Steer2Edit: From Activation Steering to Component-Level Editing
作者: Chung-En Sun, Ge Yan, Zimo Wang, Tsui-Wei Weng
分类: cs.CL
发布日期: 2026-02-10
💡 一句话要点
提出Steer2Edit以解决大语言模型行为控制问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 行为控制 权重编辑 推理效率 安全性提升
📋 核心要点
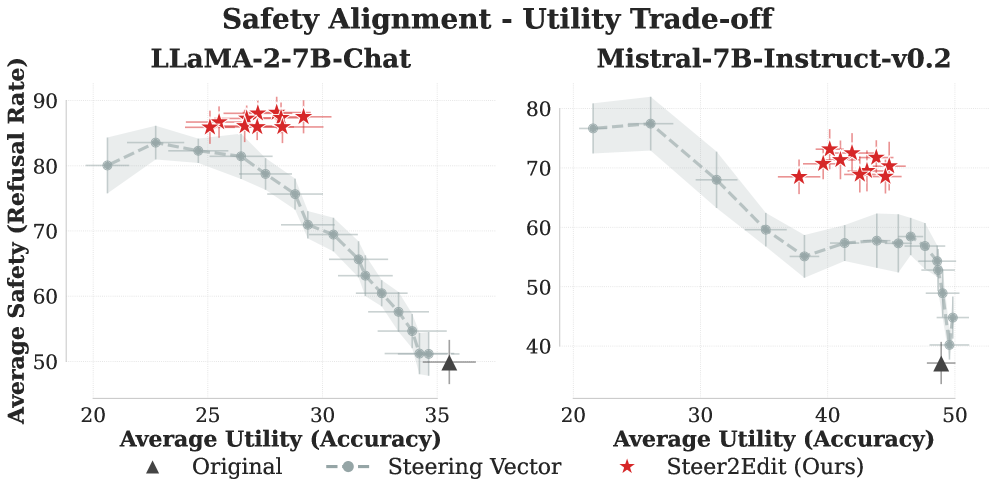
- 现有的引导方法在推理时通过全局修改影响模型行为,导致属性与效用之间的不利权衡。
- Steer2Edit通过将引导向量转化为组件级的权重编辑信号,选择性地影响各个注意力头和MLP神经元。
- 实验表明,Steer2Edit在安全性、真实性和推理效率上均有显著提升,改善了属性与效用的权衡。
📝 摘要(中文)
Steer2Edit是一种理论基础扎实、无需训练的框架,旨在将推理时的控制信号转化为组件级的权重编辑信号。现有的引导方法通常通过固定的全局修改来影响模型的内部状态,导致属性与效用之间的不利权衡。Steer2Edit通过选择性地重新分配行为影响,提升了安全性、真实性和推理效率,提供了可解释的编辑效果。实验结果显示,在匹配的下游性能下,Steer2Edit在安全性上提高了17.2%,真实性提升了9.8%,推理长度平均减少了12.2%。
🔬 方法详解
问题定义:现有的引导方法在推理时通过全局修改影响模型的内部状态,导致属性与效用之间的不利权衡,忽视了模型行为由少量异质组件主导的事实。
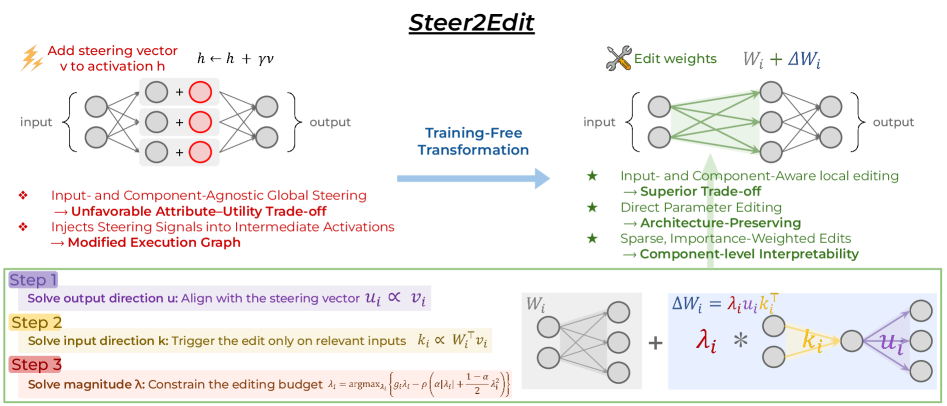
核心思路:Steer2Edit提出了一种训练-free的框架,将推理时的控制信号转化为组件级的权重编辑信号,选择性地影响模型的不同部分,以实现可解释的编辑效果。
技术框架:该框架主要包括两个阶段:首先,通过推理时的控制信号生成引导向量;其次,将这些引导向量转化为针对特定组件的权重编辑信号,重新分配行为影响。
关键创新:Steer2Edit的核心创新在于将引导信号转化为可解释的参数更新,而不是简单的全局修改,这使得模型在保持标准前向传播的同时,能够进行更细粒度的控制。
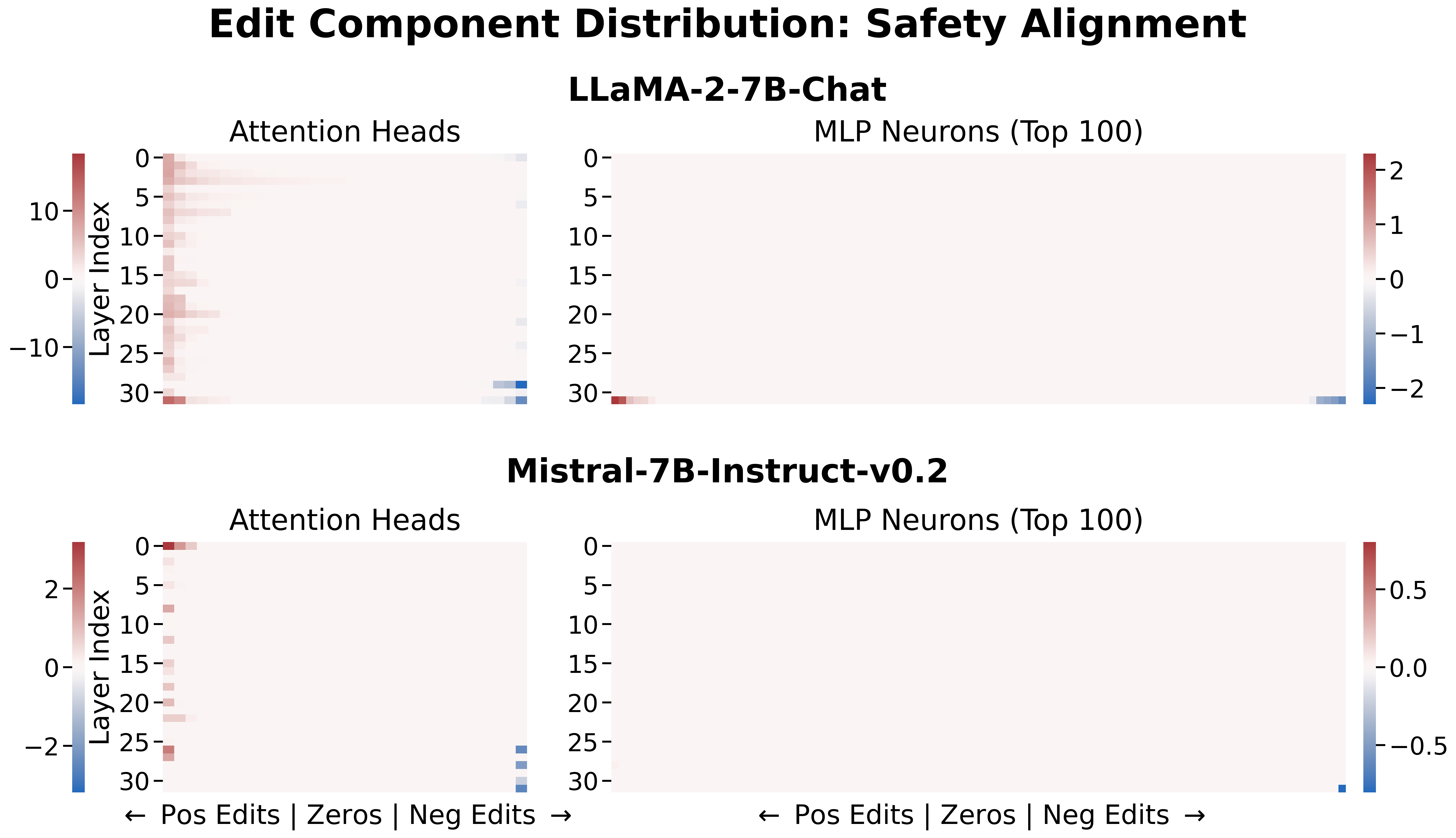
关键设计:在设计中,Steer2Edit通过选择性地注入引导方向,针对不同的注意力头和MLP神经元进行影响,确保了与优化的并行推理兼容,同时保持了模型的整体性能。
🖼️ 关键图片
📊 实验亮点
实验结果显示,Steer2Edit在安全性上提高了17.2%,在真实性上提升了9.8%,并且推理长度平均减少了12.2%。这些结果表明,Steer2Edit在属性与效用的权衡上表现优于现有方法,具有显著的实用价值。
🎯 应用场景
Steer2Edit的研究成果在多个领域具有潜在应用价值,包括自然语言处理中的对话系统、文本生成和内容审核等。通过更精细的行为控制,能够提升模型的安全性和真实性,减少不必要的推理复杂性,进而推动智能系统的可靠性和用户信任。未来,该方法可能在更广泛的AI应用中发挥重要作用。
📄 摘要(原文)
Steering methods influence Large Language Model behavior by identifying semantic directions in hidden representations, but are typically realized through inference-time activation interventions that apply a fixed, global modification to the model's internal states. While effective, such interventions often induce unfavorable attribute-utility trade-offs under strong control, as they ignore the fact that many behaviors are governed by a small and heterogeneous subset of model components. We propose Steer2Edit, a theoretically grounded, training-free framework that transforms steering vectors from inference-time control signals into diagnostic signals for component-level rank-1 weight editing. Instead of uniformly injecting a steering direction during generation, Steer2Edit selectively redistributes behavioral influence across individual attention heads and MLP neurons, yielding interpretable edits that preserve the standard forward pass and remain compatible with optimized parallel inference. Across safety alignment, hallucination mitigation, and reasoning efficiency, Steer2Edit consistently achieves more favorable attribute-utility trade-offs: at matched downstream performance, it improves safety by up to 17.2%, increases truthfulness by 9.8%, and reduces reasoning length by 12.2% on average. Overall, Steer2Edit provides a principled bridge between representation steering and weight editing by translating steering signals into interpretable, training-free parameter updates.