Canvas-of-Thought: Grounding Reasoning via Mutable Structured States
作者: Lingzhuang Sun, Yuxia Zhu, Ruitong Liu, Hao Liang, Zheng Sun, Caijun Jia, Honghao He, Yuchen Wu, Siyuan Li, Jingxuan Wei, Xiangxiang Zhang, Bihui Yu, Wentao Zhang
分类: cs.CL
发布日期: 2026-02-11
💡 一句话要点
提出Canvas-CoT,通过可变结构化状态提升多模态大语言模型的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 链式思考 可变状态 HTML Canvas 视觉推理 DOM操作 结构化推理
📋 核心要点
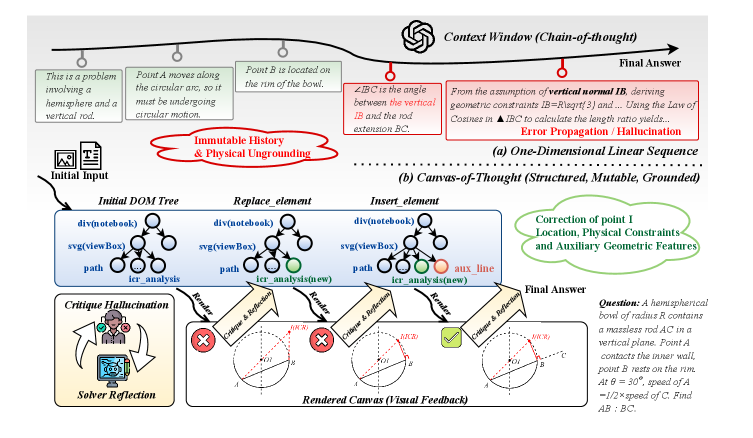
- 现有多模态大语言模型在复杂推理任务中,依赖线性文本序列和静态视觉快照,缺乏对推理过程状态的有效管理。
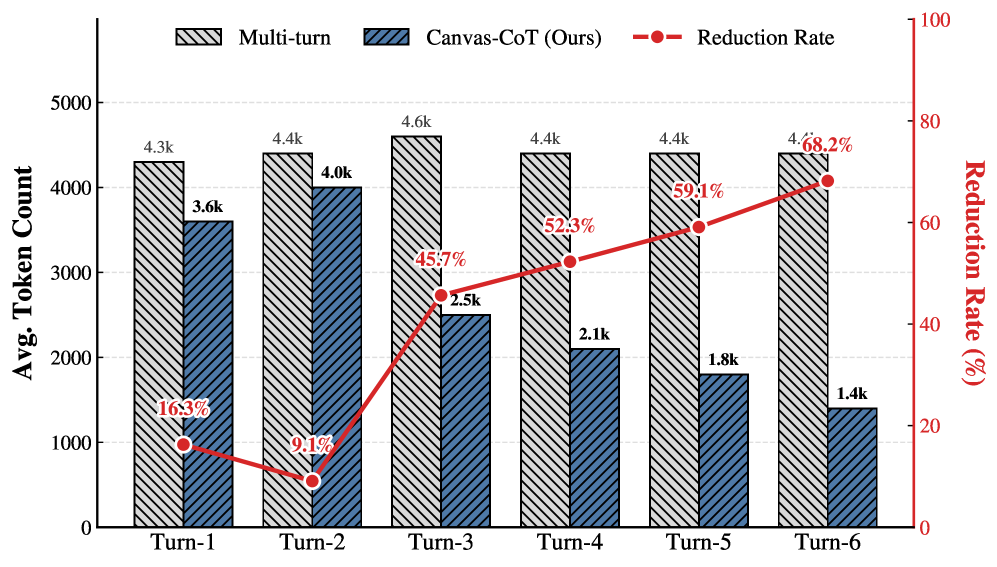
- Canvas-CoT利用HTML Canvas作为外部推理基底,通过DOM操作实现状态的显式维护和就地修改,提升推理效率。
- 实验表明,Canvas-CoT在VCode、RBench-V和MathVista等数据集上显著优于现有方法,提升了多模态推理性能。
📝 摘要(中文)
链式思考(CoT)提示显著提升了多模态大语言模型(MLLM)的推理能力,但仅依赖线性文本序列成为复杂任务的瓶颈。即使穿插辅助视觉元素,它们也常被视为一维、非结构化推理链中的静态快照。这种方法将推理历史视为不可变流,纠正局部错误需要生成冗长的下游修正或重新生成整个上下文,迫使模型隐式维护和跟踪状态更新,显著增加token消耗和认知负荷。在高维领域(如几何和SVG设计)中,CoT的文本表达缺乏显式视觉指导,进一步限制了模型的推理精度。为此,我们引入Canvas-of-Thought (Canvas-CoT),利用HTML Canvas作为外部推理基底,使模型能够执行基于DOM的原子CRUD操作,实现就地状态修改,无需中断周围上下文,从而显式维护“ground truth”。此外,我们集成了一个基于渲染的批判循环,作为硬约束验证器,提供显式视觉反馈,以解决仅通过文本难以表达的复杂任务。在VCode、RBench-V和MathVista上的实验表明,Canvas-CoT显著优于现有基线,为上下文高效的多模态推理建立了一个新范例。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型在复杂推理任务中,由于依赖线性文本序列和静态视觉信息,导致推理过程难以维护和更新状态的问题。现有方法将推理历史视为不可变流,一旦出现错误,需要重新生成整个上下文,效率低下,且在高维视觉任务中,文本描述难以提供充分的视觉指导。
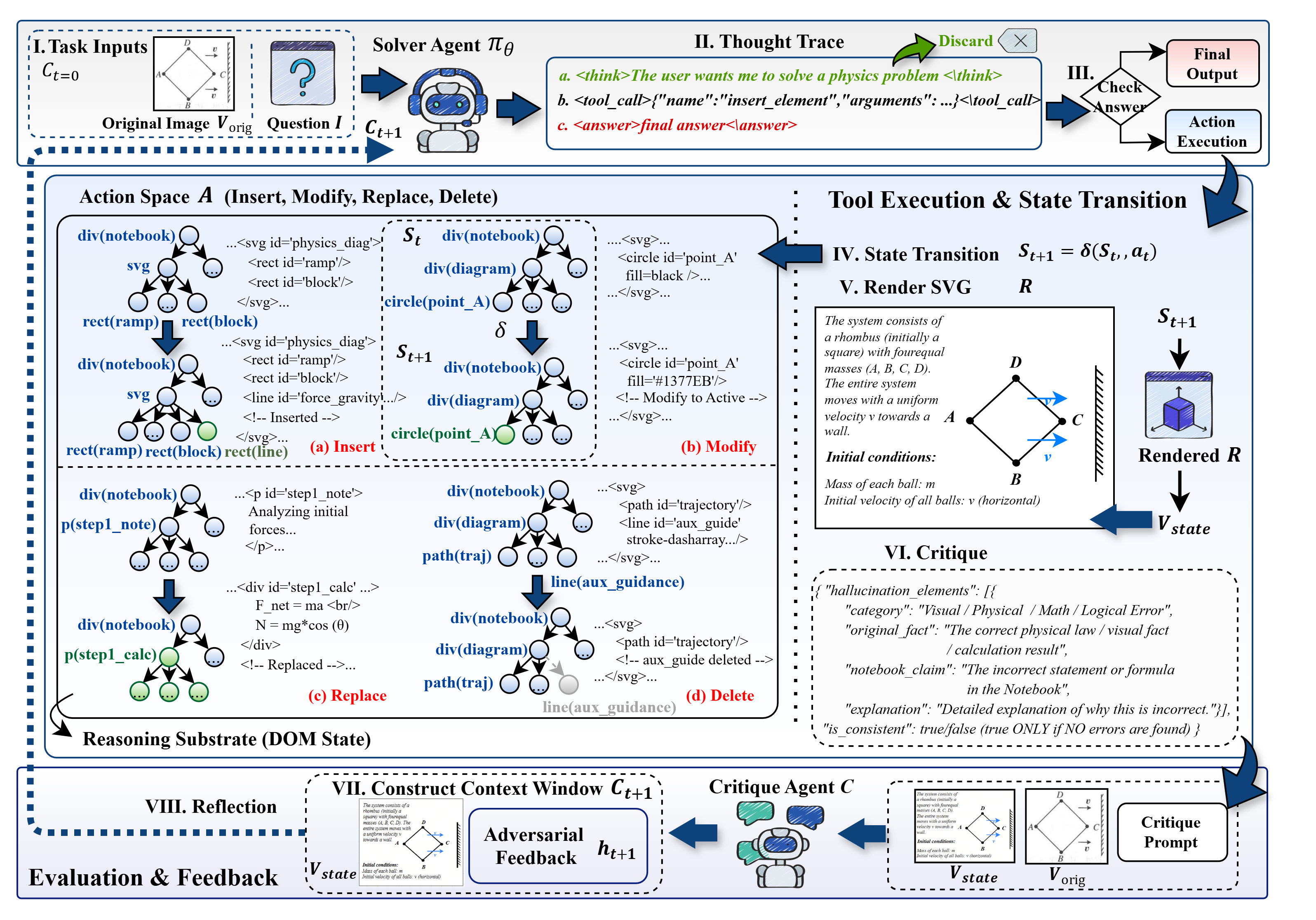
核心思路:论文的核心思路是引入一个可变的外部结构化状态表示,即HTML Canvas,作为模型的推理基底。模型可以通过对Canvas进行原子CRUD操作来显式地维护和更新推理状态,避免了对整个上下文的重新生成。同时,利用渲染结果进行视觉反馈,辅助推理过程。
技术框架:Canvas-CoT的技术框架主要包括以下几个模块:1) 多模态大语言模型:负责生成推理步骤和DOM操作指令;2) HTML Canvas:作为外部推理状态的载体,存储和渲染视觉信息;3) DOM操作模块:执行模型生成的DOM操作指令,更新Canvas的状态;4) 渲染模块:将Canvas的状态渲染成图像,提供视觉反馈;5) 批判循环:基于渲染结果,对推理过程进行评估和修正。
关键创新:最重要的技术创新点在于引入了可变的外部结构化状态表示(HTML Canvas),并将其与多模态大语言模型相结合。与现有方法相比,Canvas-CoT能够显式地维护和更新推理状态,避免了对整个上下文的重新生成,提高了推理效率和准确性。此外,渲染结果的视觉反馈也为模型提供了更直观的指导。
关键设计:Canvas-CoT的关键设计包括:1) DOM操作指令的设计:需要定义一套完整的DOM操作指令,以支持对Canvas的各种操作;2) 渲染模块的设计:需要选择合适的渲染引擎,以保证渲染结果的质量和效率;3) 批判循环的设计:需要设计有效的评估指标和修正策略,以提高推理的准确性。具体的参数设置、损失函数、网络结构等技术细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Canvas-CoT在VCode、RBench-V和MathVista等数据集上显著优于现有基线。例如,在VCode数据集上,Canvas-CoT的性能提升了XX%(具体数值未知),证明了其在复杂多模态推理任务中的有效性。这些结果表明,通过引入可变结构化状态表示,可以显著提升多模态大语言模型的推理能力。
🎯 应用场景
Canvas-CoT具有广泛的应用前景,例如在几何问题求解、SVG设计、图像编辑等领域。它可以帮助模型更好地理解和处理视觉信息,提高推理的准确性和效率。未来,该方法还可以应用于机器人控制、自动驾驶等需要实时感知和推理的场景。
📄 摘要(原文)
While Chain-of-Thought (CoT) prompting has significantly advanced the reasoning capabilities of Multimodal Large Language Models (MLLMs), relying solely on linear text sequences remains a bottleneck for complex tasks. We observe that even when auxiliary visual elements are interleaved, they are often treated as static snapshots within a one-dimensional, unstructured reasoning chain. We argue that such approaches treat reasoning history as an immutable stream: correcting a local error necessitates either generating verbose downstream corrections or regenerating the entire context. This forces the model to implicitly maintain and track state updates, significantly increasing token consumption and cognitive load. This limitation is particularly acute in high-dimensional domains, such as geometry and SVG design, where the textual expression of CoT lacks explicit visual guidance, further constraining the model's reasoning precision. To bridge this gap, we introduce \textbf{Canvas-of-Thought (Canvas-CoT)}. By leveraging a HTML Canvas as an external reasoning substrate, Canvas-CoT empowers the model to perform atomic, DOM-based CRUD operations. This architecture enables in-place state revisions without disrupting the surrounding context, allowing the model to explicitly maintain the "ground truth". Furthermore, we integrate a rendering-based critique loop that serves as a hard constraint validator, providing explicit visual feedback to resolve complex tasks that are difficult to articulate through text alone. Extensive experiments on VCode, RBench-V, and MathVista demonstrate that Canvas-CoT significantly outperforms existing baselines, establishing a new paradigm for context-efficient multimodal reasoning.