More Haste, Less Speed: Weaker Single-Layer Watermark Improves Distortion-Free Watermark Ensembles
作者: Ruibo Chen, Yihan Wu, Xuehao Cui, Jingqi Zhang, Heng Huang
分类: cs.CR, cs.CL
发布日期: 2026-02-12
💡 一句话要点
提出弱水印集成方法,解决强水印降低token分布熵,削弱多层水印效果的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 水印技术 语言模型 信息溯源 水印集成 熵 鲁棒性 可检测性
📋 核心要点
- 现有水印集成方法侧重于增强单层水印强度,但忽略了强水印对token分布熵的负面影响,导致后续层水印效果减弱。
- 论文提出使用较弱的单层水印,以保持token分布的熵,从而提升多层水印集成的整体效果。
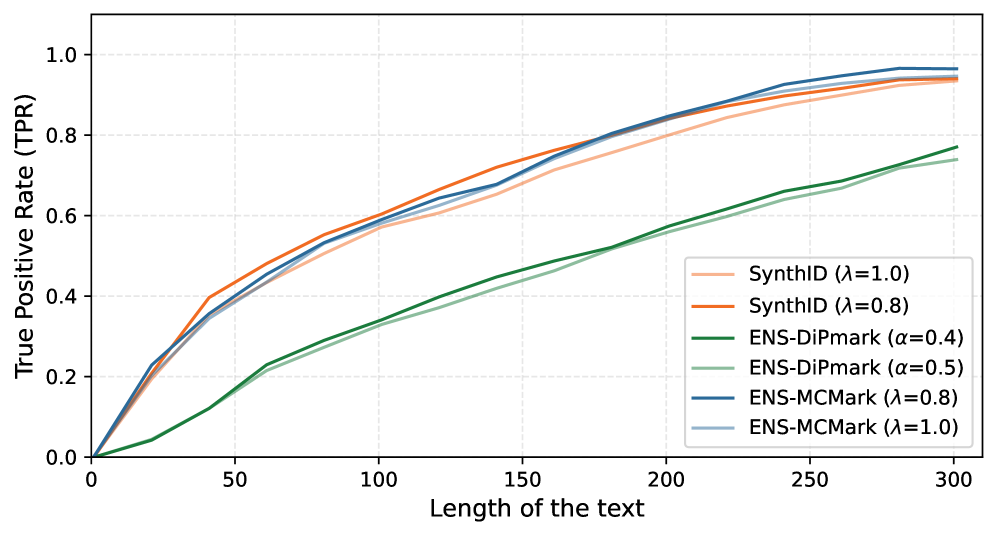
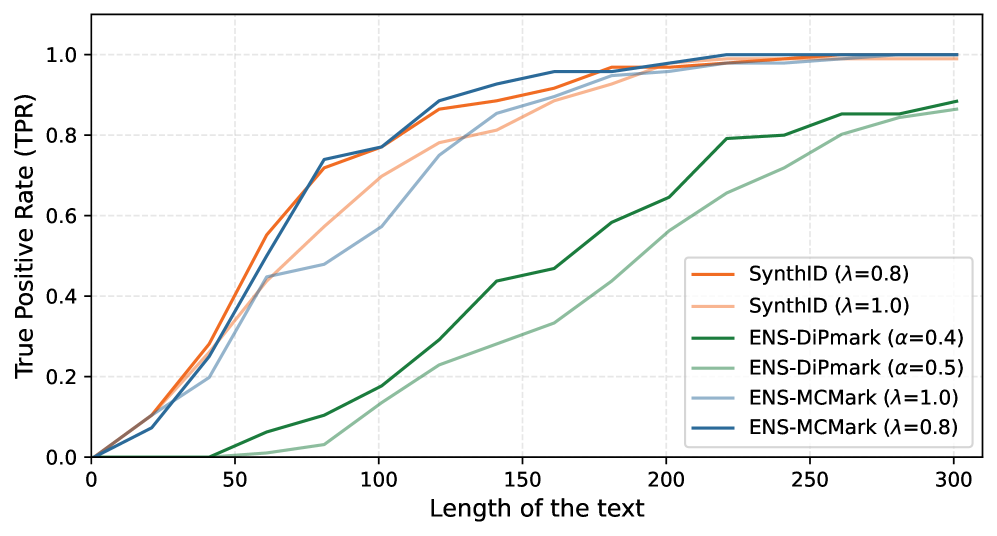
- 实验结果表明,该方法能够有效减轻信号衰减,在可检测性和鲁棒性方面均优于强水印基线。
📝 摘要(中文)
水印技术已成为检测和溯源大型语言模型生成内容的关键手段。虽然最近的研究利用水印集成来增强鲁棒性,但主流方法通常优先最大化每一层水印的强度。本文指出这种“越强越好”的方法存在一个关键限制:强水印会显著降低token分布的熵,反而削弱了后续层水印的有效性。理论和实验表明,可检测性受熵的限制,并且水印集成会导致熵和预期绿名单比例在各层之间单调递减。为了解决这种固有的权衡,我们提出了一个通用框架,该框架利用较弱的单层水印来保持有效多层集成所需的熵。实验评估表明,这种反直觉的策略可以减轻信号衰减,并在可检测性和鲁棒性方面始终优于强水印基线。
🔬 方法详解
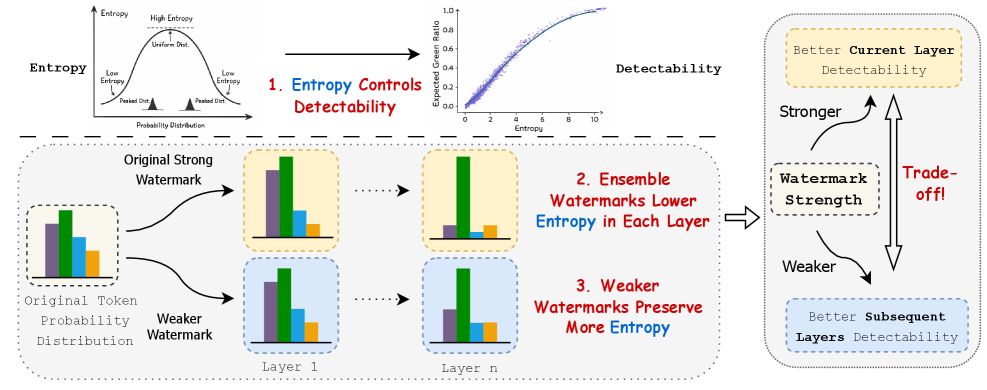
问题定义:论文旨在解决大型语言模型生成文本的水印溯源问题。现有水印集成方法倾向于在每一层都使用强水印,但这种做法会显著降低token分布的熵,导致后续层的水印效果大打折扣。因此,如何在保证水印强度的同时,维持token分布的熵,是本文要解决的关键问题。
核心思路:论文的核心思路是“Less Speed, More Haste”,即不要过度强调单层水印的强度,而是采用较弱的水印,从而保留更多的token分布熵。这样,在多层水印集成时,后续层的水印才能更有效地发挥作用。这种反直觉的设计旨在平衡水印强度和token分布熵之间的权衡。
技术框架:论文提出了一个通用的水印集成框架,该框架允许在每一层使用不同强度的水印。具体流程如下:首先,在第一层文本生成时,嵌入一个较弱的水印。然后,在后续层,继续嵌入水印,但同样保持较低的强度。最后,在检测阶段,综合考虑所有层的水印信息,进行溯源判断。框架的关键在于控制每一层水印的强度,以维持token分布的熵。
关键创新:论文最重要的创新点在于发现了强水印对token分布熵的负面影响,并提出了使用弱水印来改善多层水印集成效果的反直觉策略。与现有方法不同,该方法不再一味追求单层水印的强度,而是更加注重整体的集成效果。
关键设计:论文的关键设计在于如何选择合适的弱水印强度。具体而言,需要根据语言模型的特性和水印算法的特点,进行实验和分析,找到一个能够平衡水印强度和token分布熵的最佳值。此外,论文可能还涉及一些具体的损失函数设计,用于优化水印的嵌入过程,以进一步提升水印的鲁棒性和可检测性(具体细节未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,与强水印基线相比,该方法在可检测性和鲁棒性方面均取得了显著提升。具体性能数据未知,但摘要中明确指出该方法能够减轻信号衰减,并在各项指标上始终优于强水印基线。这表明该方法能够更有效地利用多层水印集成,实现更好的溯源效果。
🎯 应用场景
该研究成果可应用于大型语言模型生成内容的版权保护、溯源和内容真实性验证。通过有效的水印技术,可以追踪恶意信息的来源,防止AI生成内容被滥用,并为内容创作者提供权益保障。未来,该技术有望在新闻媒体、社交平台、教育等领域发挥重要作用。
📄 摘要(原文)
Watermarking has emerged as a crucial technique for detecting and attributing content generated by large language models. While recent advancements have utilized watermark ensembles to enhance robustness, prevailing methods typically prioritize maximizing the strength of the watermark at every individual layer. In this work, we identify a critical limitation in this "stronger-is-better" approach: strong watermarks significantly reduce the entropy of the token distribution, which paradoxically weakens the effectiveness of watermarking in subsequent layers. We theoretically and empirically show that detectability is bounded by entropy and that watermark ensembles induce a monotonic decrease in both entropy and the expected green-list ratio across layers. To address this inherent trade-off, we propose a general framework that utilizes weaker single-layer watermarks to preserve the entropy required for effective multi-layer ensembling. Empirical evaluations demonstrate that this counter-intuitive strategy mitigates signal decay and consistently outperforms strong baselines in both detectability and robustness.