UMEM: Unified Memory Extraction and Management Framework for Generalizable Memory
作者: Yongshi Ye, Hui Jiang, Feihu Jiang, Tian Lan, Yichao Du, Biao Fu, Xiaodong Shi, Qianghuai Jia, Longyue Wang, Weihua Luo
分类: cs.CL
发布日期: 2026-02-11
💡 一句话要点
UMEM:统一记忆提取与管理框架,提升LLM Agent记忆泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 记忆提取 记忆管理 大型语言模型 Agent 泛化能力 语义邻域建模 GRPO 持续学习
📋 核心要点
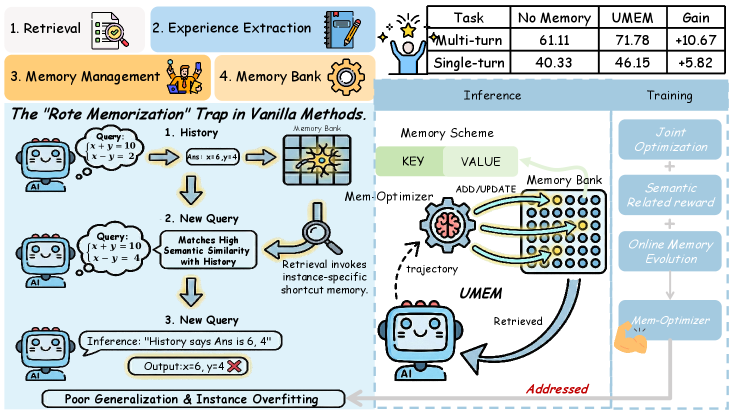
- 现有LLM Agent记忆方法侧重管理,忽略提取过程优化,导致Agent易积累特定实例噪声,泛化性差。
- UMEM框架联合优化LLM的记忆提取与管理,提升记忆的鲁棒性和泛化能力,避免过拟合。
- 实验表明,UMEM在多轮交互任务中性能显著提升,最高达10.67%,并在持续进化中保持稳定增长。
📝 摘要(中文)
本文提出了一种统一记忆提取与管理(UMEM)的自进化Agent框架,用于解决基于大型语言模型(LLM)的Agent中记忆泛化能力差的问题。现有方法主要优化记忆管理,而将记忆提取视为静态过程,导致Agent积累特定实例的噪声而非鲁棒记忆。UMEM联合优化LLM,使其能够同时提取和管理记忆。为了减轻对特定实例的过拟合,引入了语义邻域建模,并通过GRPO优化模型,利用邻域级别的边际效用奖励。这种方法通过评估语义相关查询集群中的记忆效用,确保记忆的泛化性。在五个基准测试上的大量实验表明,UMEM显著优于极具竞争力的基线,在多轮交互任务中实现了高达10.67%的改进。此外,UMEM在持续进化过程中保持单调增长曲线。代码和模型将公开发布。
🔬 方法详解
问题定义:现有基于LLM的Agent依赖于自进化记忆作为可训练参数。然而,现有方法主要关注记忆管理,将记忆提取视为静态过程,导致Agent容易过拟合特定实例,积累噪声,从而降低了记忆的泛化能力。因此,如何提升LLM Agent记忆的泛化能力,使其能够提取鲁棒的记忆,是本文要解决的核心问题。
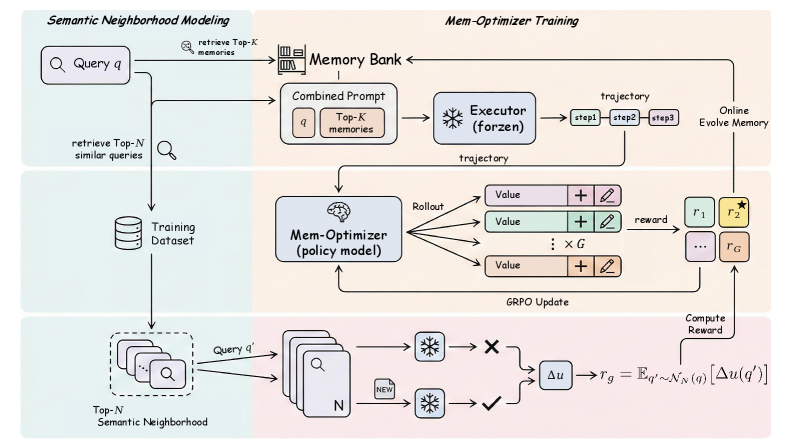
核心思路:UMEM的核心思路是联合优化记忆提取和记忆管理过程。通过同时训练LLM来提取和管理记忆,避免了将记忆提取视为静态过程的局限性。此外,引入语义邻域建模,通过评估语义相关查询集群中的记忆效用,鼓励模型学习更具泛化性的记忆表示。
技术框架:UMEM框架包含两个主要组成部分:记忆提取模块和记忆管理模块。记忆提取模块负责从经验中提取有用的信息,并将其存储到记忆库中。记忆管理模块负责更新和维护记忆库,例如添加新记忆、删除冗余记忆或更新现有记忆。这两个模块通过一个共享的LLM进行联合优化。框架使用GRPO算法,通过邻域级别的边际效用奖励来优化模型。
关键创新:UMEM的关键创新在于联合优化记忆提取和记忆管理,以及引入语义邻域建模来提升记忆的泛化能力。与现有方法相比,UMEM不再将记忆提取视为静态过程,而是通过训练LLM来动态地提取和管理记忆。语义邻域建模则通过评估语义相关查询集群中的记忆效用,鼓励模型学习更具泛化性的记忆表示,从而避免过拟合特定实例。
关键设计:UMEM使用GRPO(Generalized Policy Optimization)算法来优化模型。GRPO通过最大化邻域级别的边际效用奖励来鼓励模型学习更具泛化性的记忆表示。具体来说,对于每个查询,UMEM首先找到其语义邻域,然后计算该邻域内所有查询的平均奖励。模型的目标是最大化这个平均奖励,从而鼓励模型学习能够泛化到整个语义邻域的记忆表示。损失函数的设计也考虑了记忆的质量和多样性,以确保记忆库中包含有用的信息,并且这些信息具有一定的多样性。
🖼️ 关键图片
📊 实验亮点
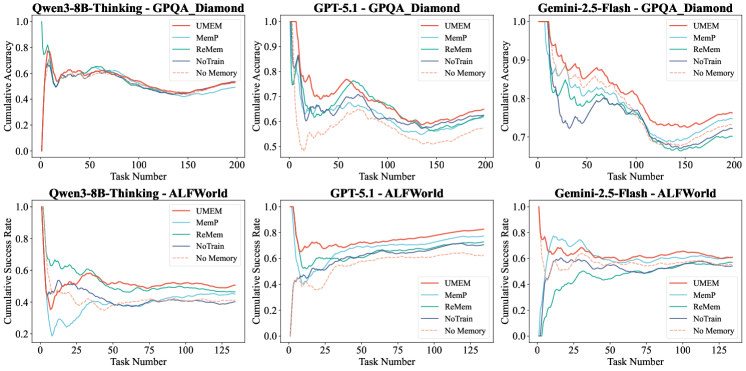
UMEM在五个基准测试上取得了显著的性能提升,尤其是在多轮交互任务中,相比于极具竞争力的基线方法,UMEM实现了高达10.67%的改进。此外,实验结果还表明,UMEM在持续进化过程中能够保持单调增长曲线,这意味着UMEM能够不断学习新的知识和技能,并不断提升自身的性能。这些实验结果充分证明了UMEM的有效性和优越性。
🎯 应用场景
UMEM框架具有广泛的应用前景,例如智能对话系统、机器人导航、游戏AI等。在智能对话系统中,UMEM可以帮助Agent更好地理解用户的意图,并生成更自然、更流畅的回复。在机器人导航中,UMEM可以帮助机器人更好地理解环境,并规划出更安全、更有效的路径。在游戏AI中,UMEM可以帮助Agent更好地理解游戏规则,并制定出更智能、更具挑战性的策略。UMEM的持续进化能力使其能够适应不断变化的环境和任务,具有重要的实际价值和未来影响。
📄 摘要(原文)
Self-evolving memory serves as the trainable parameters for Large Language Models (LLMs)-based agents, where extraction (distilling insights from experience) and management (updating the memory bank) must be tightly coordinated. Existing methods predominately optimize memory management while treating memory extraction as a static process, resulting in poor generalization, where agents accumulate instance-specific noise rather than robust memories. To address this, we propose Unified Memory Extraction and Management (UMEM), a self-evolving agent framework that jointly optimizes a Large Language Model to simultaneous extract and manage memories. To mitigate overfitting to specific instances, we introduce Semantic Neighborhood Modeling and optimize the model with a neighborhood-level marginal utility reward via GRPO. This approach ensures memory generalizability by evaluating memory utility across clusters of semantically related queries. Extensive experiments across five benchmarks demonstrate that UMEM significantly outperforms highly competitive baselines, achieving up to a 10.67% improvement in multi-turn interactive tasks. Futhermore, UMEM maintains a monotonic growth curve during continuous evolution. Codes and models will be publicly released.