ISD-Agent-Bench: A Comprehensive Benchmark for Evaluating LLM-based Instructional Design Agents
作者: YoungHoon Jeon, Suwan Kim, Haein Son, Sookbun Lee, Yeil Jeong, Unggi Lee
分类: cs.SE, cs.CL
发布日期: 2026-02-11
💡 一句话要点
提出ISD-Agent-Bench以解决LLM代理评估标准化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 教学系统设计 大型语言模型 评估基准 上下文矩阵 多评审协议 理论与实践结合 教育技术
📋 核心要点
- 现有的LLM代理在教学系统设计的评估中缺乏标准化基准,导致评估结果的可靠性不足。
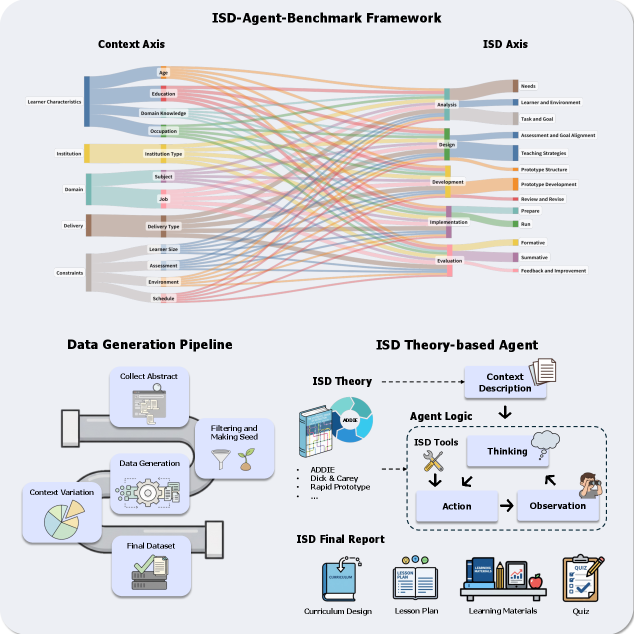
- 论文提出ISD-Agent-Bench基准,通过上下文矩阵框架生成多样化场景,以实现对LLM代理的系统评估。
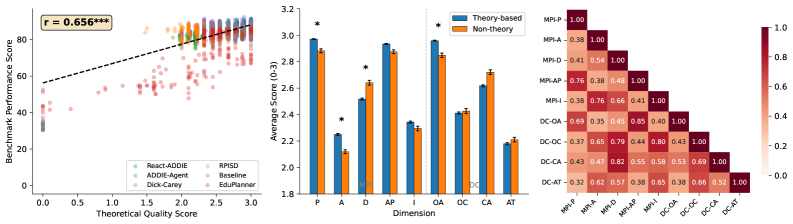
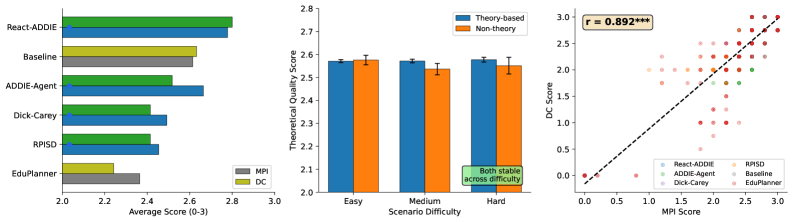
- 实验结果显示,结合经典ISD理论与现代推理方法的代理在性能上显著优于传统方法,验证了理论质量与基准表现的强相关性。
📝 摘要(中文)
大型语言模型(LLM)代理在自动化教学系统设计(ISD)方面展现出良好的潜力。然而,由于缺乏标准化基准和LLM作为评判者的偏见风险,评估这些代理仍然具有挑战性。我们提出了ISD-Agent-Bench,这是一个综合基准,包含25,795个场景,通过上下文矩阵框架生成,结合了51个上下文变量和基于ADDIE模型的33个ISD子步骤。为了确保评估的可靠性,我们采用了多评审协议,使用来自不同提供商的多种LLM,达到了高的评审一致性。实验结果表明,结合经典ISD框架与现代ReAct风格推理的代理表现最佳,超越了纯理论代理和仅技术方法的代理。
🔬 方法详解
问题定义:论文要解决的问题是如何有效评估基于大型语言模型的教学系统设计代理,现有方法面临缺乏标准化基准和评估偏见的挑战。
核心思路:论文的核心思路是构建ISD-Agent-Bench基准,通过上下文矩阵框架生成多样化的评估场景,以提高评估的可靠性和有效性。
技术框架:整体架构包括生成25,795个场景的上下文矩阵,结合51个上下文变量和33个ISD子步骤,采用多评审协议以确保评估一致性。
关键创新:最重要的技术创新点在于结合经典ISD理论与现代推理方法,形成了一种新的评估框架,显著提升了代理的性能。
关键设计:在设计中,采用了多种LLM进行评审,确保了评估的多样性和可靠性,同时关注理论质量与实际表现之间的关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,结合经典ISD框架与现代推理方法的代理在1,017个测试场景中表现最佳,超越了传统的理论基础代理和仅技术方法的代理,验证了理论质量与基准表现之间的强相关性。
🎯 应用场景
该研究的潜在应用领域包括教育技术、在线学习平台和教学设计工具。通过提供一个标准化的评估基准,ISD-Agent-Bench能够帮助教育工作者和研究人员更好地理解和优化LLM在教学系统设计中的应用,推动教育领域的创新与发展。
📄 摘要(原文)
Large Language Model (LLM) agents have shown promising potential in automating Instructional Systems Design (ISD), a systematic approach to developing educational programs. However, evaluating these agents remains challenging due to the lack of standardized benchmarks and the risk of LLM-as-judge bias. We present ISD-Agent-Bench, a comprehensive benchmark comprising 25,795 scenarios generated via a Context Matrix framework that combines 51 contextual variables across 5 categories with 33 ISD sub-steps derived from the ADDIE model. To ensure evaluation reliability, we employ a multi-judge protocol using diverse LLMs from different providers, achieving high inter-judge reliability. We compare existing ISD agents with novel agents grounded in classical ISD theories such as ADDIE, Dick \& Carey, and Rapid Prototyping ISD. Experiments on 1,017 test scenarios demonstrate that integrating classical ISD frameworks with modern ReAct-style reasoning achieves the highest performance, outperforming both pure theory-based agents and technique-only approaches. Further analysis reveals that theoretical quality strongly correlates with benchmark performance, with theory-based agents showing significant advantages in problem-centered design and objective-assessment alignment. Our work provides a foundation for systematic LLM-based ISD research.