Pretraining A Large Language Model using Distributed GPUs: A Memory-Efficient Decentralized Paradigm
作者: Jinrui Zhang, Chaodong Xiao, Aoqi Wu, Xindong Zhang, Lei Zhang
分类: cs.CL
发布日期: 2026-02-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出SPES框架,解决MoE LLM在低显存GPU上的分布式预训练难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 混合专家模型 分布式训练 去中心化学习 低资源训练
📋 核心要点
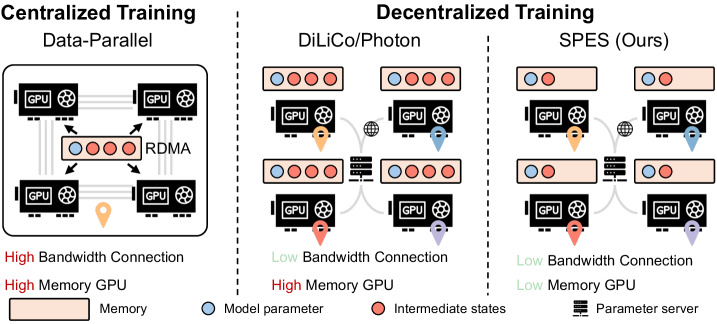
- 现有去中心化训练方法仍需在每个节点上训练完整模型,受限于GPU内存。预训练大型MoE模型需要大量高显存GPU,成本高昂。
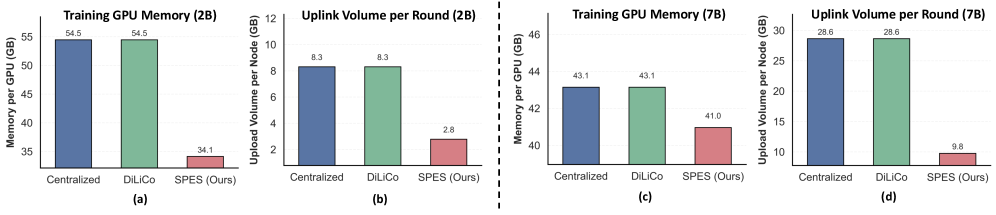
- SPES框架仅在每个节点训练部分专家,降低内存占用,并通过专家同步实现知识共享,避免全参数传输,提升训练效率。
- 实验表明,SPES框架在低显存GPU上训练的MoE模型性能与集中式训练模型相当,并展现出良好的可扩展性。
📝 摘要(中文)
本文提出了一种名为稀疏专家同步(SPES)的内存高效的去中心化框架,用于预训练混合专家(MoE)大型语言模型(LLM)。SPES仅在每个节点上训练一部分专家,从而显著降低了内存占用。每个节点更新其本地专家,并定期与其他节点同步,消除了完整参数传输,同时确保了高效的知识共享。为了加速收敛,我们引入了一种专家合并预热策略,在该策略中,专家在训练早期交换知识,以快速建立基础能力。借助SPES,我们使用16个独立的48GB GPU通过互联网连接训练了一个20亿参数的MoE LLM,在相似的计算预算下,该模型实现了与集中式训练的LLM相当的性能。我们进一步通过从头开始训练一个70亿参数的模型以及从密集检查点升级改造一个90亿参数的模型来证明了可扩展性,这两个模型都与先前的集中式基线相匹配。我们的代码可在https://github.com/zjr2000/SPES上找到。
🔬 方法详解
问题定义:论文旨在解决大型混合专家(MoE)语言模型在资源受限的分布式环境下的预训练问题。现有去中心化训练方法虽然降低了通信开销,但仍然需要在每个节点上存储和训练整个模型,这对于显存有限的GPU来说是一个巨大的挑战。因此,如何在低显存GPU上高效地预训练大型MoE模型是本文要解决的核心问题。
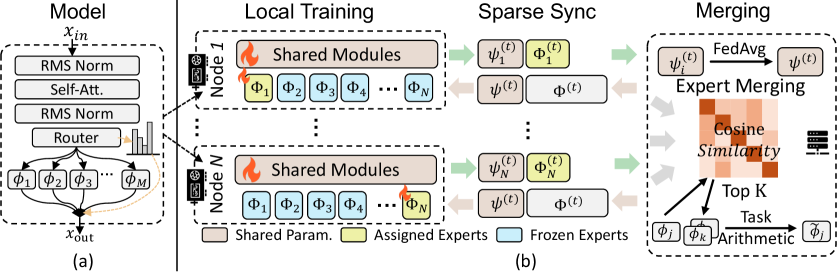
核心思路:论文的核心思路是利用MoE模型的稀疏性,只在每个节点上训练一部分专家,从而显著降低内存占用。通过周期性的专家同步,不同节点上的专家可以互相学习,从而实现知识共享,避免模型性能下降。这种方法避免了全参数传输,降低了通信开销,使得在低显存GPU上训练大型MoE模型成为可能。
技术框架:SPES框架包含以下几个主要模块:1) 局部专家训练:每个节点只训练一部分专家,并使用标准的反向传播算法更新这些专家的参数。2) 专家同步:节点之间定期交换专家参数,实现知识共享。3) 专家合并预热:在训练初期,专家之间进行更频繁的知识交换,以加速模型的收敛。整个流程是去中心化的,不需要中心服务器协调。
关键创新:SPES框架的关键创新在于稀疏专家训练和专家同步机制。与传统的去中心化训练方法相比,SPES不需要在每个节点上训练整个模型,从而显著降低了内存占用。专家同步机制保证了不同节点上的专家可以互相学习,避免了模型性能下降。专家合并预热策略进一步加速了模型的收敛。
关键设计:专家同步的频率是一个关键参数,需要根据具体的硬件环境和模型大小进行调整。专家合并预热策略中,知识交换的频率和方式也需要仔细设计。论文中使用了简单的平均参数的方式进行专家合并。损失函数采用标准的语言模型损失函数,例如交叉熵损失。
🖼️ 关键图片
📊 实验亮点
SPES框架使用16个48GB GPU训练了一个20亿参数的MoE LLM,性能与集中式训练模型相当。通过从头开始训练一个70亿参数的模型以及从密集检查点升级改造一个90亿参数的模型,验证了SPES框架的可扩展性,并且性能与先前的集中式基线相匹配。这些结果表明SPES框架在低成本硬件上训练大型LLM具有显著优势。
🎯 应用场景
该研究成果可应用于资源受限环境下的LLM预训练,例如在边缘设备或个人工作站上训练定制化LLM。它降低了LLM训练的硬件门槛,使得更多研究者和开发者能够参与到LLM的研究和应用中。此外,该方法还可以用于联邦学习场景,保护用户隐私的同时,实现模型的分布式训练。
📄 摘要(原文)
Pretraining large language models (LLMs) typically requires centralized clusters with thousands of high-memory GPUs (e.g., H100/A100). Recent decentralized training methods reduce communication overhead by employing federated optimization; however, they still need to train the entire model on each node, remaining constrained by GPU memory limitations. In this work, we propose SParse Expert Synchronization (SPES), a memory-efficient decentralized framework for pretraining mixture-of-experts (MoE) LLMs. SPES trains only a subset of experts per node, substantially lowering the memory footprint. Each node updates its local experts and periodically synchronizes with other nodes, eliminating full-parameter transmission while ensuring efficient knowledge sharing. To accelerate convergence, we introduce an expert-merging warm-up strategy, where experts exchange knowledge early in training, to rapidly establish foundational capabilities. With SPES, we train a 2B-parameter MoE LLM using 16 standalone 48GB GPUs over internet connections, which achieves competitive performance with centrally trained LLMs under similar computational budgets. We further demonstrate scalability by training a 7B model from scratch and a 9B model upcycled from a dense checkpoint, both of which match prior centralized baselines. Our code is available at https://github.com/zjr2000/SPES.