MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
作者: MiniCPM Team, Wenhao An, Yingfa Chen, Yewei Fang, Jiayi Li, Xin Li, Yaohui Li, Yishan Li, Yuxuan Li, Biyuan Lin, Chuan Liu, Hezi Liu, Siyuan Liu, Hongya Lyu, Yinxu Pan, Shixin Ren, Xingyu Shen, Zhou Su, Haojun Sun, Yangang Sun, Zhen Leng Thai, Xin Tian, Rui Wang, Xiaorong Wang, Yudong Wang, Bo Wu, Xiaoyue Xu, Dong Xu, Shuaikang Xue, Jiawei Yang, Bowen Zhang, Jinqian Zhang, Letian Zhang, Shengnan Zhang, Xinyu Zhang, Xinyuan Zhang, Zhu Zhang, Hengyu Zhao, Jiacheng Zhao, Jie Zhou, Zihan Zhou, Shuo Wang, Chaojun Xiao, Xu Han, Zhiyuan Liu, Maosong Sun
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-12
备注: MiniCPM-SALA Technical Report
💡 一句话要点
MiniCPM-SALA:混合稀疏和线性注意力,实现高效长文本建模
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本建模 稀疏注意力 线性注意力 混合注意力 持续训练 Transformer 大语言模型 高效推理
📋 核心要点
- Transformer架构在处理超长文本时面临计算和内存瓶颈,现有稀疏和线性注意力机制难以兼顾效率与性能。
- MiniCPM-SALA通过混合稀疏和线性注意力,并结合层选择算法和混合位置编码,实现了长文本建模的效率和性能平衡。
- 该模型采用持续训练框架,显著降低了训练成本,并在长文本推理速度和上下文长度上取得了显著提升。
📝 摘要(中文)
大型语言模型(LLM)在超长上下文应用中面临Transformer架构带来的高计算和内存成本挑战。现有的稀疏和线性注意力机制试图缓解这些问题,但通常需要在内存效率和模型性能之间进行权衡。本文介绍了MiniCPM-SALA,一个90亿参数的混合架构,它集成了稀疏注意力的保真长上下文建模能力(InfLLM-V2)和线性注意力的全局效率(Lightning Attention)。通过采用层选择算法以1:3的比例集成这些机制,并利用混合位置编码(HyPE),该模型在长上下文任务中保持了效率和性能。此外,我们引入了一种经济高效的持续训练框架,将预训练的基于Transformer的模型转换为混合模型,与从头开始训练相比,降低了约75%的训练成本。大量实验表明,MiniCPM-SALA保持了与全注意力模型相当的通用能力,同时提供了更高的效率。在单个NVIDIA A6000D GPU上,该模型在256K tokens的序列长度下实现了高达3.5倍于全注意力模型的推理速度,并支持高达1M tokens的上下文长度,这是传统的全注意力8B模型因内存限制而无法达到的规模。
🔬 方法详解
问题定义:现有的大型语言模型在处理超长上下文时,Transformer架构的计算复杂度和内存占用呈平方级增长,导致效率低下。稀疏注意力虽然能降低计算复杂度,但可能损失建模能力。线性注意力虽然高效,但可能牺牲模型性能。因此,如何在保证模型性能的前提下,降低长文本建模的计算和内存成本是一个关键问题。
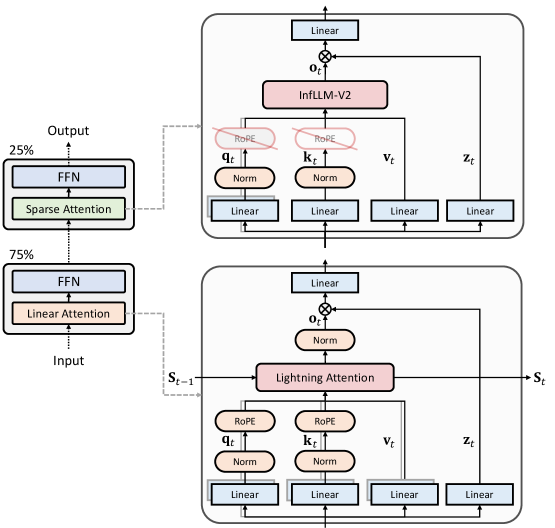
核心思路:MiniCPM-SALA的核心思路是结合稀疏注意力和线性注意力的优点,通过混合使用这两种注意力机制,在效率和性能之间取得平衡。稀疏注意力擅长捕捉长距离依赖关系,而线性注意力计算效率高。通过合理分配两种注意力机制的比例,可以在保证模型性能的同时,显著降低计算成本。
技术框架:MiniCPM-SALA的整体架构是一个混合注意力Transformer模型。它包含多个Transformer层,其中一部分层使用稀疏注意力(InfLLM-V2),另一部分层使用线性注意力(Lightning Attention)。论文采用层选择算法来确定每种注意力机制的层数比例,通常稀疏注意力层和线性注意力层的比例为1:3。此外,模型还使用了混合位置编码(HyPE),结合了绝对位置编码和相对位置编码,以更好地处理长文本。最后,论文提出了一个持续训练框架,将预训练的Transformer模型转换为混合模型,从而降低训练成本。
关键创新:MiniCPM-SALA的关键创新在于混合注意力机制和持续训练框架。混合注意力机制通过结合稀疏注意力和线性注意力的优点,实现了效率和性能的平衡。持续训练框架则显著降低了训练成本,使得在现有预训练模型的基础上进行长文本建模成为可能。与现有方法相比,MiniCPM-SALA能够在保证模型性能的前提下,显著提高长文本推理速度和支持更长的上下文长度。
关键设计:MiniCPM-SALA的关键设计包括:1) 稀疏注意力和线性注意力的比例选择,通常设置为1:3;2) 混合位置编码(HyPE),结合了绝对位置编码和相对位置编码;3) 持续训练框架,通过冻结部分参数并仅训练注意力相关的参数,降低训练成本;4) 损失函数的设计,可能包括语言模型损失和对比学习损失等,以保证模型性能。
🖼️ 关键图片


📊 实验亮点
MiniCPM-SALA在长文本推理速度和上下文长度上取得了显著提升。在单个NVIDIA A6000D GPU上,该模型在256K tokens的序列长度下实现了高达3.5倍于全注意力模型的推理速度。此外,该模型还支持高达1M tokens的上下文长度,这是传统的全注意力8B模型因内存限制而无法达到的规模。实验结果表明,MiniCPM-SALA在保持与全注意力模型相当的通用能力的同时,提供了更高的效率。
🎯 应用场景
MiniCPM-SALA在需要处理超长文本的场景中具有广泛的应用前景,例如长篇小说生成、法律文档分析、科学论文理解、代码生成和对话系统等。该模型能够高效地处理长文本输入,并生成高质量的输出,从而提高相关应用的性能和用户体验。此外,该模型还可以应用于知识图谱构建、信息检索和推荐系统等领域,为这些应用提供更强大的文本处理能力。
📄 摘要(原文)
The evolution of large language models (LLMs) towards applications with ultra-long contexts faces challenges posed by the high computational and memory costs of the Transformer architecture. While existing sparse and linear attention mechanisms attempt to mitigate these issues, they typically involve a trade-off between memory efficiency and model performance. This paper introduces MiniCPM-SALA, a 9B-parameter hybrid architecture that integrates the high-fidelity long-context modeling of sparse attention (InfLLM-V2) with the global efficiency of linear attention (Lightning Attention). By employing a layer selection algorithm to integrate these mechanisms in a 1:3 ratio and utilizing a hybrid positional encoding (HyPE), the model maintains efficiency and performance for long-context tasks. Furthermore, we introduce a cost-effective continual training framework that transforms pre-trained Transformer-based models into hybrid models, which reduces training costs by approximately 75% compared to training from scratch. Extensive experiments show that MiniCPM-SALA maintains general capabilities comparable to full-attention models while offering improved efficiency. On a single NVIDIA A6000D GPU, the model achieves up to 3.5x the inference speed of the full-attention model at the sequence length of 256K tokens and supports context lengths of up to 1M tokens, a scale where traditional full-attention 8B models fail because of memory constraints.