Jailbreaking Leaves a Trace: Understanding and Detecting Jailbreak Attacks from Internal Representations of Large Language Models
作者: Sri Durga Sai Sowmya Kadali, Evangelos E. Papalexakis
分类: cs.CR, cs.CL
发布日期: 2026-02-12
💡 一句话要点
提出基于张量分解的隐空间分析框架,用于检测和防御大语言模型的越狱攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 越狱攻击 安全防御 隐空间分析 张量分解 主动防御 推理优化
📋 核心要点
- 现有大语言模型防御越狱攻击的方法依赖于提示级别的防御,但攻击者不断开发新的攻击策略,模型依然脆弱。
- 该论文提出一种基于张量的隐空间表示框架,通过分析模型内部表示的差异来检测和防御越狱攻击。
- 实验表明,该方法可以在推理时有效阻止越狱攻击,同时保持良性行为,且开销很小,具有良好的可扩展性。
📝 摘要(中文)
大型语言模型(LLMs)的越狱攻击已成为会话式AI系统广泛部署面临的关键安全挑战。对抗性用户通过精心设计的提示来利用这些模型,以引出受限或不安全的输出,这种现象通常被称为越狱。尽管已经提出了许多防御机制,但攻击者仍在不断开发自适应提示策略,并且现有模型仍然容易受到攻击。本文从安全和可解释性的角度研究越狱,通过分析越狱提示和良性提示之间的内部表示差异。对GPT-J、LLaMA、Mistral和状态空间模型Mamba等多个开源模型进行了系统的分层分析,并识别出与有害输入相关的潜在空间模式。然后,提出了一个基于张量的潜在表示框架,该框架捕获隐藏激活中的结构,并实现轻量级的越狱检测,而无需模型微调或基于辅助LLM的检测器。进一步证明,潜在信号可用于在推理时主动中断越狱执行。在一个被消融的LLaMA-3.1-8B模型上,选择性地绕过高敏感性层可以阻止78%的越狱尝试,同时保持94%的良性提示的良性行为。这种干预完全在推理时进行,并且引入的开销最小,为通过结合额外的攻击分布或更精细的敏感性阈值来实现更强的覆盖率提供了可扩展的基础。研究结果表明,越狱行为植根于可识别的内部结构,并为改进LLM安全性提出了一个互补的、与架构无关的方向。
🔬 方法详解
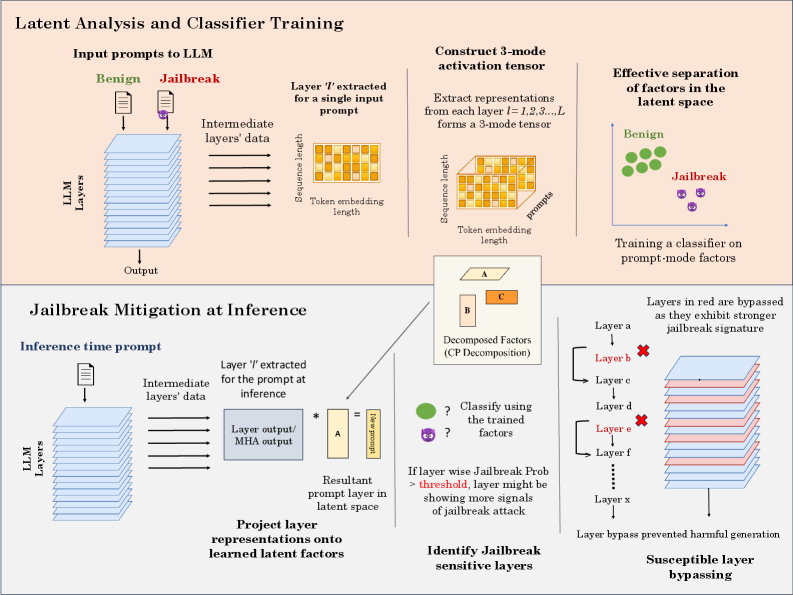
问题定义:当前大语言模型面临严重的越狱攻击威胁,攻击者通过构造恶意prompt诱导模型产生有害输出。现有的防御方法主要集中在prompt层面,容易被绕过,缺乏对模型内部行为的深入理解。因此,需要一种更鲁棒、更深入的防御机制,能够从模型内部识别并阻止越狱行为。
核心思路:该论文的核心思路是,越狱攻击会在大语言模型的内部表示中留下可识别的痕迹。通过分析良性prompt和越狱prompt在模型各层的激活值差异,可以发现与越狱行为相关的潜在空间模式。利用这些模式,可以构建检测器来识别越狱攻击,甚至可以在推理时主动干预模型的执行,阻止有害输出的产生。
技术框架:该方法主要包含以下几个阶段:1) 数据收集:收集良性和越狱prompt,并记录它们在模型各层的激活值。2) 隐空间分析:使用张量分解等方法分析各层激活值的结构,提取与越狱行为相关的特征。3) 越狱检测:基于提取的特征,构建分类器来区分良性和越狱prompt。4) 主动防御:在推理时,根据各层激活值的敏感性,选择性地绕过或修改某些层的计算,以阻止越狱攻击。
关键创新:该论文的关键创新在于:1) 提出了一种基于张量的隐空间表示框架,能够有效地捕获大语言模型内部的越狱行为模式。2) 提出了一种主动防御机制,可以在推理时干预模型的执行,阻止越狱攻击,而无需重新训练模型。3) 该方法具有架构无关性,可以应用于不同的Transformer模型。
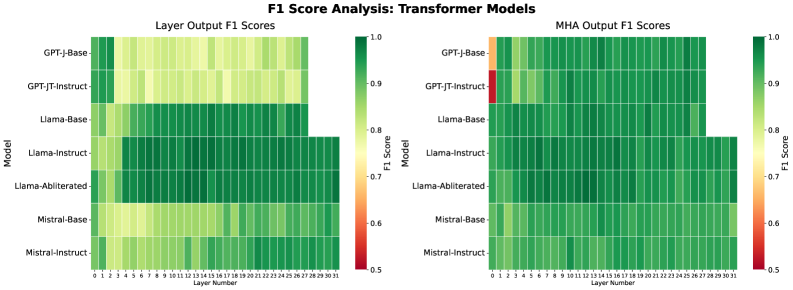
关键设计:在隐空间分析阶段,使用了CP分解(CANDECOMP/PARAFAC decomposition)对各层的激活张量进行分解,提取潜在的语义信息。在主动防御阶段,通过计算各层激活值的敏感性得分,确定需要绕过的层。敏感性得分的计算方式是基于越狱prompt和良性prompt激活值之间的差异。在LLaMA-3.1-8B模型上,选择性地绕过高敏感性层。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法可以在被消融的LLaMA-3.1-8B模型上,选择性地绕过高敏感性层,阻止78%的越狱尝试,同时保持94%的良性提示的良性行为。这种干预完全在推理时进行,并且引入的开销最小,为实现更强的覆盖率提供了可扩展的基础。
🎯 应用场景
该研究成果可应用于提升大语言模型的安全性,防止其被用于生成有害信息。该方法可以集成到现有的LLM服务中,作为一种额外的防御层,用于检测和阻止越狱攻击。此外,该研究也为理解LLM的内部行为提供了新的视角,有助于开发更安全、更可靠的AI系统。
📄 摘要(原文)
Jailbreaking large language models (LLMs) has emerged as a critical security challenge with the widespread deployment of conversational AI systems. Adversarial users exploit these models through carefully crafted prompts to elicit restricted or unsafe outputs, a phenomenon commonly referred to as Jailbreaking. Despite numerous proposed defense mechanisms, attackers continue to develop adaptive prompting strategies, and existing models remain vulnerable. This motivates approaches that examine the internal behavior of LLMs rather than relying solely on prompt-level defenses. In this work, we study jailbreaking from both security and interpretability perspectives by analyzing how internal representations differ between jailbreak and benign prompts. We conduct a systematic layer-wise analysis across multiple open-source models, including GPT-J, LLaMA, Mistral, and the state-space model Mamba, and identify consistent latent-space patterns associated with harmful inputs. We then propose a tensor-based latent representation framework that captures structure in hidden activations and enables lightweight jailbreak detection without model fine-tuning or auxiliary LLM-based detectors. We further demonstrate that the latent signals can be used to actively disrupt jailbreak execution at inference time. On an abliterated LLaMA-3.1-8B model, selectively bypassing high-susceptibility layers blocks 78% of jailbreak attempts while preserving benign behavior on 94% of benign prompts. This intervention operates entirely at inference time and introduces minimal overhead, providing a scalable foundation for achieving stronger coverage by incorporating additional attack distributions or more refined susceptibility thresholds. Our results provide evidence that jailbreak behavior is rooted in identifiable internal structures and suggest a complementary, architecture-agnostic direction for improving LLM security.