TestExplora: Benchmarking LLMs for Proactive Bug Discovery via Repository-Level Test Generation
作者: Steven Liu, Jane Luo, Xin Zhang, Aofan Liu, Hao Liu, Jie Wu, Ziyang Huang, Yangyu Huang, Yu Kang, Scarlett Li
分类: cs.SE, cs.CL
发布日期: 2026-02-11
💡 一句话要点
TestExplora:通过仓库级测试生成,评估LLM在主动缺陷发现中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 软件测试 缺陷发现 基准测试 智能体探索
📋 核心要点
- 现有软件测试评估侧重于回归预防和被动复现,忽略了在故障发生前主动发现缺陷的能力。
- TestExplora基准通过隐藏缺陷信号,要求LLM根据文档意图主动生成测试用例来发现bug。
- 实验表明,现有LLM在主动缺陷发现方面存在显著差距,智能体探索能有效提升性能。
📝 摘要(中文)
大型语言模型(LLM)越来越多地应用于自动化软件开发。全面的软件保障包含三个目标:回归预防、被动复现和主动发现。目前的评估系统性地忽略了第三个目标。它们要么将现有代码视为回归预防的真值(一种合规性陷阱),要么依赖于故障后的工件(例如,问题报告)进行错误复现,因此很少在故障发生前发现缺陷。为了弥补这一差距,我们提出了TestExplora,一个旨在评估LLM在完整、真实的仓库环境中作为主动测试者的基准。TestExplora包含来自482个仓库的2389个任务,并隐藏了所有与缺陷相关的信号。模型必须通过将实现与文档导出的意图进行比较来主动发现错误,使用文档作为oracle。此外,为了保持评估的可持续性并减少泄漏,我们提出了持续的、时间感知的数据收集。我们的评估揭示了一个显著的能力差距:最先进的模型仅达到16.06%的最大Fail-to-Pass (F2P)率。进一步的分析表明,驾驭复杂的跨模块交互和利用智能体探索对于推进LLM实现自主软件质量保证至关重要。与此一致的是,使用GPT-5-mini实例化的SWEAgent实现了17.27%的F2P和29.7%的F2P@5,突出了智能体探索在主动错误发现任务中的有效性和前景。
🔬 方法详解
问题定义:现有软件测试评估方法主要关注回归测试和基于问题报告的错误复现,缺乏对LLM在实际软件开发中主动发现潜在缺陷能力的评估。现有方法难以模拟真实软件开发场景中,开发者需要根据文档理解代码意图并发现bug的情况。
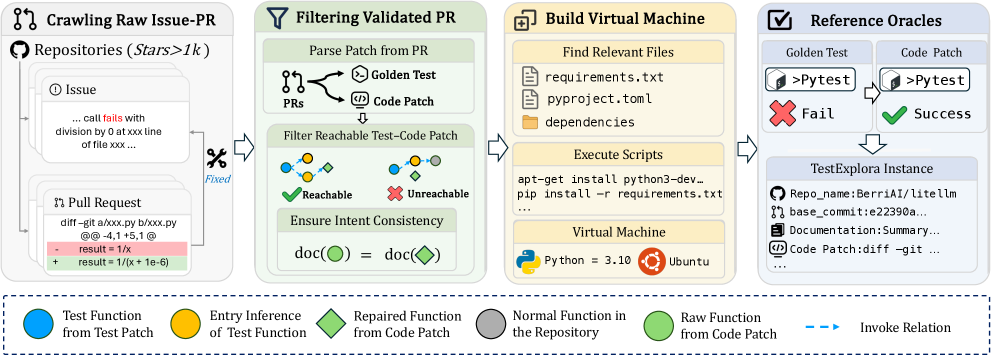
核心思路:TestExplora的核心思路是构建一个大规模、真实的软件仓库数据集,并隐藏所有与缺陷相关的信号,迫使LLM通过阅读文档理解代码意图,并生成测试用例来主动发现bug。这种方法模拟了开发者在实际开发中需要主动发现和修复bug的场景。
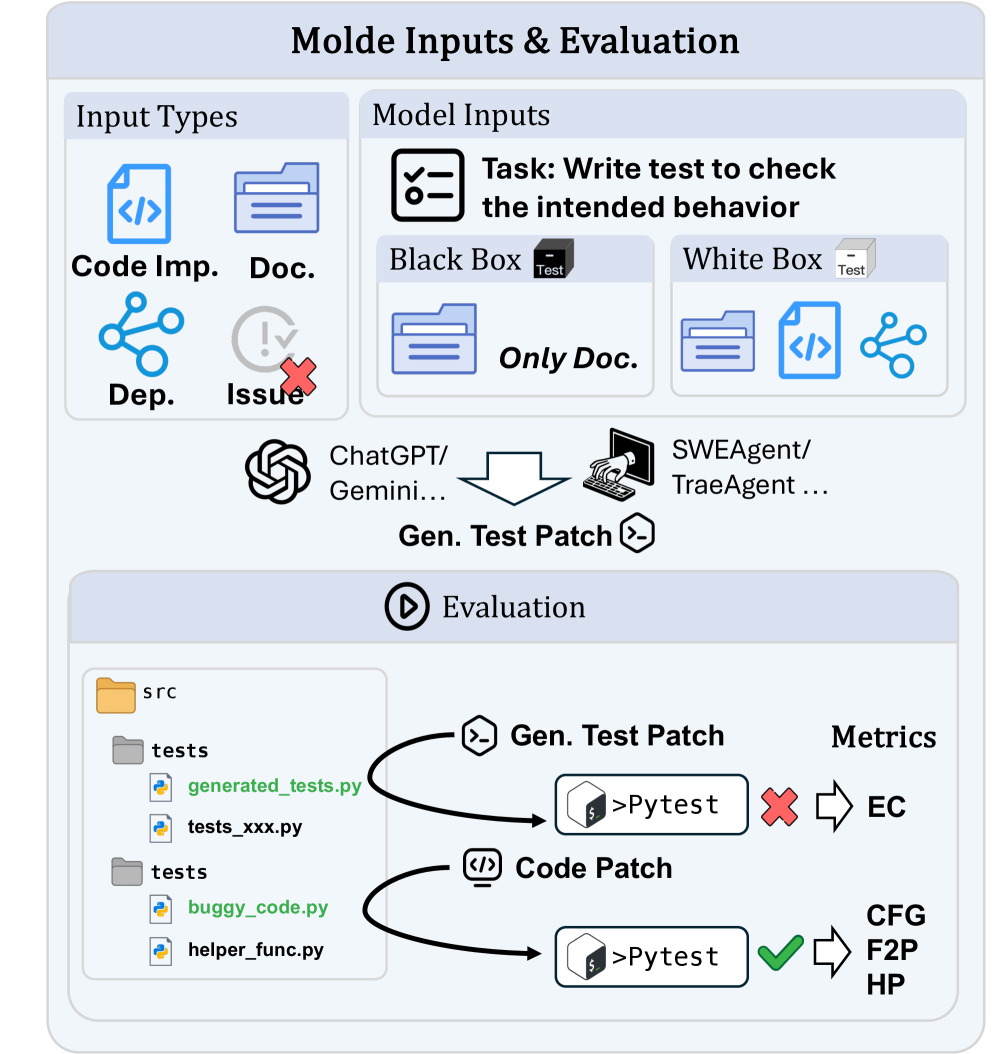
技术框架:TestExplora包含以下主要组成部分:1)从大量开源软件仓库中收集代码和文档;2)设计任务,要求LLM根据文档生成测试用例;3)隐藏所有与缺陷相关的信号,例如issue报告和commit信息;4)使用Fail-to-Pass (F2P)率作为评估指标,衡量LLM主动发现bug的能力。此外,还引入了时间感知的数据收集方法,以减少数据泄露。
关键创新:TestExplora的关键创新在于其评估LLM主动缺陷发现能力的方法。它通过构建一个大规模、真实的软件仓库数据集,并隐藏所有与缺陷相关的信号,迫使LLM像开发者一样,根据文档理解代码意图并发现bug。这种评估方法更贴近实际软件开发场景,能够更准确地评估LLM在软件质量保证方面的潜力。
关键设计:TestExplora的关键设计包括:1)选择具有良好文档的开源软件仓库;2)设计多样化的测试任务,涵盖不同的代码模块和功能;3)使用Fail-to-Pass (F2P)率作为评估指标,该指标衡量了LLM生成的测试用例能够发现bug的比例;4)引入时间感知的数据收集方法,以减少数据泄露,确保评估的公平性。
🖼️ 关键图片
📊 实验亮点
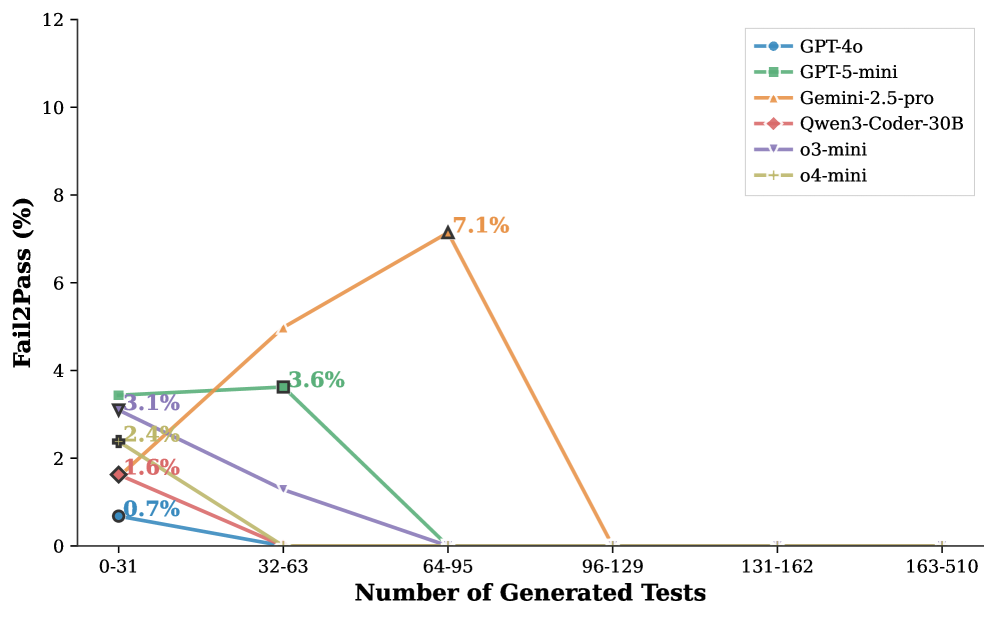
实验结果表明,现有最先进的LLM在TestExplora基准上的Fail-to-Pass (F2P)率仅为16.06%,表明LLM在主动缺陷发现方面存在显著差距。使用GPT-5-mini实例化的SWEAgent实现了17.27%的F2P和29.7%的F2P@5,表明智能体探索能有效提升LLM在主动缺陷发现任务中的性能。
🎯 应用场景
TestExplora的研究成果可应用于自动化软件测试、代码质量评估和LLM辅助软件开发等领域。通过提升LLM的主动缺陷发现能力,可以显著提高软件质量,降低开发和维护成本。未来,该研究可以扩展到更复杂的软件系统和更广泛的编程语言。
📄 摘要(原文)
Given that Large Language Models (LLMs) are increasingly applied to automate software development, comprehensive software assurance spans three distinct goals: regression prevention, reactive reproduction, and proactive discovery. Current evaluations systematically overlook the third goal. Specifically, they either treat existing code as ground truth (a compliance trap) for regression prevention, or depend on post-failure artifacts (e.g., issue reports) for bug reproduction-so they rarely surface defects before failures. To bridge this gap, we present TestExplora, a benchmark designed to evaluate LLMs as proactive testers within full-scale, realistic repository environments. TestExplora contains 2,389 tasks from 482 repositories and hides all defect-related signals. Models must proactively find bugs by comparing implementations against documentation-derived intent, using documentation as the oracle. Furthermore, to keep evaluation sustainable and reduce leakage, we propose continuous, time-aware data collection. Our evaluation reveals a significant capability gap: state-of-the-art models achieve a maximum Fail-to-Pass (F2P) rate of only 16.06%. Further analysis indicates that navigating complex cross-module interactions and leveraging agentic exploration are critical to advancing LLMs toward autonomous software quality assurance. Consistent with this, SWEAgent instantiated with GPT-5-mini achieves an F2P of 17.27% and an F2P@5 of 29.7%, highlighting the effectiveness and promise of agentic exploration in proactive bug discovery tasks.