Safety Recovery in Reasoning Models Is Only a Few Early Steering Steps Away
作者: Soumya Suvra Ghosal, Souradip Chakraborty, Vaibhav Singh, Furong Huang, Dinesh Manocha, Amrit Singh Bedi
分类: cs.CL, cs.AI
发布日期: 2026-02-11
💡 一句话要点
SafeThink:通过早期引导步骤实现推理模型中的安全性恢复
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全性恢复 推理模型 越狱攻击 安全对齐 推理时防御
📋 核心要点
- 现有基于强化学习的推理模型后训练方法,虽然提升了推理能力,但降低了安全性,增加了越狱风险。
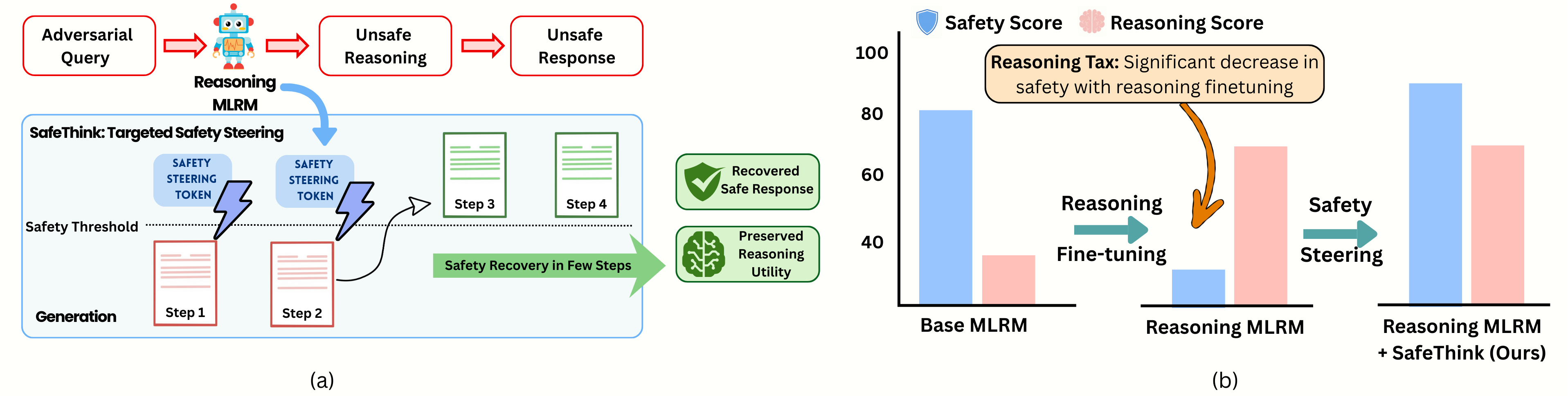
- SafeThink通过监控推理过程,在安全阈值被违反时,注入优化的安全前缀,引导模型回到安全状态。
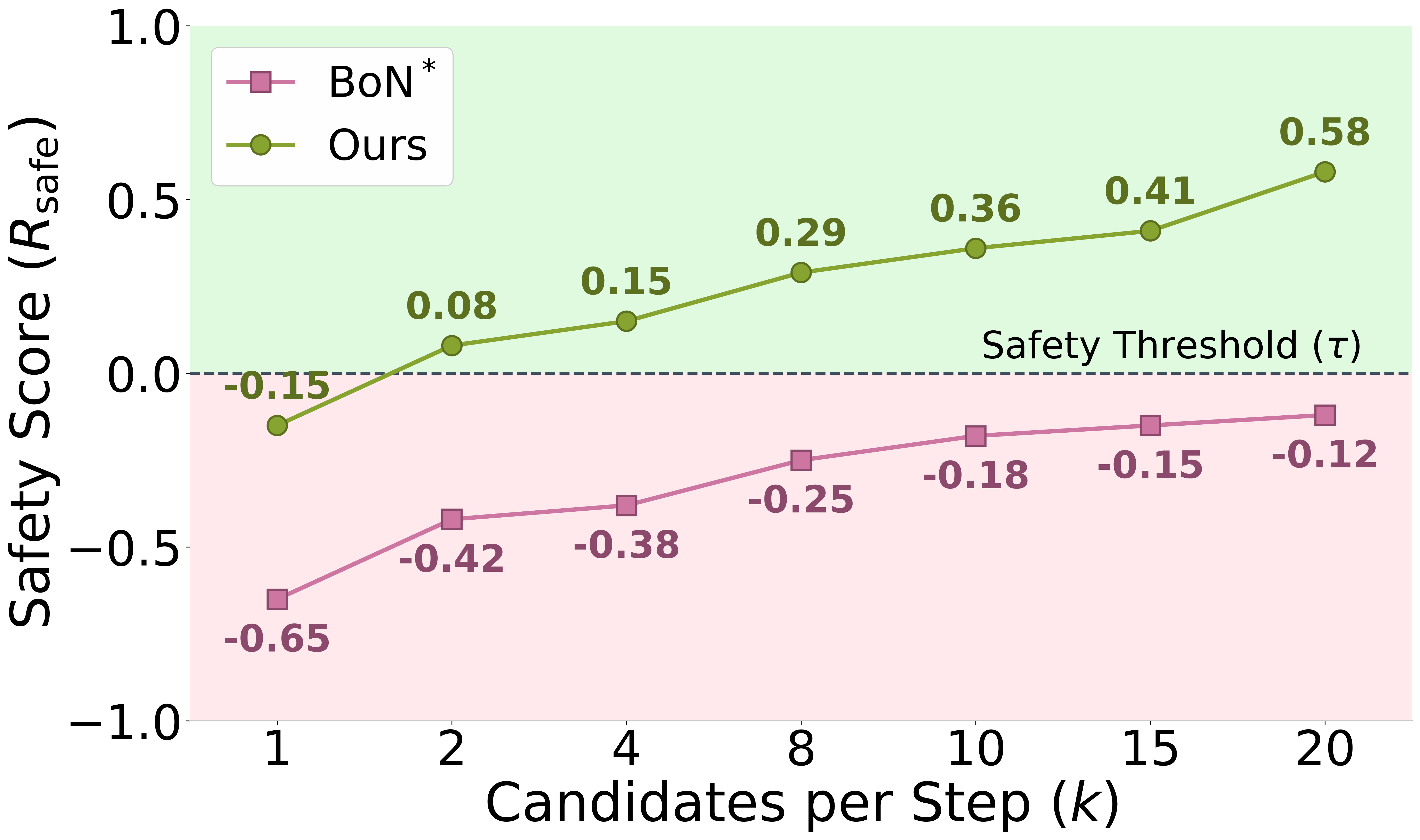
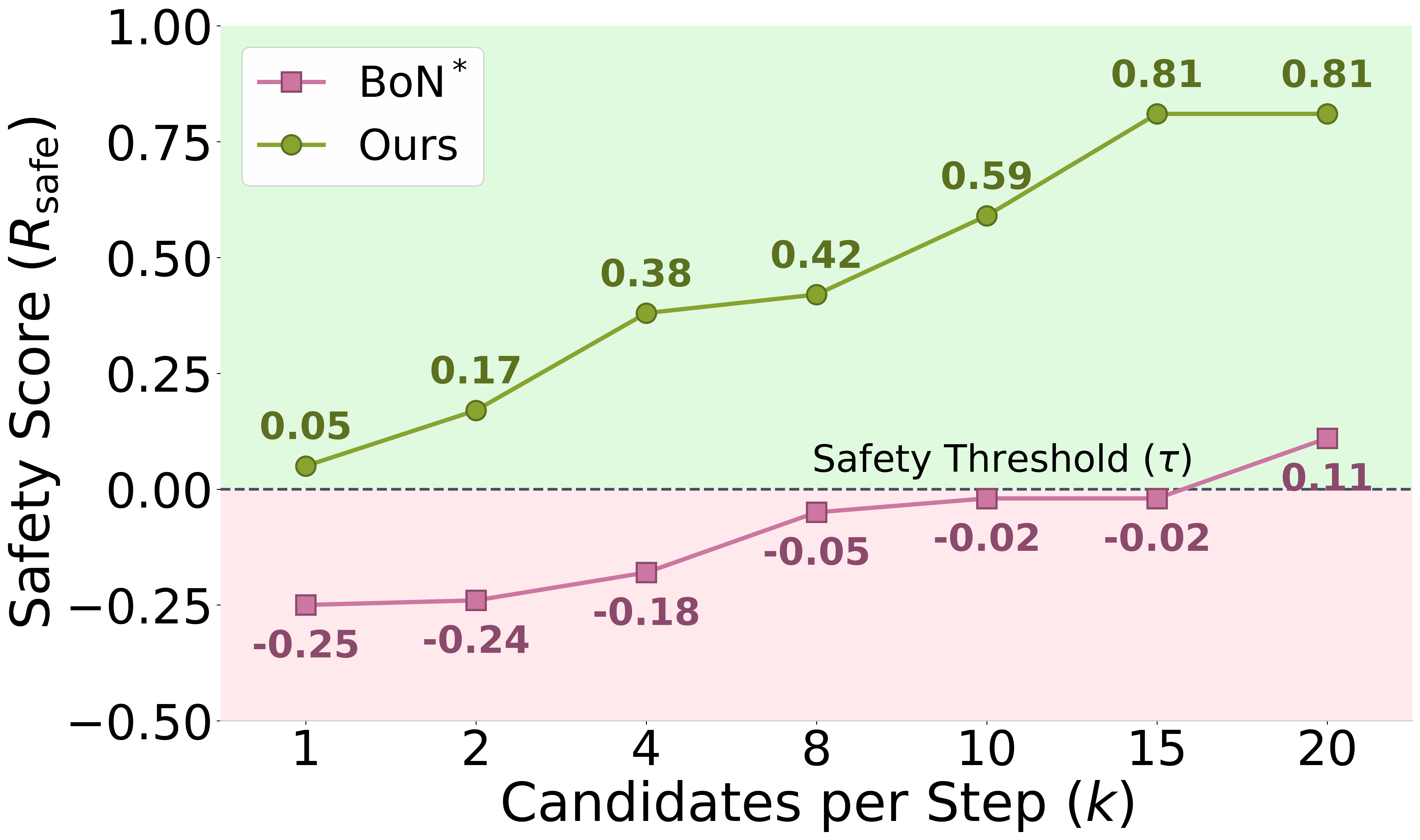
- 实验表明,SafeThink能显著降低攻击成功率,同时保持推理性能,且安全性恢复通常只需少量早期引导步骤。
📝 摘要(中文)
基于强化学习的后训练方法(如GRPO)可以提高多模态大型推理模型(MLRMs)的推理能力,但同时也可能降低安全对齐并增加越狱成功率。本文提出SafeThink,一种轻量级的推理时防御方法,将安全性恢复视为一个满足约束而非最大化目标的问题。SafeThink使用安全奖励模型监控推理过程,并在安全阈值被违反时有条件地注入优化的短修正前缀(“等等,安全地思考”)。在六个开源MLRM和四个越狱基准测试(JailbreakV-28K、Hades、FigStep和MM-SafetyBench)上的评估表明,SafeThink将攻击成功率降低了30-60%(例如,在JailbreakV-28K上,LlamaV-o1从63.33%降至5.74%;在Hades上,R1-Onevision从69.07%降至5.65%),同时保持了推理性能(MathVista准确率从65.20%降至65.00%)。实验的一个关键发现是,安全性恢复通常只需要几个引导步骤:干预前1-3个推理步骤通常足以将整个生成过程重定向到安全的完成。
🔬 方法详解
问题定义:论文旨在解决多模态大型推理模型(MLRMs)在经过强化学习后训练后,推理能力提升的同时,安全性降低,容易受到越狱攻击的问题。现有方法在追求推理性能的同时,忽略了安全性,导致模型在某些情况下会生成不安全或有害的内容。
核心思路:SafeThink的核心思路是将安全性恢复视为一个满足约束而非最大化目标的问题。它不试图最大化安全奖励,而是确保模型在推理过程中保持在安全阈值之上。通过在推理过程中监控模型的行为,并在检测到安全风险时及时干预,SafeThink能够有效地防止模型生成不安全的内容。
技术框架:SafeThink的技术框架主要包括以下几个模块:1) 安全奖励模型:用于评估模型在推理过程中的安全性。2) 安全阈值:用于判断模型是否处于安全状态。3) 修正前缀生成器:用于生成优化的安全前缀,引导模型回到安全状态。4) 推理引擎:用于执行模型的推理过程,并在必要时注入修正前缀。整体流程是,推理引擎生成推理步骤,安全奖励模型评估安全性,如果低于阈值,则注入修正前缀,继续推理。
关键创新:SafeThink最重要的技术创新点在于其轻量级的推理时防御机制。与传统的安全对齐方法相比,SafeThink不需要重新训练模型,而是通过在推理过程中进行干预来实现安全性恢复。此外,SafeThink还发现,安全性恢复通常只需要几个早期的引导步骤,这大大降低了干预的成本。
关键设计:SafeThink的关键设计包括:1) 安全奖励模型的选择和训练:需要选择一个能够准确评估模型安全性的奖励模型。2) 安全阈值的设定:需要根据具体的应用场景和安全需求来设定合适的安全阈值。3) 修正前缀的优化:需要设计一种能够有效地引导模型回到安全状态的修正前缀。论文中使用了“Wait, think safely”作为修正前缀,并进行了优化。
🖼️ 关键图片
📊 实验亮点
SafeThink在六个开源MLRM和四个越狱基准测试中表现出色。例如,在JailbreakV-28K上,LlamaV-o1的攻击成功率从63.33%降至5.74%;在Hades上,R1-Onevision的攻击成功率从69.07%降至5.65%。同时,SafeThink几乎没有降低推理性能,MathVista准确率仅从65.20%降至65.00%。实验还表明,安全性恢复通常只需要前1-3个推理步骤的干预。
🎯 应用场景
SafeThink可应用于各种需要安全保障的AI推理场景,例如智能客服、内容生成、医疗诊断等。通过提高模型的安全性,SafeThink可以降低模型被恶意利用的风险,并增强用户对AI系统的信任。未来,SafeThink可以进一步扩展到其他类型的AI模型和应用场景,为AI安全提供更全面的保障。
📄 摘要(原文)
Reinforcement learning (RL) based post-training for explicit chain-of-thought (e.g., GRPO) improves the reasoning ability of multimodal large-scale reasoning models (MLRMs). But recent evidence shows that it can simultaneously degrade safety alignment and increase jailbreak success rates. We propose SafeThink, a lightweight inference-time defense that treats safety recovery as a satisficing constraint rather than a maximization objective. SafeThink monitors the evolving reasoning trace with a safety reward model and conditionally injects an optimized short corrective prefix ("Wait, think safely") only when the safety threshold is violated. In our evaluations across six open-source MLRMs and four jailbreak benchmarks (JailbreakV-28K, Hades, FigStep, and MM-SafetyBench), SafeThink reduces attack success rates by 30-60% (e.g., LlamaV-o1: 63.33% to 5.74% on JailbreakV-28K, R1-Onevision: 69.07% to 5.65% on Hades) while preserving reasoning performance (MathVista accuracy: 65.20% to 65.00%). A key empirical finding from our experiments is that safety recovery is often only a few steering steps away: intervening in the first 1-3 reasoning steps typically suffices to redirect the full generation toward safe completions.