Reinforced Curriculum Pre-Alignment for Domain-Adaptive VLMs
作者: Yuming Yan, Shuo Yang, Kai Tang, Sihong Chen, Yang Zhang, Ke Xu, Dan Hu, Qun Yu, Pengfei Hu, Edith C. H. Ngai
分类: cs.CL
发布日期: 2026-02-11
💡 一句话要点
提出RCPA:强化课程预对齐方法,提升领域自适应视觉-语言模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 领域自适应 强化学习 课程学习 预训练 多模态学习 灾难性遗忘
📋 核心要点
- 现有VLM在特定领域表现不足,监督微调易导致灾难性遗忘,难以兼顾领域适应性和通用能力。
- RCPA通过课程感知的渐进调制机制,在训练初期施加部分输出约束,逐步引导模型学习新领域知识。
- 实验表明,RCPA在专业领域和通用基准上均表现出色,有效提升了VLM的领域适应性和通用性。
📝 摘要(中文)
视觉-语言模型(VLM)在通用任务上表现出色,但在医学影像或几何问题求解等专业领域表现欠佳。监督微调(SFT)可以提升特定领域性能,但常导致灾难性遗忘,限制泛化能力。核心挑战在于使VLM适应新领域,同时保留通用能力。持续预训练对扩展大型语言模型(LLM)知识有效,但对VLM而言,计算成本高昂且多数开源模型缺乏预训练数据,因此不适用。强化学习(RL)方法如GRPO在保留通用能力方面有潜力,但在模型初始缺乏领域知识的领域自适应场景中常失效,导致优化崩溃。为解决此问题,我们提出强化课程预对齐(RCPA),一种新型后训练范式,引入课程感知的渐进调制机制。早期阶段,RCPA应用部分输出约束,安全地使模型接触新领域概念。随着模型领域熟悉度增加,训练逐渐过渡到完全生成优化,细化响应并使其与领域特定偏好对齐。这种分阶段适应平衡了领域知识获取与通用多模态能力保留。在专业领域和通用基准上的大量实验验证了RCPA的有效性,为构建高性能和领域自适应VLM建立了实用途径。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLM)在特定领域自适应的问题。现有方法,如监督微调(SFT),虽然可以提升在目标领域的性能,但会导致灾难性遗忘,损害模型原有的通用能力。而直接应用强化学习(RL)进行领域自适应,在模型缺乏足够领域知识的情况下,容易出现优化崩溃的问题。
核心思路:论文的核心思路是采用一种课程学习(Curriculum Learning)的方式,逐步引导VLM学习新的领域知识。具体来说,通过强化学习(RL)框架,设计一个课程,让模型先学习简单的、容易掌握的领域概念,然后再逐步过渡到更复杂的概念。这种渐进式的学习方式可以避免模型在初期就面临过大的挑战,从而降低优化崩溃的风险。
技术框架:RCPA (Reinforced Curriculum Pre-Alignment) 的整体框架包含以下几个主要阶段:1) 预对齐阶段:利用部分输出约束,使模型初步接触新领域概念。2) 课程学习阶段:根据模型对领域知识的掌握程度,逐步调整训练难度,从简单到复杂。3) 强化学习优化阶段:利用强化学习算法,优化模型的生成能力,使其能够生成符合领域特定偏好的响应。
关键创新:RCPA的关键创新在于引入了课程学习的思想,并将其与强化学习相结合,用于VLM的领域自适应。与传统的直接进行强化学习的方法相比,RCPA能够更有效地引导模型学习新领域知识,避免优化崩溃。此外,RCPA还设计了一种渐进式的调制机制,可以根据模型对领域知识的掌握程度,动态调整训练难度。
关键设计:RCPA的关键设计包括:1) 课程设计:如何设计合适的课程,使得模型能够逐步掌握领域知识。2) 奖励函数设计:如何设计奖励函数,引导模型生成符合领域特定偏好的响应。3) 部分输出约束:如何选择合适的部分输出约束,既能引导模型学习新知识,又能避免过度约束,影响模型的通用能力。具体的参数设置和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片


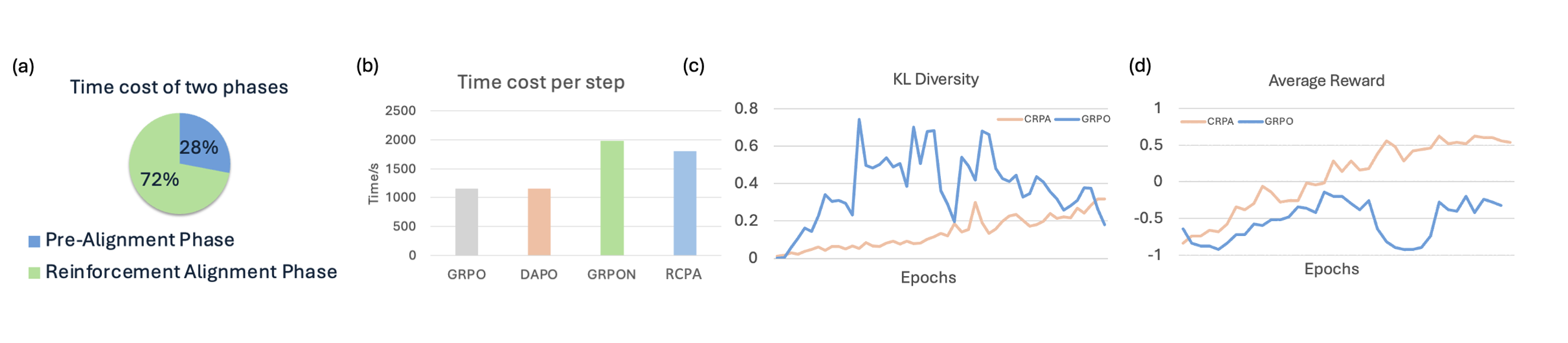
📊 实验亮点
论文通过在多个专业领域和通用基准上的实验,验证了RCPA的有效性。具体性能数据和提升幅度在摘要中未提及,需要查阅论文全文。但总体而言,实验结果表明,RCPA能够有效提升VLM的领域适应性和通用性,优于现有方法。
🎯 应用场景
RCPA方法可应用于各种需要领域自适应的视觉-语言模型,例如医学影像诊断、地理信息分析、工业质检等。通过该方法,可以构建在特定领域表现出色,同时保持通用能力的VLM,具有重要的实际应用价值。未来,该方法有望进一步扩展到其他多模态模型和领域,推动人工智能技术的发展。
📄 摘要(原文)
Vision-Language Models (VLMs) demonstrate remarkable general-purpose capabilities but often fall short in specialized domains such as medical imaging or geometric problem-solving. Supervised Fine-Tuning (SFT) can enhance performance within a target domain, but it typically causes catastrophic forgetting, limiting its generalization. The central challenge, therefore, is to adapt VLMs to new domains while preserving their general-purpose capabilities. Continual pretraining is effective for expanding knowledge in Large Language Models (LLMs), but it is less feasible for VLMs due to prohibitive computational costs and the unavailability of pretraining data for most open-source models. This necessitates efficient post-training adaptation methods. Reinforcement learning (RL)-based approaches such as Group Relative Policy Optimization (GRPO) have shown promise in preserving general abilities, yet they often fail in domain adaptation scenarios where the model initially lacks sufficient domain knowledge, leading to optimization collapse. To bridge this gap, we propose Reinforced Curriculum Pre-Alignment (RCPA), a novel post-training paradigm that introduces a curriculum-aware progressive modulation mechanism. In the early phase, RCPA applies partial output constraints to safely expose the model to new domain concepts. As the model's domain familiarity increases, training gradually transitions to full generation optimization, refining responses and aligning them with domain-specific preferences. This staged adaptation balances domain knowledge acquisition with the preservation of general multimodal capabilities. Extensive experiments across specialized domains and general benchmarks validate the effectiveness of RCPA, establishing a practical pathway toward building high-performing and domain-adaptive VLMs.