Data Repetition Beats Data Scaling in Long-CoT Supervised Fine-Tuning
作者: Dawid J. Kopiczko, Sagar Vaze, Tijmen Blankevoort, Yuki M. Asano
分类: cs.CL
发布日期: 2026-02-11
💡 一句话要点
长CoT监督微调中,数据重复优于数据扩增
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 监督微调 链式思考 数据重复 大型语言模型 推理能力
📋 核心要点
- 现有方法依赖大规模数据集进行监督微调,成本高昂且效果提升不明显。
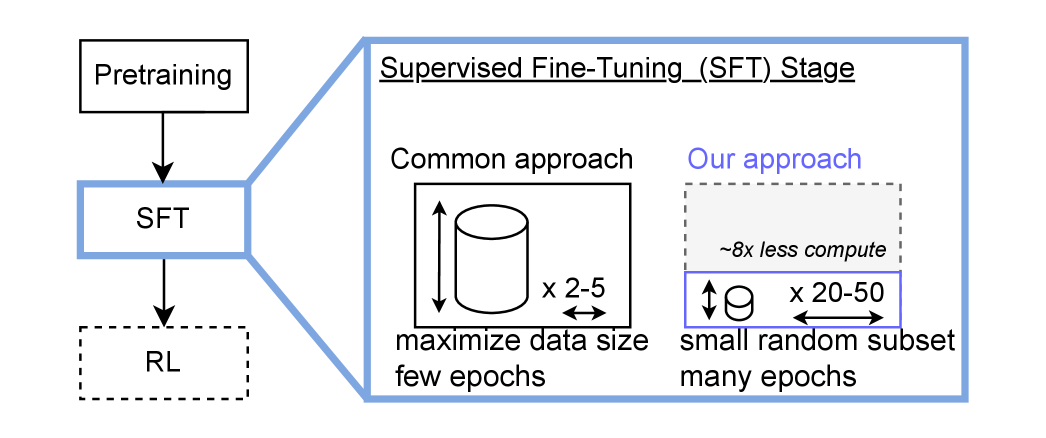
- 论文提出重复训练策略,即在小数据集上进行多轮训练,以提高模型性能。
- 实验表明,重复训练在推理任务上显著优于单轮大数据集训练,且无灾难性遗忘。
📝 摘要(中文)
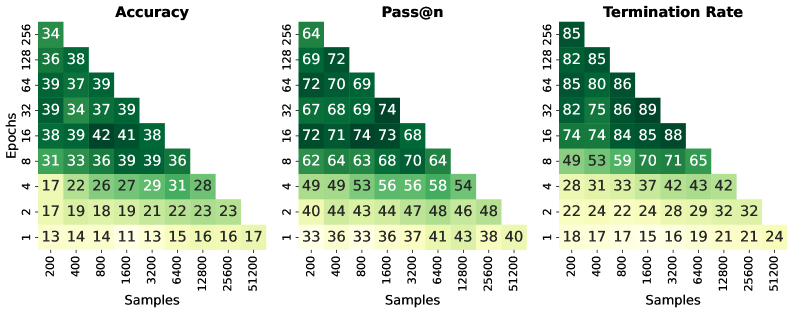
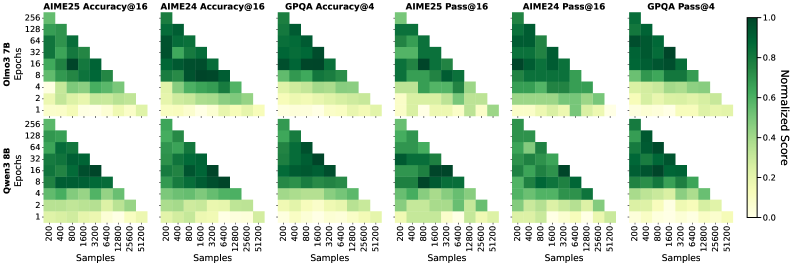
在链式思考(CoT)数据上进行监督微调(SFT)是推理语言模型的重要训练后步骤。标准的机器学习直觉表明,使用更多独特的训练样本进行训练会产生更好的泛化效果。但与直觉相反,本文表明SFT受益于数据重复:在固定的更新预算下,在较小的数据集上训练更多epoch优于在较大的数据集上进行单epoch训练。在AIME'24/25和GPQA基准测试中,使用400个样本训练128个epoch的Olmo3-7B,比使用51200个样本训练1个epoch的模型性能高出12-26个百分点,且没有额外的灾难性遗忘。研究发现,token准确率能够可靠地指示重复训练何时达到饱和;当完全记忆时,额外epoch带来的改进趋于平稳,这种模式在所有设置中都是一致的。这些发现为推理SFT提供了一种实用的方法,其中将epoch与token准确率作为停止标准,可以取代昂贵的无向数据扩增。本文提出了重复优势,即完全记忆与改进的泛化能力同时发生,这是一个新的开放问题,旨在让社区理解大型语言模型的训练动态。
🔬 方法详解
问题定义:论文旨在解决在链式思考(CoT)监督微调(SFT)中,如何更有效地利用有限的数据资源来提升大型语言模型(LLM)的推理能力的问题。现有方法通常依赖于大规模数据集的单轮训练,但这种方法成本高昂,且边际效益递减。此外,简单地增加数据集规模并不一定能带来显著的性能提升,反而可能引入噪声或冗余信息,影响模型的泛化能力。
核心思路:论文的核心思路是利用数据重复(Data Repetition)策略,即在较小规模的数据集上进行多轮训练。作者认为,通过重复训练,模型可以更充分地学习和记忆数据集中的信息,从而提高其推理能力。这种方法的关键在于,在达到完全记忆(Full Memorization)之前,重复训练可以持续提升模型性能。
技术框架:论文的技术框架主要包括以下几个步骤:1)选择一个预训练的LLM(如Olmo3-7B);2)准备一个相对较小的CoT数据集;3)使用标准SFT方法,在数据集上进行多轮训练;4)使用token准确率作为停止标准,当token准确率达到饱和时,停止训练;5)在推理基准(如AIME'24/25和GPQA)上评估模型性能。
关键创新:论文最重要的技术创新点在于发现了数据重复在SFT中的优势。与传统的机器学习直觉相反,论文表明,在固定的计算资源下,重复训练小数据集比单轮训练大数据集更有效。此外,论文还提出了使用token准确率作为停止标准的实用方法,可以避免过度训练,并节省计算资源。
关键设计:论文的关键设计包括:1)选择合适的重复次数(epoch),通过token准确率监控训练过程,当token准确率达到饱和时停止训练;2)使用标准的SFT方法进行训练,没有引入额外的正则化或优化技巧;3)在多个推理基准上进行评估,以验证数据重复策略的泛化能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在AIME'24/25和GPQA基准测试中,使用400个样本训练128个epoch的Olmo3-7B,比使用51200个样本训练1个epoch的模型性能高出12-26个百分点。这表明数据重复策略在推理任务上具有显著优势,且没有观察到灾难性遗忘。
🎯 应用场景
该研究成果可应用于各种需要进行链式思考的语言模型微调任务,例如问答系统、科学推理、数学问题求解等。通过重复训练小规模高质量数据集,可以显著降低训练成本,提高模型性能,并加速LLM在实际场景中的部署。
📄 摘要(原文)
Supervised fine-tuning (SFT) on chain-of-thought data is an essential post-training step for reasoning language models. Standard machine learning intuition suggests that training with more unique training samples yields better generalization. Counterintuitively, we show that SFT benefits from repetition: under a fixed update budget, training for more epochs on smaller datasets outperforms single-epoch training on larger datasets. On AIME'24/25 and GPQA benchmarks, Olmo3-7B trained for 128 epochs on 400 samples outperforms the equivalent 1 epoch on 51200 samples by 12-26 percentage points, with no additional catastrophic forgetting. We find that training token accuracy reliably signals when repetition has saturated; improvements from additional epochs plateau at full memorization, a pattern consistent across all settings. These findings provide a practical approach for reasoning SFT, where scaling epochs with token accuracy as a stopping criterion can replace expensive undirected data scaling. We pose the repetition advantage, where full memorization coincides with improved generalization, as a new open problem for the community in understanding the training dynamics of large language models.