生成文本检测、法医学分析(例如,识别经过特定数据训练的模型)、内容审核、以及自然语言处理模型的安全性和可靠性评估。通过分析文本的统计指纹,可以更好地理解和控制LLM的行为,并防范潜在的滥用风险。
📄 摘要(原文)
Large Language Models (LLMs) are a powerful tool for statistical text analysis, with derived sequences of next-token probability distributions offering a wealth of information. Extracting this signal typically relies on metrics such as perplexity, which do not adequately account for context; how one should interpret a given next-token probability is dependent on the number of reasonable choices encoded by the shape of the conditional distribution. In this work, we present DMAP, a mathematically grounded method that maps a text, via a language model, to a set of samples in the unit interval that jointly encode rank and probability information. This representation enables efficient, model-agnostic analysis and supports a range of applications. We illustrate its utility through three case studies: (i) validation of generation parameters to ensure data integrity, (ii) examining the role of probability curvature in machine-generated text detection, and (iii) a forensic analysis revealing statistical fingerprints left in downstream models that have been subject to post-training on synthetic data. Our results demonstrate that DMAP offers a unified statistical view of text that is simple to compute on consumer hardware, widely applicable, and provides a foundation for further research into text analysis with LLMs.