DataChef: Cooking Up Optimal Data Recipes for LLM Adaptation via Reinforcement Learning
作者: Yicheng Chen, Zerun Ma, Xinchen Xie, Yining Li, Kai Chen
分类: cs.CL, cs.AI
发布日期: 2026-02-11
💡 一句话要点
DataChef:通过强化学习自动生成LLM适配的最佳数据配方
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据配方 强化学习 自动化 模型微调 数据增强 端到端优化
📋 核心要点
- 现有LLM数据配方设计依赖人工,耗时耗力,缺乏自动化方法。
- 提出DataChef,利用强化学习自动生成数据配方,优化LLM在特定任务上的性能。
- DataChef-32B在多个任务上生成了与专家相当的配方,并在数学领域超越了基线模型。
📝 摘要(中文)
在大语言模型(LLM)领域,大规模、高质量训练数据的管理是提升模型性能的关键驱动力。其中,数据配方至关重要,它包含将原始数据源转换为训练语料库的数据处理流程。尽管LLM越来越多地用于自动化数据合成和过滤等数据处理步骤,但数据配方的整体设计仍然很大程度上依赖于手动和劳动密集型的方式,需要大量的人工专业知识和迭代。为了弥补这一差距,我们提出了用于LLM适配的端到端数据配方生成方法。给定目标基准和可用的数据源池,模型需要输出一个完整的数据配方,使基础LLM适应目标任务。我们提出了DataChef-32B,它使用代理奖励进行在线强化学习,以预测候选配方的下游性能。在六个保留任务中,DataChef-32B生成了实用的配方,其下游性能与人工专家策划的配方相当。值得注意的是,DataChef-32B的配方使Qwen3-1.7B-Base适应数学领域,在AIME'25上达到66.7,超过了Qwen3-1.7B。这项工作为自动化LLM训练和开发自我进化的AI系统提供了新的思路。
🔬 方法详解
问题定义:论文旨在解决LLM微调过程中数据配方设计的自动化问题。当前,数据配方的构建依赖于人工经验,需要大量的人工干预和迭代,效率低下且难以保证最优性。现有的自动化方法通常只关注数据处理流程中的单个步骤,缺乏端到端的优化。
核心思路:论文的核心思路是将数据配方生成过程建模为一个强化学习问题。通过定义合适的状态空间、动作空间和奖励函数,训练一个智能体自动探索和优化数据配方,以最大化LLM在目标任务上的性能。这种方法能够实现端到端的优化,避免了人工设计的局限性。
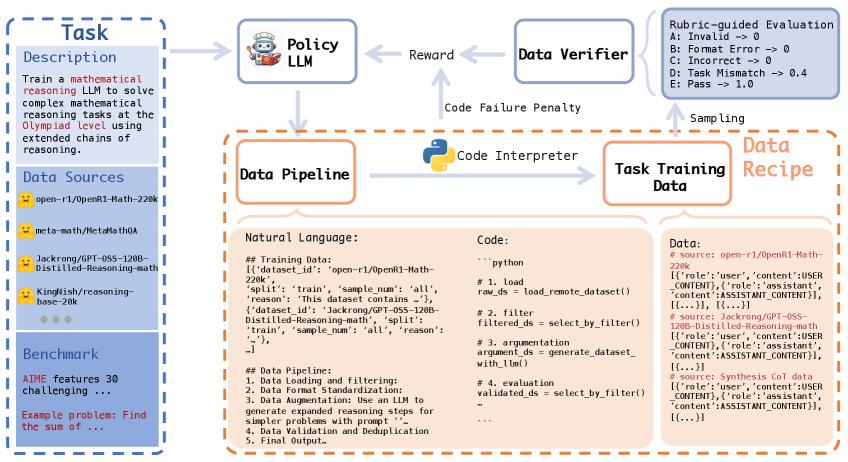
技术框架:DataChef的技术框架主要包括以下几个模块:1) 数据源池:包含各种可用的原始数据源;2) 数据处理操作库:包含各种数据处理操作,如数据合成、过滤、转换等;3) 强化学习智能体:负责生成数据配方,并根据奖励信号进行学习;4) 代理奖励模型:用于预测候选配方的下游性能,作为强化学习的奖励信号;5) 目标LLM:接受数据配方生成的训练数据,并在目标任务上进行评估。
关键创新:论文的关键创新在于将数据配方生成问题建模为一个端到端的强化学习问题,并提出了DataChef-32B模型。与现有方法相比,DataChef能够自动探索和优化整个数据配方,而不仅仅是单个数据处理步骤。此外,论文还提出了使用代理奖励模型来加速强化学习过程,避免了直接在目标LLM上进行评估的昂贵计算。
关键设计:DataChef-32B使用Transformer架构作为强化学习智能体,状态空间包括当前数据配方、数据源信息和目标任务信息,动作空间包括各种数据处理操作。奖励函数基于代理奖励模型预测的下游性能。代理奖励模型使用少量数据进行训练,以快速预测候选配方的性能。论文还探索了不同的强化学习算法,如PPO,并对超参数进行了优化。
🖼️ 关键图片

📊 实验亮点
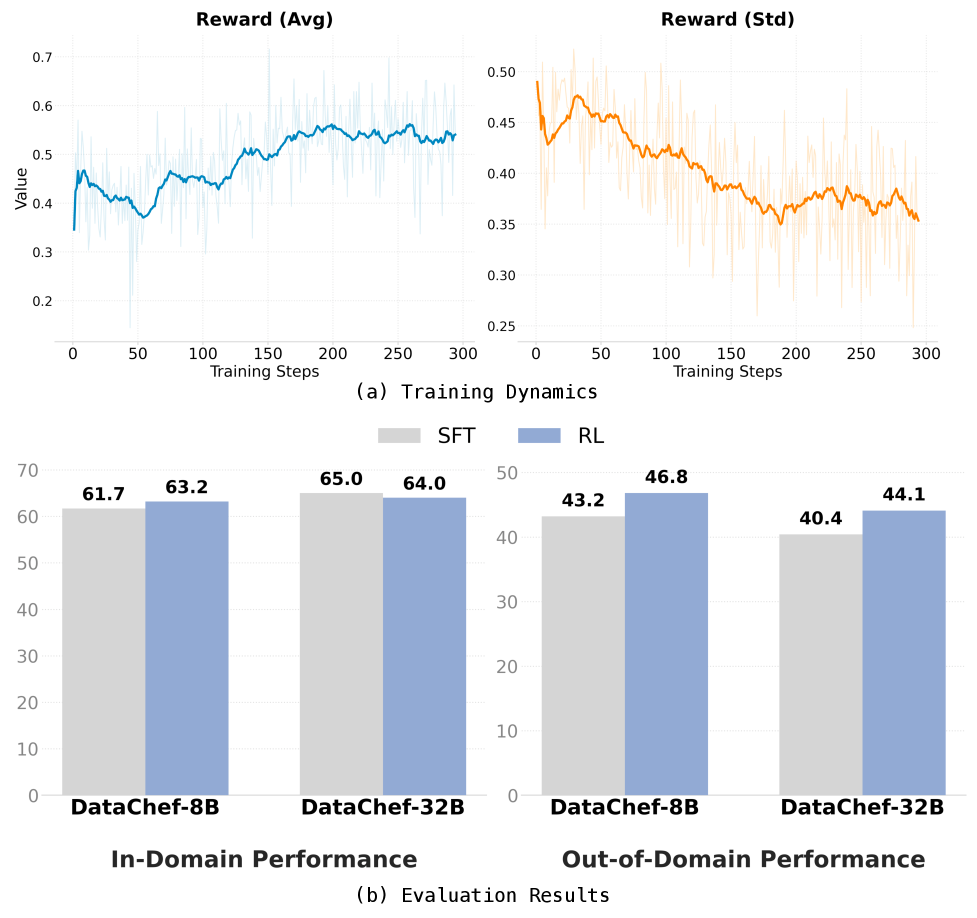
DataChef-32B在六个保留任务上生成了与人工专家相当的数据配方。在数学领域,DataChef-32B生成的配方使Qwen3-1.7B-Base在AIME'25上达到了66.7,超过了Qwen3-1.7B。这些结果表明,DataChef能够有效地自动化数据配方生成过程,并提升LLM的性能。
🎯 应用场景
DataChef可应用于各种LLM的微调场景,尤其是在数据资源丰富但缺乏人工经验的情况下。它可以帮助用户快速生成高质量的训练数据,提升LLM在特定领域的性能。该技术有望加速LLM的定制化和应用,降低LLM的使用门槛,并促进AI的自我进化。
📄 摘要(原文)
In the current landscape of Large Language Models (LLMs), the curation of large-scale, high-quality training data is a primary driver of model performance. A key lever is the \emph{data recipe}, which comprises a data processing pipeline to transform raw sources into training corpora. Despite the growing use of LLMs to automate individual data processing steps, such as data synthesis and filtering, the overall design of data recipes remains largely manual and labor-intensive, requiring substantial human expertise and iteration. To bridge this gap, we formulate \emph{end-to-end data recipe generation} for LLM adaptation. Given a target benchmark and a pool of available data sources, a model is required to output a complete data recipe that adapts a base LLM to the target task. We present DataChef-32B, which performs online reinforcement learning using a proxy reward that predicts downstream performance for candidate recipes. Across six held-out tasks, DataChef-32B produces practical recipes that reach comparable downstream performance to those curated by human experts. Notably, the recipe from DataChef-32B adapts Qwen3-1.7B-Base to the math domain, achieving 66.7 on AIME'25 and surpassing Qwen3-1.7B. This work sheds new light on automating LLM training and developing self-evolving AI systems.