Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
作者: Ailin Huang, Ang Li, Aobo Kong, Bin Wang, Binxing Jiao, Bo Dong, Bojun Wang, Boyu Chen, Brian Li, Buyun Ma, Chang Su, Changxin Miao, Changyi Wan, Chao Lou, Chen Hu, Chen Xu, Chenfeng Yu, Chengting Feng, Chengyuan Yao, Chunrui Han, Dan Ma, Dapeng Shi, Daxin Jiang, Dehua Ma, Deshan Sun, Di Qi, Enle Liu, Fajie Zhang, Fanqi Wan, Guanzhe Huang, Gulin Yan, Guoliang Cao, Guopeng Li, Han Cheng, Hangyu Guo, Hanshan Zhang, Hao Nie, Haonan Jia, Haoran Lv, Hebin Zhou, Hekun Lv, Heng Wang, Heung-Yeung Shum, Hongbo Huang, Hongbo Peng, Hongyu Zhou, Hongyuan Wang, Houyong Chen, Huangxi Zhu, Huimin Wu, Huiyong Guo, Jia Wang, Jian Zhou, Jianjian Sun, Jiaoren Wu, Jiaran Zhang, Jiashu Lv, Jiashuo Liu, Jiayi Fu, Jiayu Liu, Jie Cheng, Jie Luo, Jie Yang, Jie Zhou, Jieyi Hou, Jing Bai, Jingcheng Hu, Jingjing Xie, Jingwei Wu, Jingyang Zhang, Jishi Zhou, Junfeng Liu, Junzhe Lin, Ka Man Lo, Kai Liang, Kaibo Liu, Kaijun Tan, Kaiwen Yan, Kaixiang Li, Kang An, Kangheng Lin, Lei Yang, Liang Lv, Liang Zhao, Liangyu Chen, Lieyu Shi, Liguo Tan, Lin Lin, Lina Chen, Luck Ma, Mengqiang Ren, Michael Li, Ming Li, Mingliang Li, Mingming Zhang, Mingrui Chen, Mitt Huang, Na Wang, Peng Liu, Qi Han, Qian Zhao, Qinglin He, Qinxin Du, Qiuping Wu, Quan Sun, Rongqiu Yang, Ruihang Miao, Ruixin Han, Ruosi Wan, Ruyan Guo, Shan Wang, Shaoliang Pang, Shaowen Yang, Shengjie Fan, Shijie Shang, Shiliang Yang, Shiwei Li, Shuangshuang Tian, Siqi Liu, Siye Wu, Siyu Chen, Song Yuan, Tiancheng Cao, Tianchi Yue, Tianhao Cheng, Tianning Li, Tingdan Luo, Wang You, Wei Ji, Wei Yuan, Wei Zhang, Weibo Wu, Weihao Xie, Wen Sun, Wenjin Deng, Wenzhen Zheng, Wuxun Xie, Xiangfeng Wang, Xiangwen Kong, Xiangyu Liu, Xiangyu Zhang, Xiaobo Yang, Xiaojia Liu, Xiaolan Yuan, Xiaoran Jiao, Xiaoxiao Ren, Xiaoyun Zhang, Xin Li, Xin Liu, Xin Wu, Xing Chen, Xingping Yang, Xinran Wang, Xu Zhao, Xuan He, Xuanti Feng, Xuedan Cai, Xuqiang Zhou, Yanbo Yu, Yang Li, Yang Xu, Yanlin Lai, Yanming Xu, Yaoyu Wang, Yeqing Shen, Yibo Zhu, Yichen Lv, Yicheng Cao, Yifeng Gong, Yijing Yang, Yikun Yang, Yin Zhao, Yingxiu Zhao, Yinmin Zhang, Yitong Zhang, Yixuan Zhang, Yiyang Chen, Yongchi Zhao, Yongshen Long, Yongyao Wang, Yousong Guan, Yu Zhou, Yuang Peng, Yuanhao Ding, Yuantao Fan, Yuanzhen Yang, Yuchu Luo, Yudi Zhao, Yue Peng, Yueqiang Lin, Yufan Lu, Yuling Zhao, Yunzhou Ju, Yurong Zhang, Yusheng Li, Yuxiang Yang, Yuyang Chen, Yuzhu Cai, Zejia Weng, Zetao Hong, Zexi Li, Zhe Xie, Zheng Ge, Zheng Gong, Zheng Zeng, Zhenyi Lu, Zhewei Huang, Zhichao Chang, Zhiguo Huang, Zhiheng Hu, Zidong Yang, Zili Wang, Ziqi Ren, Zixin Zhang, Zixuan Wang
分类: cs.CL, cs.AI
发布日期: 2026-02-11
备注: Technical report for Step 3.5 Flash
💡 一句话要点
Step 3.5 Flash:以11B活跃参数实现前沿水平的智能体能力,兼顾推理与效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 混合专家模型 稀疏激活 智能体 强化学习 多Token预测 滑动窗口注意力 前沿模型
📋 核心要点
- 现有智能体模型在推理能力和计算效率之间存在权衡,难以兼顾前沿智能和实际部署需求。
- Step 3.5 Flash采用稀疏MoE架构,结合滑动窗口注意力、全注意力及多Token预测,优化推理速度和成本。
- 实验表明,Step 3.5 Flash在智能体、代码和数学任务上达到前沿水平,性能与GPT-5.2 xHigh等模型相当。
📝 摘要(中文)
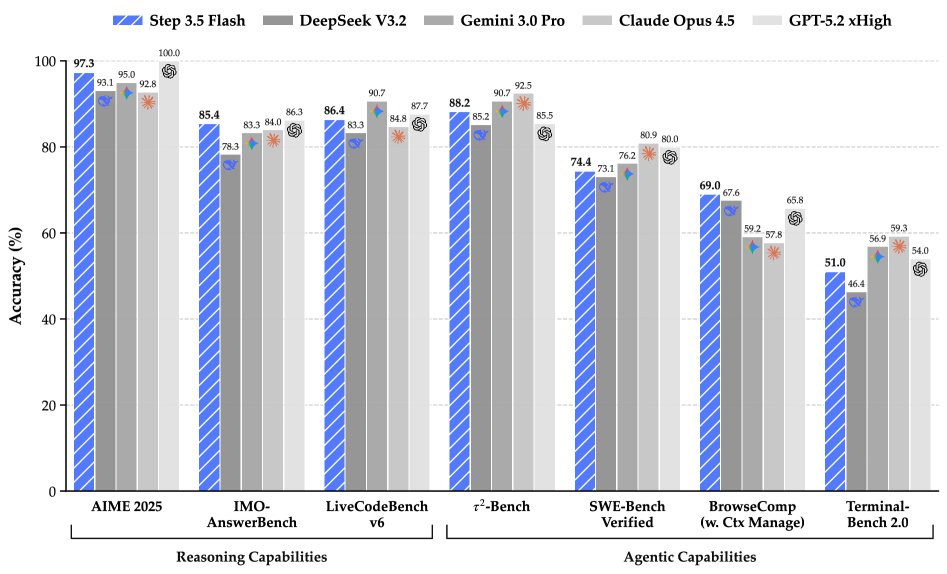
本文介绍了Step 3.5 Flash,一种稀疏的混合专家(MoE)模型,旨在桥接前沿水平的智能体能力和计算效率。该模型关注构建智能体时最重要的因素:敏锐的推理能力和快速可靠的执行能力。Step 3.5 Flash将一个196B参数的基础模型与11B的活跃参数相结合,以实现高效的推理。它通过交错的3:1滑动窗口/全注意力机制和多Token预测(MTP-3)进行优化,从而降低多轮智能体交互的延迟和成本。为了达到前沿水平的智能,设计了一个可扩展的强化学习框架,该框架结合了可验证的信号和偏好反馈,同时在大规模离策略训练下保持稳定,从而在数学、代码和工具使用方面实现持续的自我改进。Step 3.5 Flash在智能体、编码和数学任务中表现出强大的性能,在IMO-AnswerBench上达到85.4%,在LiveCodeBench-v6 (2024.08-2025.05)上达到86.4%,在tau2-Bench上达到88.2%,在BrowseComp上达到69.0%(具有上下文管理),在Terminal-Bench 2.0上达到51.0%,与GPT-5.2 xHigh和Gemini 3.0 Pro等前沿模型相当。通过重新定义效率边界,Step 3.5 Flash为在实际工业环境中部署复杂的智能体提供了一个高密度的基础。
🔬 方法详解
问题定义:现有的大型语言模型在应用于智能体任务时,往往面临计算成本高昂和推理速度慢的问题,尤其是在多轮交互场景下。如何在保证模型性能的同时,降低计算资源消耗,提高推理效率,是当前面临的主要挑战。
核心思路:Step 3.5 Flash的核心思路是利用稀疏混合专家模型(MoE)来提高计算效率,同时通过优化的注意力机制和训练方法来提升模型性能。MoE允许模型只激活部分参数进行推理,从而降低计算量。优化的注意力机制和训练方法则旨在提高模型的推理能力和泛化能力。
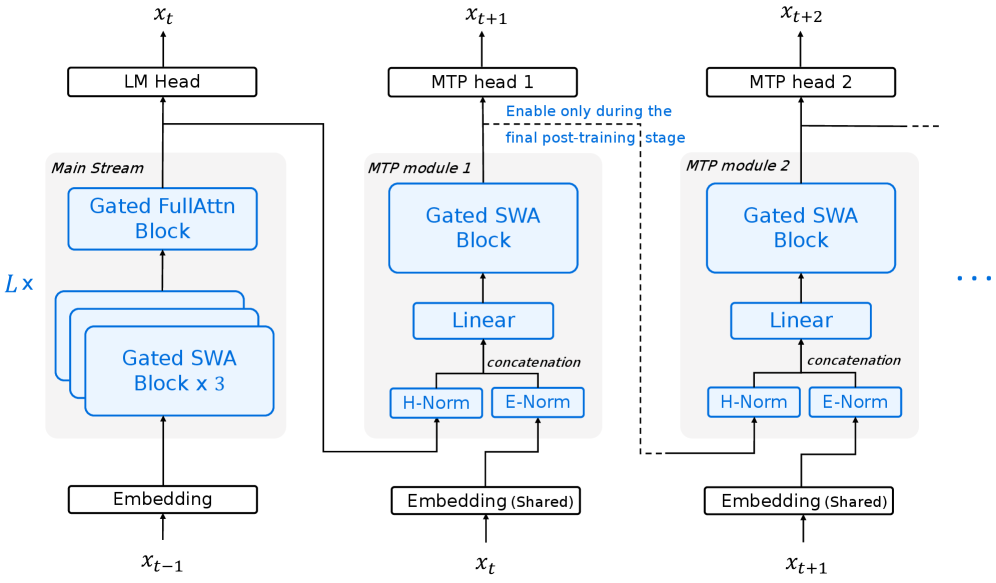
技术框架:Step 3.5 Flash的技术框架主要包括以下几个部分:1) 一个196B参数的基础模型,作为知识的载体;2) 一个稀疏MoE层,用于实现高效的推理,仅激活11B活跃参数;3) 交错的3:1滑动窗口/全注意力机制,用于降低多轮交互的延迟;4) 多Token预测(MTP-3)训练方法,用于提高模型的生成质量;5) 一个可扩展的强化学习框架,用于持续提升模型在数学、代码和工具使用方面的能力。
关键创新:Step 3.5 Flash的关键创新在于其稀疏MoE架构和优化的训练方法。稀疏MoE架构允许模型在推理时只激活部分参数,从而显著降低计算成本。交错的3:1滑动窗口/全注意力机制,在保证模型性能的同时,降低了计算复杂度。此外,可扩展的强化学习框架,结合了可验证的信号和偏好反馈,使得模型能够持续自我改进。
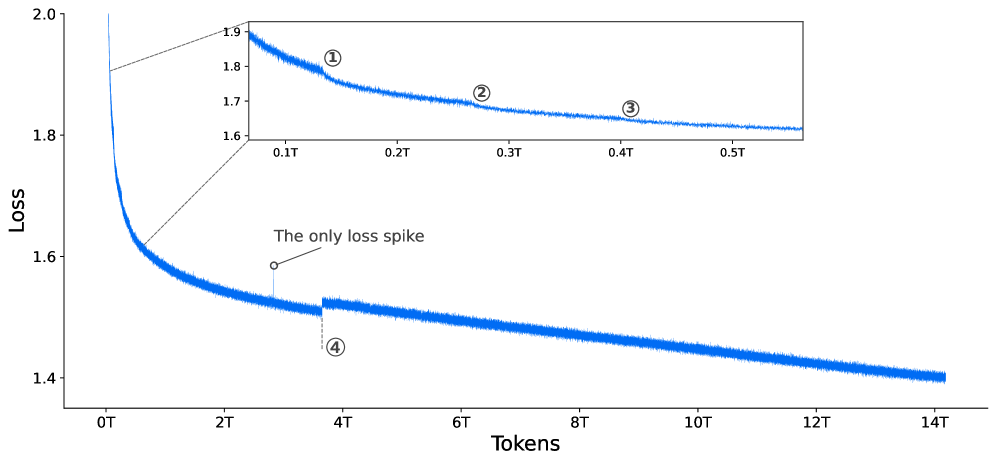
关键设计:在MoE层,模型采用了一种稀疏激活机制,只有一部分专家网络会被激活。具体激活哪些专家网络,由一个门控网络决定。门控网络的输入是当前token的表示,输出是每个专家网络的权重。模型选择权重最高的几个专家网络进行计算。在训练方面,模型采用了多Token预测(MTP-3)方法,即一次预测多个token,从而提高训练效率。强化学习框架则采用了大规模离策略训练,并结合了可验证的信号和偏好反馈,以保证训练的稳定性和效果。
🖼️ 关键图片
📊 实验亮点
Step 3.5 Flash在多个基准测试中取得了显著成果。在IMO-AnswerBench上达到85.4%,在LiveCodeBench-v6上达到86.4%,在tau2-Bench上达到88.2%,在BrowseComp上达到69.0%,在Terminal-Bench 2.0上达到51.0%。这些结果表明,Step 3.5 Flash在智能体、代码和数学任务上都具有强大的性能,与GPT-5.2 xHigh和Gemini 3.0 Pro等前沿模型相当。
🎯 应用场景
Step 3.5 Flash具有广泛的应用前景,尤其是在需要高效率和低延迟的智能体应用场景中。例如,它可以用于构建智能客服、自动化代码生成、智能数据分析等应用。其高效的推理能力和强大的性能,使其能够胜任复杂的任务,并为实际工业环境中的智能体部署提供了一个有力的基础。
📄 摘要(原文)
We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.