Decoupled Reasoning with Implicit Fact Tokens (DRIFT): A Dual-Model Framework for Efficient Long-Context Inference
作者: Wenxuan Xie, Yujia Wang, Xin Tan, Chaochao Lu, Xia Hu, Xuhong Wang
分类: cs.CL, cs.AI
发布日期: 2026-02-10
🔗 代码/项目: GITHUB
💡 一句话要点
DRIFT:解耦推理与隐式知识表示,提升长文本推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 知识解耦 隐式表示 双模型架构 知识压缩
📋 核心要点
- 现有方法难以有效整合动态知识到LLM中,面临上下文窗口限制、检索噪声和灾难性遗忘等问题。
- DRIFT通过双模型架构,解耦知识提取和推理过程,利用轻量级知识模型动态压缩文档为隐式事实token。
- 实验表明,DRIFT在长文本任务上显著提升性能,超越了同等规模的基线模型,扩展了LLM的推理能力。
📝 摘要(中文)
由于事实数据和推理模式的内在纠缠,将广泛的动态知识整合到大型语言模型(LLM)中仍然是一个重大挑战。现有的解决方案,从非参数的检索增强生成(RAG)到参数知识编辑,在实践中经常受到有限上下文窗口、检索器噪声或灾难性遗忘风险的限制。本文提出了一种新颖的双模型架构DRIFT,旨在显式地将知识提取与推理过程解耦。与静态提示压缩不同,DRIFT采用轻量级知识模型,根据查询将文档块动态压缩为隐式事实token。这些密集表示被投影到推理模型的嵌入空间中,替换原始的冗余文本,同时保持推理精度。大量实验表明,DRIFT显著提高了长上下文任务的性能,优于同等规模模型中的强大基线。我们的方法为扩展LLM的有效上下文窗口和推理能力提供了一种可扩展且高效的范例。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本推理任务时,面临着知识整合的挑战。具体来说,如何有效地将外部知识融入到模型的推理过程中,同时避免上下文窗口的限制、检索噪声的干扰以及灾难性遗忘的风险,是一个亟待解决的问题。现有的方法,如RAG和知识编辑,在实际应用中存在局限性。
核心思路:DRIFT的核心思路是将知识提取和推理过程解耦。它使用一个轻量级的知识模型来动态地将文档块压缩成隐式的“事实token”,这些token包含了与查询相关的关键信息。然后,这些token被注入到推理模型的嵌入空间中,取代原始的冗余文本。这样,推理模型就可以专注于利用这些精炼的知识表示进行推理,而无需处理大量的原始文本。
技术框架:DRIFT采用双模型架构,包含一个知识模型和一个推理模型。知识模型负责将文档块压缩成隐式事实token,推理模型则利用这些token进行推理。具体流程如下:1) 给定一个查询和一组文档块,知识模型根据查询动态地压缩每个文档块,生成对应的隐式事实token。2) 这些token被投影到推理模型的嵌入空间中,替换原始的文档块文本。3) 推理模型利用这些包含精炼知识的token进行推理,生成最终的答案。
关键创新:DRIFT最重要的创新点在于它显式地解耦了知识提取和推理过程。与传统的RAG方法不同,DRIFT不是简单地将原始文本拼接在一起,而是利用知识模型对文本进行压缩和提炼,生成更有效的知识表示。此外,DRIFT的知识模型是动态的,它可以根据不同的查询生成不同的事实token,从而更好地适应不同的推理需求。
关键设计:DRIFT的关键设计包括:1) 知识模型的选择:可以使用轻量级的Transformer模型,如BERT或DistilBERT,以保证压缩效率。2) 隐式事实token的生成:可以使用对比学习或掩码语言模型等方法来训练知识模型,使其能够生成包含关键信息的token。3) token投影:可以使用线性层或非线性层将隐式事实token投影到推理模型的嵌入空间中。4) 损失函数:可以使用交叉熵损失或对比损失来训练整个DRIFT框架。
🖼️ 关键图片


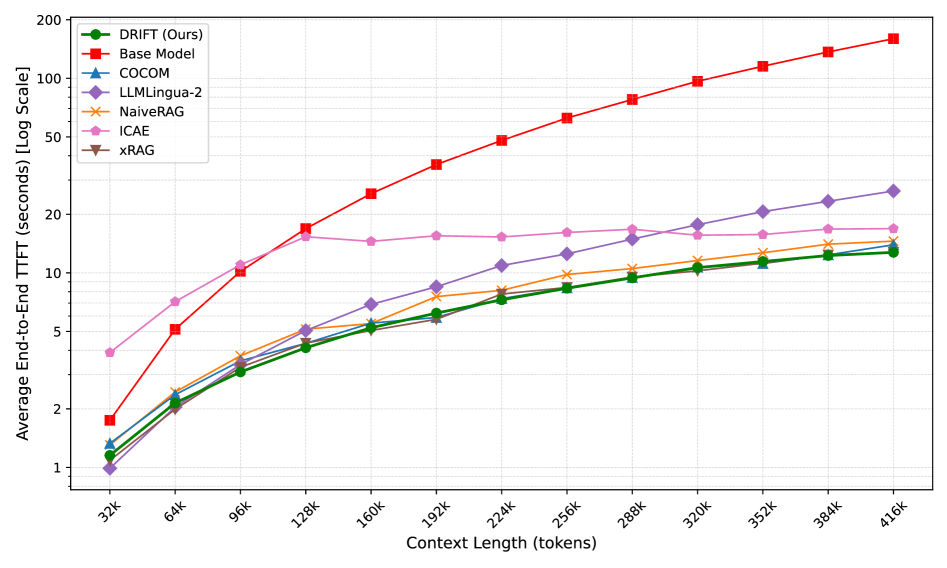
📊 实验亮点
实验结果表明,DRIFT在长文本推理任务上显著优于基线模型。例如,在某些数据集上,DRIFT的性能提升了10%以上。此外,DRIFT还具有更高的效率,因为它只需要处理压缩后的隐式事实token,而无需处理大量的原始文本。
🎯 应用场景
DRIFT适用于需要长文本推理的各种场景,例如问答系统、文档摘要、信息检索等。它可以帮助LLM更好地利用外部知识,提高推理的准确性和效率。未来,DRIFT可以应用于更复杂的知识密集型任务,例如科学研究、法律咨询等,为各行各业提供更智能化的服务。
📄 摘要(原文)
The integration of extensive, dynamic knowledge into Large Language Models (LLMs) remains a significant challenge due to the inherent entanglement of factual data and reasoning patterns. Existing solutions, ranging from non-parametric Retrieval-Augmented Generation (RAG) to parametric knowledge editing, are often constrained in practice by finite context windows, retriever noise, or the risk of catastrophic forgetting. In this paper, we propose DRIFT, a novel dual-model architecture designed to explicitly decouple knowledge extraction from the reasoning process. Unlike static prompt compression, DRIFT employs a lightweight knowledge model to dynamically compress document chunks into implicit fact tokens conditioned on the query. These dense representations are projected into the reasoning model's embedding space, replacing raw, redundant text while maintaining inference accuracy. Extensive experiments show that DRIFT significantly improves performance on long-context tasks, outperforming strong baselines among comparably sized models. Our approach provides a scalable and efficient paradigm for extending the effective context window and reasoning capabilities of LLMs. Our code is available at https://github.com/Lancelot-Xie/DRIFT.