Training-Induced Bias Toward LLM-Generated Content in Dense Retrieval
作者: William Xion, Wolfgang Nejdl
分类: cs.IR, cs.CL
发布日期: 2026-02-11
备注: Accepted at ECIR 2026
💡 一句话要点
揭示稠密检索中训练诱导的LLM生成内容偏见,并驳斥了困惑度的解释力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稠密检索 来源偏见 大型语言模型 训练诱导 困惑度 信息检索 自然语言处理
📋 核心要点
- 现有研究表明,稠密检索模型倾向于偏好LLM生成的文本,但其根本原因尚不明确,特别是困惑度是否是主要因素。
- 该研究通过控制训练数据来源和阶段,系统地评估了稠密检索模型对人工生成和LLM生成文本的偏好变化。
- 实验结果表明,来源偏见是训练诱导的,MS MARCO上的微调会增强LLM偏好,而困惑度与相关性的关联性较弱。
📝 摘要(中文)
稠密检索是开放域自然语言处理任务中获取相关上下文或世界知识的一种有前景的方法,目前已广泛应用于信息检索应用中。然而,最近的报告声称,人们普遍偏爱大型语言模型(LLM)生成的文本。这种偏见被称为“来源偏见”,并且假设较低的困惑度促成了这种效应。在本研究中,我们通过进行受控评估来重新审视这一说法,以追踪这种偏好在训练阶段和数据源中的出现。使用SciFact和Natural Questions (NQ320K)数据集的并行人工生成和LLM生成版本,我们将无监督检查点与使用领域内人工文本、领域内LLM生成文本和MS MARCO微调的模型进行比较。我们的研究表明,来源偏见是一种训练诱导的现象,而不是稠密检索的固有属性。
🔬 方法详解
问题定义:论文旨在解决稠密检索模型中存在的“来源偏见”问题,即模型更倾向于选择由大型语言模型(LLM)生成的文本,即使这些文本在质量上并不优于人工生成的文本。现有研究认为这种偏见可能与LLM生成文本的低困惑度有关,但缺乏充分的实验验证。
核心思路:论文的核心思路是通过控制训练数据来源和训练阶段,观察稠密检索模型对人工生成文本和LLM生成文本的偏好变化。通过对比不同训练策略(无监督、领域内人工文本微调、领域内LLM文本微调、MS MARCO微调)下模型的表现,分析来源偏见的产生机制。
技术框架:该研究采用标准的稠密检索框架,主要包括一个查询编码器和一个文档编码器。研究使用了预训练的语言模型作为编码器的初始化,并通过不同的训练数据进行微调。为了评估模型对LLM生成文本的偏好,研究构建了包含人工生成文本和LLM生成文本的平行数据集。此外,研究还通过将语言模型头重新连接到微调后的稠密检索编码器,来评估困惑度与相关性的关系。
关键创新:该研究的关键创新在于其系统性的实验设计,通过控制训练数据来源和训练阶段,揭示了来源偏见是训练诱导的现象,而非稠密检索模型固有的属性。此外,该研究还通过实验驳斥了困惑度是来源偏见主要原因的观点。
关键设计:研究使用了SciFact和Natural Questions (NQ320K)数据集的平行人工生成和LLM生成版本。使用了不同的训练策略,包括无监督训练、领域内人工文本微调、领域内LLM生成文本微调和MS MARCO微调。为了评估困惑度,研究将语言模型头重新连接到微调后的稠密检索编码器,并计算了模型对相关文档和不相关文档的困惑度。
🖼️ 关键图片
📊 实验亮点
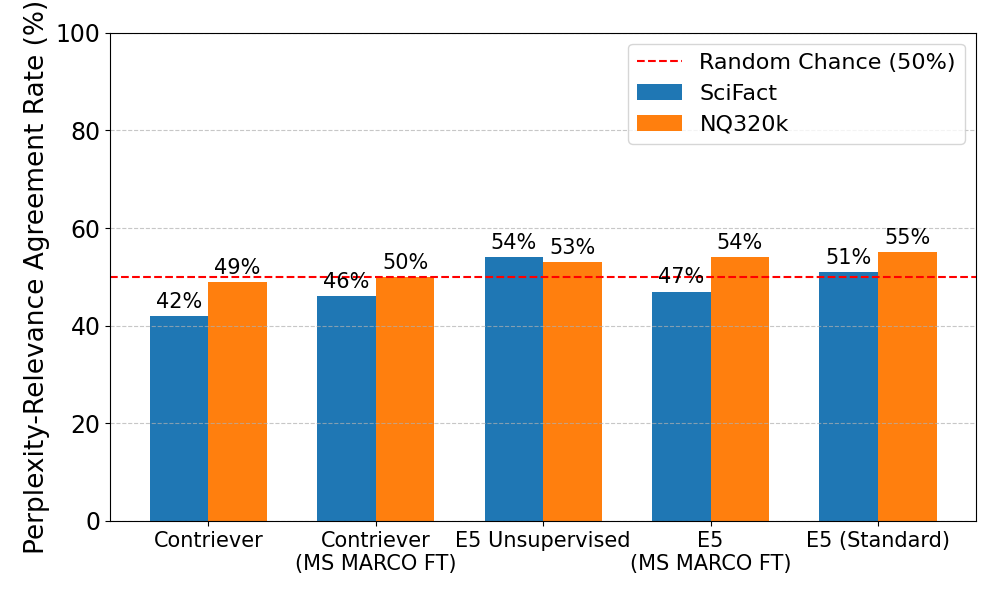
实验结果表明,无监督检索器并不表现出一致的亲LLM偏好,其方向和幅度取决于数据集。在所有测试设置中,在MS MARCO上进行监督微调始终将排名转移到LLM生成的文本。在领域内进行微调会在偏好方面产生数据集特定的和不一致的转变。在LLM生成的语料库上进行微调会产生明显的亲LLM偏见。困惑度与相关性接近随机水平,削弱了困惑度的解释力。
🎯 应用场景
该研究成果有助于改进稠密检索模型的训练策略,减少对LLM生成内容的偏见,提高检索结果的公平性和可靠性。这对于构建更值得信赖的问答系统、信息检索系统和知识图谱等应用至关重要。未来的研究可以探索更有效的去偏见方法,例如对抗训练或数据增强。
📄 摘要(原文)
Dense retrieval is a promising approach for acquiring relevant context or world knowledge in open-domain natural language processing tasks and is now widely used in information retrieval applications. However, recent reports claim a broad preference for text generated by large language models (LLMs). This bias is called "source bias", and it has been hypothesized that lower perplexity contributes to this effect. In this study, we revisit this claim by conducting a controlled evaluation to trace the emergence of such preferences across training stages and data sources. Using parallel human- and LLM-generated counterparts of the SciFact and Natural Questions (NQ320K) datasets, we compare unsupervised checkpoints with models fine-tuned using in-domain human text, in-domain LLM-generated text, and MS MARCO. Our results show the following: 1) Unsupervised retrievers do not exhibit a uniform pro-LLM preference. The direction and magnitude depend on the dataset. 2) Across the settings tested, supervised fine-tuning on MS MARCO consistently shifts the rankings toward LLM-generated text. 3) In-domain fine-tuning produces dataset-specific and inconsistent shifts in preference. 4) Fine-tuning on LLM-generated corpora induces a pronounced pro-LLM bias. Finally, a retriever-centric perplexity probe involving the reattachment of a language modeling head to the fine-tuned dense retriever encoder indicates agreement with relevance near chance, thereby weakening the explanatory power of perplexity. Our study demonstrates that source bias is a training-induced phenomenon rather than an inherent property of dense retrievers.