Online Causal Kalman Filtering for Stable and Effective Policy Optimization
作者: Shuo He, Lang Feng, Xin Cheng, Lei Feng, Bo An
分类: cs.CL, cs.AI
发布日期: 2026-02-11
备注: Preprint
💡 一句话要点
提出在线因果卡尔曼滤波策略优化算法,解决LLM强化学习中不稳定的重要性采样问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 重要性采样 卡尔曼滤波 策略优化 在线学习 因果推断
📋 核心要点
- 大型语言模型强化学习面临token级别重要性采样比率方差过高的问题,导致策略优化不稳定。
- 提出在线因果卡尔曼滤波(KPO)方法,将重要性采样比率建模为潜在状态,用卡尔曼滤波在线更新,平滑噪声。
- 实验表明,KPO在数学推理数据集上优于现有方法,实现了更稳定和有效的策略更新。
📝 摘要(中文)
针对大型语言模型强化学习中高方差的token级别重要性采样(IS)比率问题,该问题会破坏大规模策略优化的稳定性。现有方法通常使用固定的序列级别IS比率或单独调整每个token的IS比率,忽略了序列中token之间的时间性off-policy偏差。本文首先通过实验发现,token级别的局部off-policy偏差在结构上是不一致的,这可能会扭曲相邻token之间的策略梯度更新,导致训练崩溃。为了解决这个问题,我们提出了一种用于稳定和有效策略优化的在线因果卡尔曼滤波(KPO)方法。具体来说,我们将期望的IS比率建模为一个在token之间演变的潜在状态,并应用卡尔曼滤波器,基于过去token的状态在线和自回归地更新该状态,而无需考虑未来的token。由此产生的滤波后的IS比率保留了token级别的局部结构感知变化,同时强烈平滑了噪声峰值,从而产生更稳定和有效的策略更新。实验表明,与最先进的方法相比,KPO在具有挑战性的数学推理数据集上取得了优异的结果。
🔬 方法详解
问题定义:论文旨在解决大型语言模型强化学习中,由于token级别重要性采样(IS)比率的高方差而导致的策略优化不稳定问题。现有方法要么使用固定的序列级别IS比率,忽略了token之间的时间依赖性,要么独立调整每个token的IS比率,忽略了局部结构信息。这两种方法都无法有效处理token级别的off-policy偏差,导致训练过程中的梯度更新不稳定,甚至崩溃。
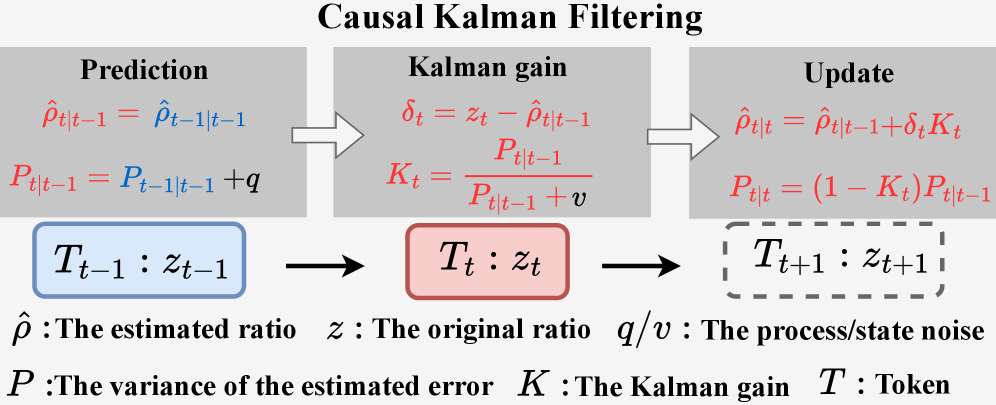
核心思路:论文的核心思路是将期望的IS比率建模为一个随token演变的潜在状态,并利用卡尔曼滤波来估计和更新这个状态。卡尔曼滤波能够融合来自过去token的信息,平滑噪声,同时保留token级别的局部结构感知变化。通过这种方式,可以获得更稳定和准确的IS比率,从而改善策略优化的稳定性。
技术框架:KPO方法的核心是一个在线卡尔曼滤波过程。对于每个token,首先基于过去token的状态预测当前的IS比率状态。然后,根据当前token的观测值(例如,实际的IS比率),使用卡尔曼滤波更新状态估计。更新后的状态估计作为下一个token的先验状态,形成一个自回归的更新过程。整个过程无需访问未来的token信息,保证了因果性。
关键创新:KPO的关键创新在于将卡尔曼滤波应用于token级别的重要性采样比率估计,并将其与策略优化过程相结合。与现有方法相比,KPO能够更好地利用token之间的时间依赖性,同时平滑噪声,从而获得更稳定和有效的策略梯度估计。此外,KPO的在线更新方式使其能够适应动态变化的环境。
关键设计:KPO的关键设计包括:(1) 状态转移模型:描述IS比率状态如何在token之间演变。一个简单的选择是假设状态是平稳的,即状态转移矩阵为单位矩阵。(2) 观测模型:描述如何从token的观测值(例如,实际的IS比率)推断IS比率状态。观测模型通常包含一个噪声项,用于建模观测误差。(3) 卡尔曼滤波器的参数:包括状态转移噪声的方差和观测噪声的方差。这些参数需要根据具体问题进行调整,以平衡状态估计的平滑性和响应性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,KPO在具有挑战性的数学推理数据集上取得了显著的性能提升。与现有最先进的方法相比,KPO能够更稳定地训练模型,并获得更高的准确率。具体的数据提升幅度在论文中给出,证明了KPO的有效性。
🎯 应用场景
该研究成果可应用于各种大型语言模型的强化学习场景,尤其是在需要处理长序列和高方差重要性采样比率的情况下。例如,可以用于优化对话系统、文本生成模型和代码生成模型等。该方法能够提高训练的稳定性和效率,从而加速模型的开发和部署。
📄 摘要(原文)
Reinforcement learning for large language models suffers from high-variance token-level importance sampling (IS) ratios, which would destabilize policy optimization at scale. To improve stability, recent methods typically use a fixed sequence-level IS ratio for all tokens in a sequence or adjust each token's IS ratio separately, thereby neglecting temporal off-policy derivation across tokens in a sequence. In this paper, we first empirically identify that local off-policy deviation is structurally inconsistent at the token level, which may distort policy-gradient updates across adjacent tokens and lead to training collapse. To address the issue, we propose Online Causal Kalman Filtering for stable and effective Policy Optimization (KPO). Concretely, we model the desired IS ratio as a latent state that evolves across tokens and apply a Kalman filter to update this state online and autoregressively based on the states of past tokens, regardless of future tokens. The resulting filtered IS ratios preserve token-wise local structure-aware variation while strongly smoothing noise spikes, yielding more stable and effective policy updates. Experimentally, KPO achieves superior results on challenging math reasoning datasets compared with state-of-the-art counterparts.