Think Longer to Explore Deeper: Learn to Explore In-Context via Length-Incentivized Reinforcement Learning
作者: Futing Wang, Jianhao Yan, Yun Luo, Ganqu Cui, Zhi Wang, Xiaoye Qu, Yue Zhang, Yu Cheng, Tao Lin
分类: cs.CL
发布日期: 2026-02-12
💡 一句话要点
提出长度激励探索方法以解决上下文探索问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 上下文探索 强化学习 状态覆盖 推理能力 模型优化
📋 核心要点
- 现有方法在上下文探索中面临‘浅层探索陷阱’,导致状态覆盖不足。
- 本文提出长度激励探索方法,通过长度奖励和冗余惩罚来鼓励模型进行更深入的探索。
- 实验结果显示,该方法在多个模型上实现了4.4%的领域内提升和2.7%的领域外提升。
📝 摘要(中文)
实现有效的测试时间扩展需要模型具备上下文探索的能力,即在单一连续上下文中生成、验证和完善多个推理假设。基于状态覆盖理论的分析指出,当前方法面临的关键瓶颈是:更广泛的状态覆盖需要更长的推理轨迹,但在自回归生成过程中,采样此类序列的概率呈指数级下降,这一现象被称为“浅层探索陷阱”。为了解决这一问题,本文提出了长度激励探索方法,通过长度奖励和冗余惩罚显式鼓励模型进行更多探索,从而以两步方式最大化状态覆盖。实验表明,该方法在不同模型(如Qwen3和Llama)上有效激励上下文探索,平均在领域内任务上提升4.4%,在领域外基准上提升2.7%。
🔬 方法详解
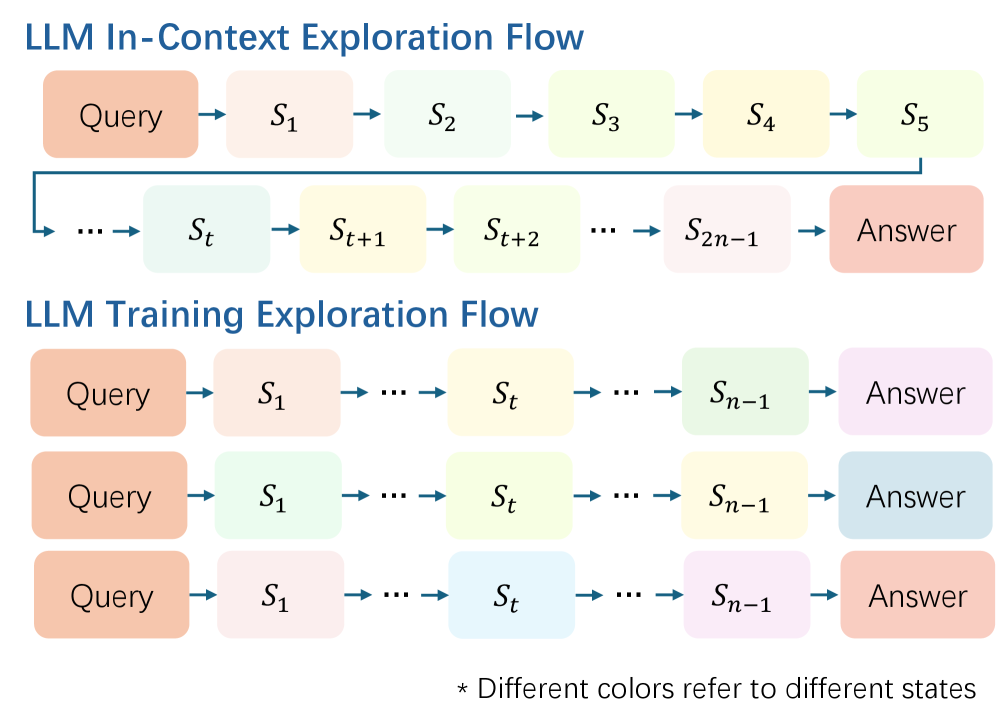
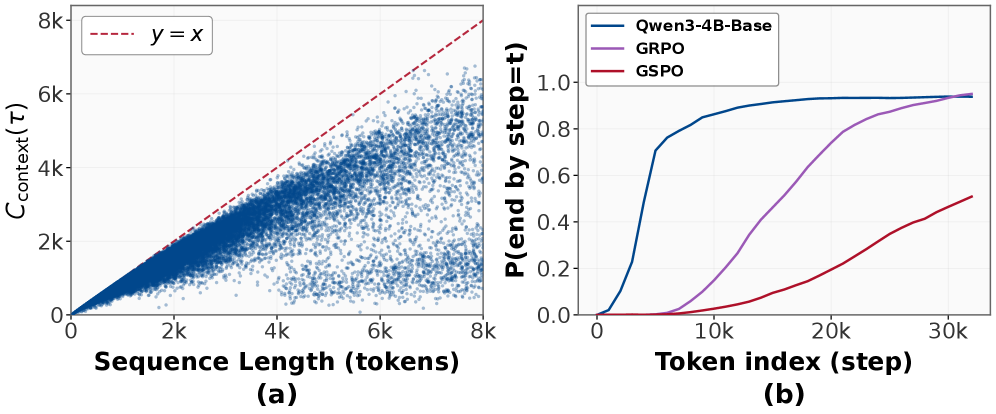
问题定义:本文旨在解决模型在上下文中进行有效探索的能力不足,尤其是在自回归生成过程中,长推理轨迹的采样概率迅速下降,导致状态覆盖不足。
核心思路:提出长度激励探索方法,通过引入长度奖励和冗余惩罚,鼓励模型生成更长的推理序列,从而提高状态覆盖率。这样的设计旨在克服“浅层探索陷阱”,使模型能够在更广泛的状态空间中进行有效探索。
技术框架:整体方法包括两个主要阶段:首先,模型在生成过程中获得长度奖励,鼓励生成更长的推理轨迹;其次,应用冗余惩罚以避免生成重复的推理内容,从而优化状态覆盖。
关键创新:本研究的创新点在于将长度激励与冗余惩罚结合,形成一种新的奖励机制,显著提升了模型的探索能力,与传统方法相比,能够更有效地覆盖状态空间。
关键设计:在参数设置上,长度奖励和冗余惩罚的权重需要根据具体任务进行调节,以达到最佳效果。此外,模型结构需支持自回归生成,以便有效实施该激励机制。实验中使用了Qwen3和Llama等模型进行验证。
🖼️ 关键图片

📊 实验亮点
实验结果表明,长度激励探索方法在Qwen3和Llama模型上实现了显著的性能提升,领域内任务平均提升4.4%,领域外基准提升2.7%。这些结果验证了该方法在促进上下文探索方面的有效性,展示了其在实际应用中的潜力。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能对话系统和自动推理等。在这些领域中,模型需要在复杂的上下文中进行推理和决策,提升上下文探索能力将显著提高系统的智能水平和用户体验。未来,该方法有望推动更多智能应用的发展。
📄 摘要(原文)
Achieving effective test-time scaling requires models to engage in In-Context Exploration -- the intrinsic ability to generate, verify, and refine multiple reasoning hypotheses within a single continuous context. Grounded in State Coverage theory, our analysis identifies a critical bottleneck to enabling this capability: while broader state coverage requires longer reasoning trajectories, the probability of sampling such sequences decays exponentially during autoregressive generation, a phenomenon we term the ``Shallow Exploration Trap''. To bridge this gap, we propose Length-Incentivized Exploration(\method). This simple yet effective recipe explicitly encourages models to explore more via a length-based reward coupled with a redundancy penalty, thereby maximizing state coverage in two-step manner. Comprehensive experiments across different models (Qwen3, Llama) demonstrate that \method effectively incentivize in-context exploration. As a result, our method achieves an average improvement of 4.4\% on in-domain tasks and a 2.7\% gain on out-of-domain benchmarks.