SIGHT: Reinforcement Learning with Self-Evidence and Information-Gain Diverse Branching for Search Agent
作者: Wenlin Zhong, Jinluan Yang, Yiquan Wu, Yi Liu, Jianhang Yao, Kun Kuang
分类: cs.CL
发布日期: 2026-02-12
💡 一句话要点
SIGHT:通过自证据和信息增益驱动的分支搜索增强LLM在复杂问答中的自主搜索能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 自主搜索 信息增益 多跳问答
📋 核心要点
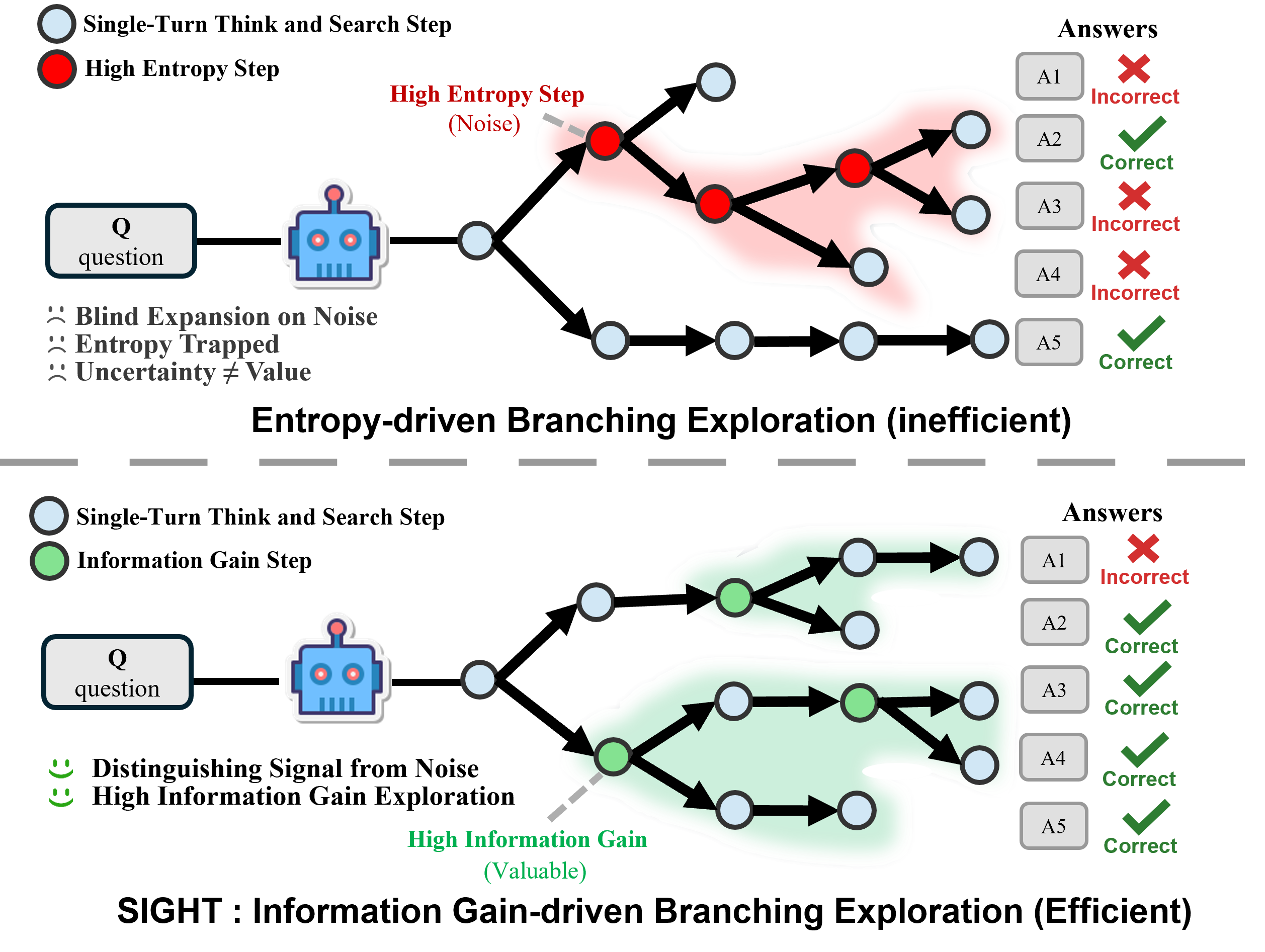
- 现有基于强化学习的LLM搜索方法在多轮交互中易受冗余信息和噪声干扰,导致“隧道视野”问题。
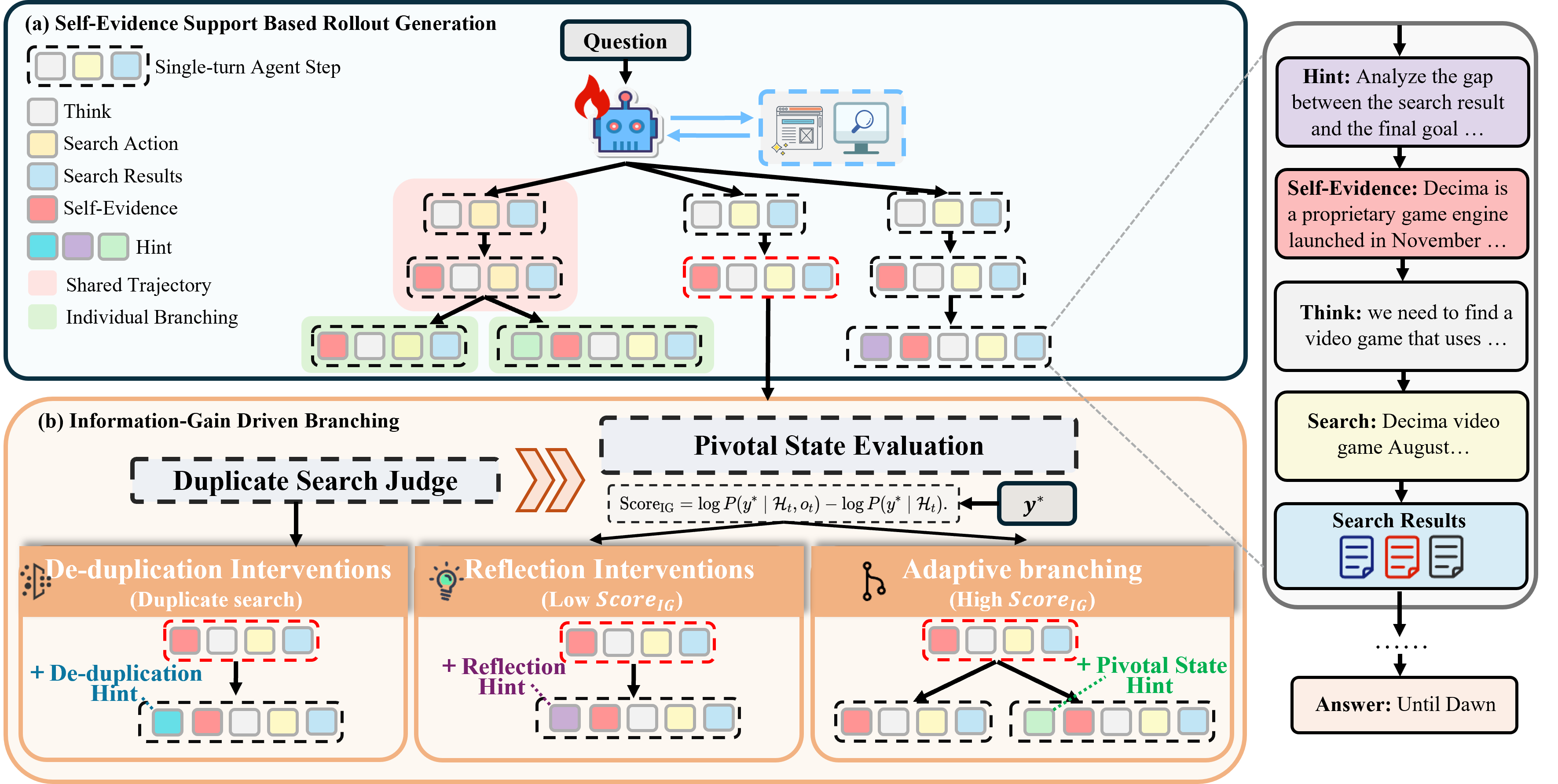
- SIGHT框架通过自证据支持(SES)提炼高质量证据,并利用信息增益指导动态提示干预,实现多样化分支探索。
- 实验表明,SIGHT在复杂推理场景中显著优于现有方法,且搜索步骤更少,无需外部验证器。
📝 摘要(中文)
强化学习(RL)已经使大型语言模型(LLM)能够掌握复杂问答的自主搜索。然而,特别是在多轮搜索场景中,这种交互引入了一个关键挑战:搜索结果通常存在高度冗余和低信噪比的问题。因此,智能体很容易陷入“隧道视野”,即对早期噪声检索的强制解释导致不可逆转的错误累积。为了解决这些挑战,我们提出了SIGHT,一个通过自证据支持(SES)和信息增益驱动的多样化分支来增强基于搜索的推理的框架。SIGHT通过SES将搜索结果提炼成高保真证据,并计算信息增益分数以精确定位观察结果最大限度地减少不确定性的关键状态。该分数指导动态提示干预——包括去重、反思或自适应分支——以产生具有SES的新分支。最后,通过Group Relative Policy Optimization整合SES和正确性奖励,SIGHT在没有外部验证器的情况下内化了强大的探索策略。在单跳和多跳QA基准上的实验表明,SIGHT显著优于现有方法,尤其是在复杂的推理场景中,并且使用的搜索步骤更少。
🔬 方法详解
问题定义:论文旨在解决基于强化学习的LLM在多轮搜索问答中遇到的“隧道视野”问题。现有方法在处理冗余和低信噪比的搜索结果时,容易陷入对早期噪声信息的过度依赖,导致错误累积,影响最终答案的准确性。这种现象尤其在需要复杂推理的多跳问答场景中更为突出。
核心思路:SIGHT的核心思路是通过引入自证据支持(SES)和信息增益驱动的多样化分支,来提高搜索结果的质量和探索效率。SES用于将搜索结果提炼成高保真证据,减少噪声干扰;信息增益则用于评估不同状态的重要性,指导智能体在关键状态进行动态提示干预,从而产生更多样化的搜索分支。
技术框架:SIGHT框架主要包含以下几个模块:1) 自证据支持(SES):将搜索结果提炼成高质量的证据表示。2) 信息增益计算:评估当前状态的不确定性,并计算信息增益分数。3) 动态提示干预:根据信息增益分数,对关键状态进行去重、反思或自适应分支等操作。4) Group Relative Policy Optimization:整合SES和正确性奖励,训练智能体学习鲁棒的探索策略。整体流程是,智能体根据当前状态进行搜索,SES提取证据,计算信息增益,根据信息增益进行动态提示干预,生成新的搜索分支,最终通过强化学习优化策略。
关键创新:SIGHT的关键创新在于将自证据支持和信息增益驱动的分支搜索相结合。自证据支持能够有效过滤噪声信息,提高证据质量;信息增益驱动的分支搜索则能够引导智能体在关键状态进行更有效的探索,避免陷入局部最优。与现有方法相比,SIGHT无需外部验证器,而是通过内部化的机制来学习鲁棒的探索策略。
关键设计:论文中关键的设计包括:1) 自证据支持(SES)的具体实现:如何将搜索结果转化为高保真证据,例如使用特定的模型或算法进行提炼。2) 信息增益的计算方法:如何量化当前状态的不确定性,并计算信息增益分数。3) 动态提示干预的策略:如何根据信息增益分数选择合适的干预方式,例如去重、反思或自适应分支。4) Group Relative Policy Optimization的具体实现:如何整合SES和正确性奖励,设计合适的奖励函数和优化算法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SIGHT在单跳和多跳QA基准上显著优于现有方法。例如,在复杂推理场景中,SIGHT的性能提升超过10%,并且使用的搜索步骤更少。此外,SIGHT无需外部验证器,而是通过内部化的机制来学习鲁棒的探索策略,这使得其更具实用性和可扩展性。
🎯 应用场景
SIGHT框架具有广泛的应用前景,可应用于智能问答系统、知识图谱推理、信息检索等领域。通过提高搜索结果的质量和探索效率,SIGHT能够帮助LLM更好地理解复杂问题,并给出更准确、更全面的答案。此外,SIGHT还可以应用于其他需要自主探索和推理的任务,例如机器人导航、游戏AI等。
📄 摘要(原文)
Reinforcement Learning (RL) has empowered Large Language Models (LLMs) to master autonomous search for complex question answering. However, particularly within multi-turn search scenarios, this interaction introduces a critical challenge: search results often suffer from high redundancy and low signal-to-noise ratios. Consequently, agents easily fall into "Tunnel Vision," where the forced interpretation of early noisy retrievals leads to irreversible error accumulation. To address these challenges, we propose SIGHT, a framework that enhances search-based reasoning through Self-Evidence Support (SES) and Information-Gain Driven Diverse Branching. SIGHT distills search results into high-fidelity evidence via SES and calculates an Information Gain score to pinpoint pivotal states where observations maximally reduce uncertainty. This score guides Dynamic Prompting Interventions - including de-duplication, reflection, or adaptive branching - to spawn new branches with SES. Finally, by integrating SES and correctness rewards via Group Relative Policy Optimization, SIGHT internalizes robust exploration strategies without external verifiers. Experiments on single-hop and multi-hop QA benchmarks demonstrate that SIGHT significantly outperforms existing approaches, particularly in complex reasoning scenarios, using fewer search steps.