C-MOP: Integrating Momentum and Boundary-Aware Clustering for Enhanced Prompt Evolution
作者: Binwei Yan, Yifei Fu, Mingjian Zhu, Hanting Chen, Mingxuan Yuan, Yunhe Wang, Hailin Hu
分类: cs.CL
发布日期: 2026-02-11
备注: The code is available at https://github.com/huawei-noah/noah-research/tree/master/C-MOP
🔗 代码/项目: GITHUB
💡 一句话要点
C-MOP:融合动量与边界感知聚类,提升Prompt进化效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt优化 大型语言模型 对比学习 动量学习 语义聚类
📋 核心要点
- 现有prompt优化方法易受噪声和冲突更新信号干扰,导致优化不稳定。
- C-MOP框架通过边界感知对比采样和动量引导语义聚类稳定优化过程。
- 实验表明,C-MOP显著优于现有基线,并能使小模型超越大模型。
📝 摘要(中文)
本文提出了一种名为C-MOP(Cluster-based Momentum Optimized Prompting)的框架,旨在稳定大型语言模型(LLMs)的自动prompt优化过程,解决现有方法中存在的噪声和冲突更新信号问题。C-MOP通过边界感知对比采样(BACS)和动量引导语义聚类(MGSC)实现优化稳定。BACS利用批次级别信息挖掘三元特征——难负样本、锚点和边界对,精确表征正负prompt样本的典型表示和决策边界。MGSC引入了具有时间衰减的文本动量机制,从迭代过程中波动的梯度中提取持久共识,解决语义冲突。大量实验表明,C-MOP始终优于PromptWizard和ProTeGi等SOTA基线,平均增益分别为1.58%和3.35%。值得注意的是,C-MOP使具有3B激活参数的通用LLM超越了70B的领域特定密集LLM,突显了其在驱动精确prompt进化方面的有效性。
🔬 方法详解
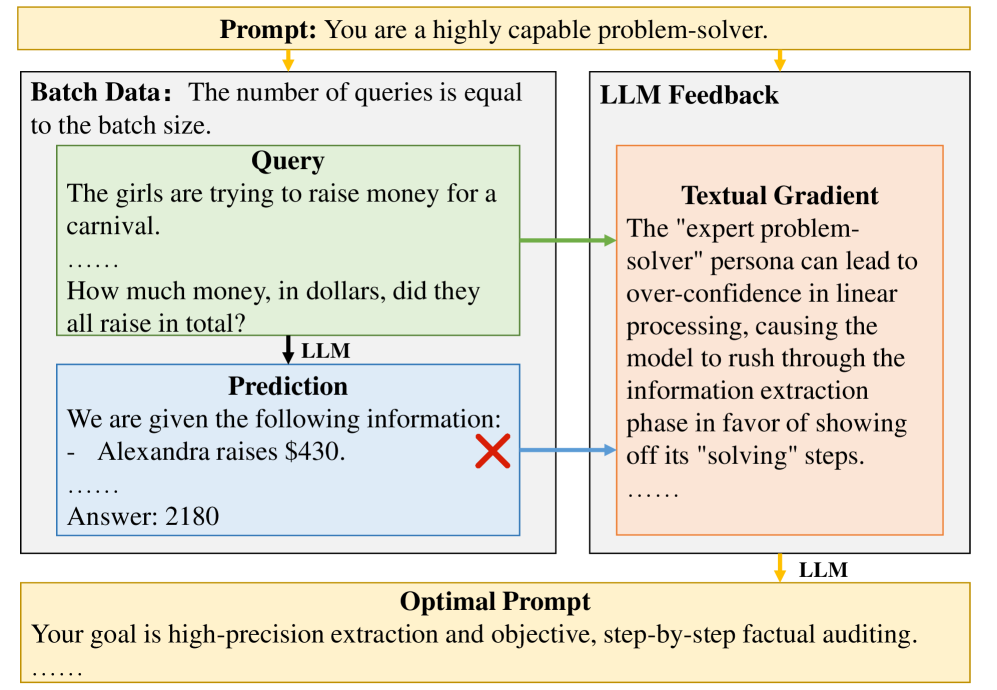
问题定义:现有自动prompt优化方法在大型语言模型中面临噪声和冲突的更新信号问题,这导致优化过程不稳定,难以获得高质量的prompt。这些方法通常无法有效区分正负prompt样本,也难以在迭代过程中保持语义一致性。
核心思路:C-MOP的核心思路是通过边界感知对比采样(BACS)精确区分正负prompt样本,并通过动量引导语义聚类(MGSC)在迭代过程中保持prompt的语义一致性。BACS旨在学习更具区分性的prompt表示,而MGSC则通过引入动量机制来平滑梯度,减少语义冲突。
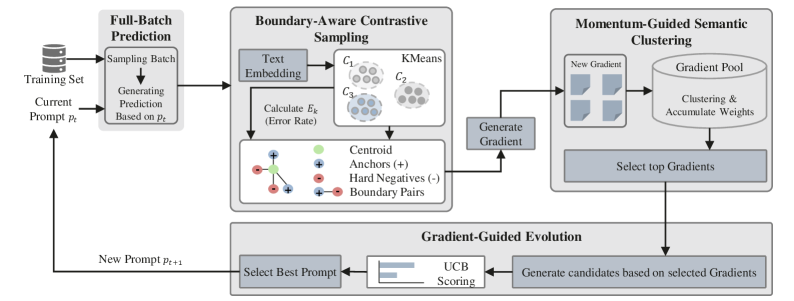
技术框架:C-MOP框架主要包含两个模块:BACS和MGSC。BACS模块首先从批次数据中挖掘难负样本、锚点和边界对,然后利用这些信息进行对比学习,从而学习到更具区分性的prompt表示。MGSC模块则在BACS的基础上,引入文本动量机制,通过时间衰减来平滑梯度,从而在迭代过程中保持prompt的语义一致性。整体流程是先通过BACS进行对比学习,然后利用MGSC进行动量更新。
关键创新:C-MOP的关键创新在于将边界感知对比学习和动量引导语义聚类相结合,从而有效地解决了prompt优化中的噪声和冲突更新信号问题。BACS通过挖掘三元特征,更精确地表征正负prompt样本的典型表示和决策边界,而MGSC则通过引入文本动量机制,从迭代过程中波动的梯度中提取持久共识。
关键设计:BACS的关键设计在于如何有效地挖掘难负样本、锚点和边界对。MGSC的关键设计在于动量系数的选择和时间衰减策略。损失函数方面,采用了对比损失函数,旨在拉近正样本对的距离,推远负样本对的距离。具体参数设置在论文中有详细描述,例如动量系数的取值范围和时间衰减的速率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,C-MOP在多个benchmark上均优于SOTA基线方法,例如PromptWizard和ProTeGi,平均增益分别为1.58%和3.35%。更重要的是,C-MOP能够使具有3B激活参数的通用LLM超越70B的领域特定密集LLM,这充分证明了C-MOP在驱动精确prompt进化方面的有效性。
🎯 应用场景
C-MOP可广泛应用于各种需要自动prompt优化的场景,例如文本生成、问答系统、对话系统等。该研究的实际价值在于能够提升大型语言模型的性能,降低人工prompt设计的成本。未来,C-MOP可以进一步扩展到多模态prompt优化,并应用于更复杂的任务中。
📄 摘要(原文)
Automatic prompt optimization is a promising direction to boost the performance of Large Language Models (LLMs). However, existing methods often suffer from noisy and conflicting update signals. In this research, we propose C-MOP (Cluster-based Momentum Optimized Prompting), a framework that stabilizes optimization via Boundary-Aware Contrastive Sampling (BACS) and Momentum-Guided Semantic Clustering (MGSC). Specifically, BACS utilizes batch-level information to mine tripartite features--Hard Negatives, Anchors, and Boundary Pairs--to precisely characterize the typical representation and decision boundaries of positive and negative prompt samples. To resolve semantic conflicts, MGSC introduces a textual momentum mechanism with temporal decay that distills persistent consensus from fluctuating gradients across iterations. Extensive experiments demonstrate that C-MOP consistently outperforms SOTA baselines like PromptWizard and ProTeGi, yielding average gains of 1.58% and 3.35%. Notably, C-MOP enables a general LLM with 3B activated parameters to surpass a 70B domain-specific dense LLM, highlighting its effectiveness in driving precise prompt evolution. The code is available at https://github.com/huawei-noah/noah-research/tree/master/C-MOP.