Scene-Aware Memory Discrimination: Deciding Which Personal Knowledge Stays
作者: Yijie Zhong, Mengying Guo, Zewei Wang, Zhongyang Li, Dandan Tu, Haofen Wang
分类: cs.CL
发布日期: 2026-02-12
备注: Accepted by Knowledge-Based Systems. Lincense: CC BY-NC-ND
DOI: 10.1016/j.knosys.2026.115496
💡 一句话要点
提出场景感知记忆判别方法SAMD,解决LLM在个人知识管理中信息过滤和计算成本问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 记忆判别 大型语言模型 个人知识管理 场景感知 选择性注意
📋 核心要点
- 现有LLM在个人知识管理中面临信息过滤和计算成本上升的挑战。
- SAMD方法通过门控单元和聚类提示,模拟人类选择性注意机制,提升记忆效率。
- 实验表明SAMD能有效回忆关键信息,并在个性化应用中提升记忆构建的效率和质量。
📝 摘要(中文)
智能设备日益融入日常生活,产生大量用户交互数据,形成有价值的个人知识。高效组织这些知识对于实现个性化应用至关重要。然而,当前使用大型语言模型(LLM)进行记忆写入、管理和读取的研究面临着过滤无关信息和应对不断增长的计算成本的挑战。受人类大脑选择性注意概念的启发,我们引入了一个记忆判别任务。为了应对该任务中的大规模交互和多样化记忆标准,我们提出了一种场景感知记忆判别方法(SAMD),它包含两个关键组件:门控单元模块(GUM)和聚类提示模块(CPM)。GUM通过过滤掉非记忆性交互并专注于与应用需求最相关的显著内容来提高处理效率。CPM建立自适应记忆标准,引导LLM辨别应该记住或丢弃的信息。它还分析用户意图和记忆上下文之间的关系,以构建有效的聚类提示。全面的直接和间接评估证明了我们方法的有效性和泛化性。我们独立评估了记忆判别的性能,表明SAMD成功地回忆了大多数可记忆的数据,并在动态场景中保持稳健性。此外,当集成到个性化应用中时,SAMD显著提高了记忆构建的效率和质量,从而更好地组织个人知识。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理海量个人交互数据时,如何高效地进行记忆存储和管理的问题。现有的方法难以有效过滤无关信息,导致计算成本过高,并且缺乏自适应的记忆标准,无法根据场景和用户意图进行选择性记忆。
核心思路:论文的核心思路是模拟人类大脑的选择性注意机制,通过场景感知的方式,判断哪些信息应该被记忆,哪些信息应该被丢弃。通过这种方式,可以减少需要存储和处理的信息量,从而提高效率并降低计算成本。同时,根据用户意图和记忆上下文,动态调整记忆标准,实现更个性化的知识管理。
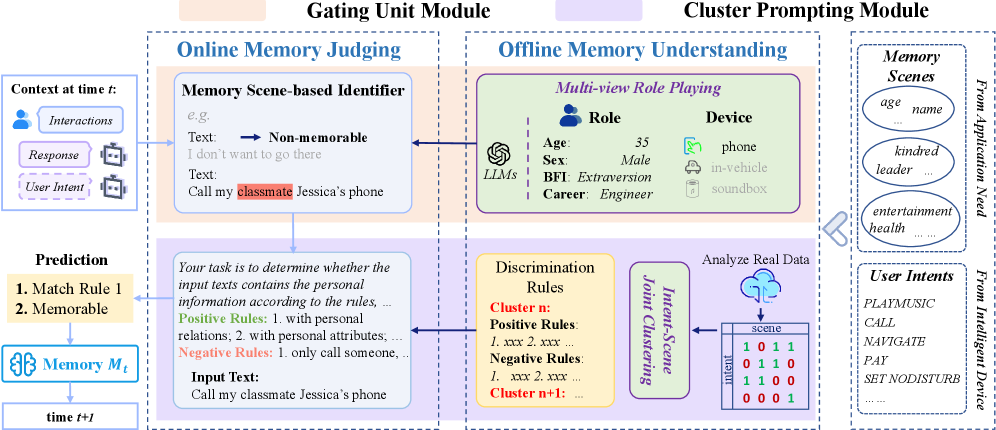
技术框架:SAMD方法包含两个主要模块:门控单元模块(GUM)和聚类提示模块(CPM)。GUM负责过滤掉非记忆性的交互信息,只保留与应用需求最相关的显著内容。CPM则负责建立自适应的记忆标准,并根据用户意图和记忆上下文生成聚类提示,引导LLM进行记忆判别。整体流程是,首先通过GUM过滤交互数据,然后利用CPM生成提示,最后由LLM根据提示进行记忆或丢弃的决策。
关键创新:SAMD的关键创新在于其场景感知的记忆判别能力。与以往方法不同,SAMD不是简单地存储所有信息,而是根据场景和用户意图,动态地选择性地记忆。这种方法更符合人类的认知方式,能够更有效地管理个人知识。此外,GUM和CPM的结合,使得SAMD能够同时关注信息的显著性和上下文关系,从而做出更准确的记忆判别。
关键设计:GUM的具体实现可能涉及注意力机制或门控循环单元(GRU),用于评估每个交互信息的重要性。CPM可能使用聚类算法(如K-means)对用户意图和记忆上下文进行聚类,并根据聚类结果生成提示。损失函数的设计可能包括记忆准确率和计算成本的平衡。具体的网络结构和参数设置在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SAMD方法能够成功回忆起大部分可记忆的数据,并在动态场景中保持稳健性。与传统方法相比,SAMD在记忆构建的效率和质量上都有显著提升。具体的性能数据和提升幅度在论文中可能有所体现,但摘要中未明确给出,属于未知信息。直接和间接评估都证明了SAMD的有效性和泛化性。
🎯 应用场景
该研究成果可应用于智能助手、个性化推荐系统、智能家居等领域。通过高效管理用户的个人知识,可以提升用户体验,实现更智能、更个性化的服务。例如,智能助手可以更好地理解用户的需求,提供更精准的建议;个性化推荐系统可以更准确地预测用户的兴趣,推荐更符合用户口味的内容。未来,该技术有望在教育、医疗等领域发挥更大的作用。
📄 摘要(原文)
Intelligent devices have become deeply integrated into everyday life, generating vast amounts of user interactions that form valuable personal knowledge. Efficient organization of this knowledge in user memory is essential for enabling personalized applications. However, current research on memory writing, management, and reading using large language models (LLMs) faces challenges in filtering irrelevant information and in dealing with rising computational costs. Inspired by the concept of selective attention in the human brain, we introduce a memory discrimination task. To address large-scale interactions and diverse memory standards in this task, we propose a Scene-Aware Memory Discrimination method (SAMD), which comprises two key components: the Gating Unit Module (GUM) and the Cluster Prompting Module (CPM). GUM enhances processing efficiency by filtering out non-memorable interactions and focusing on the salient content most relevant to application demands. CPM establishes adaptive memory standards, guiding LLMs to discern what information should be remembered or discarded. It also analyzes the relationship between user intents and memory contexts to build effective clustering prompts. Comprehensive direct and indirect evaluations demonstrate the effectiveness and generalization of our approach. We independently assess the performance of memory discrimination, showing that SAMD successfully recalls the majority of memorable data and remains robust in dynamic scenarios. Furthermore, when integrated into personalized applications, SAMD significantly enhances both the efficiency and quality of memory construction, leading to better organization of personal knowledge.