LLM Reasoning Predicts When Models Are Right: Evidence from Coding Classroom Discourse
作者: Bakhtawar Ahtisham, Kirk Vanacore, Zhuqian Zhou, Jinsook Lee, Rene F. Kizilcec
分类: cs.CL
发布日期: 2026-02-10
💡 一句话要点
利用LLM推理预测模型在教育对话分析中的正确性,提升自动化标注质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 教育对话分析 错误检测 推理过程 自动化标注 质量控制 随机森林 LIWC分析
📋 核心要点
- 现有教育对话分析依赖LLM自动标注,但缺乏有效手段检测模型错误,影响分析质量。
- 利用LLM生成的推理过程,预测其自身标注的正确性,从而实现错误检测与质量控制。
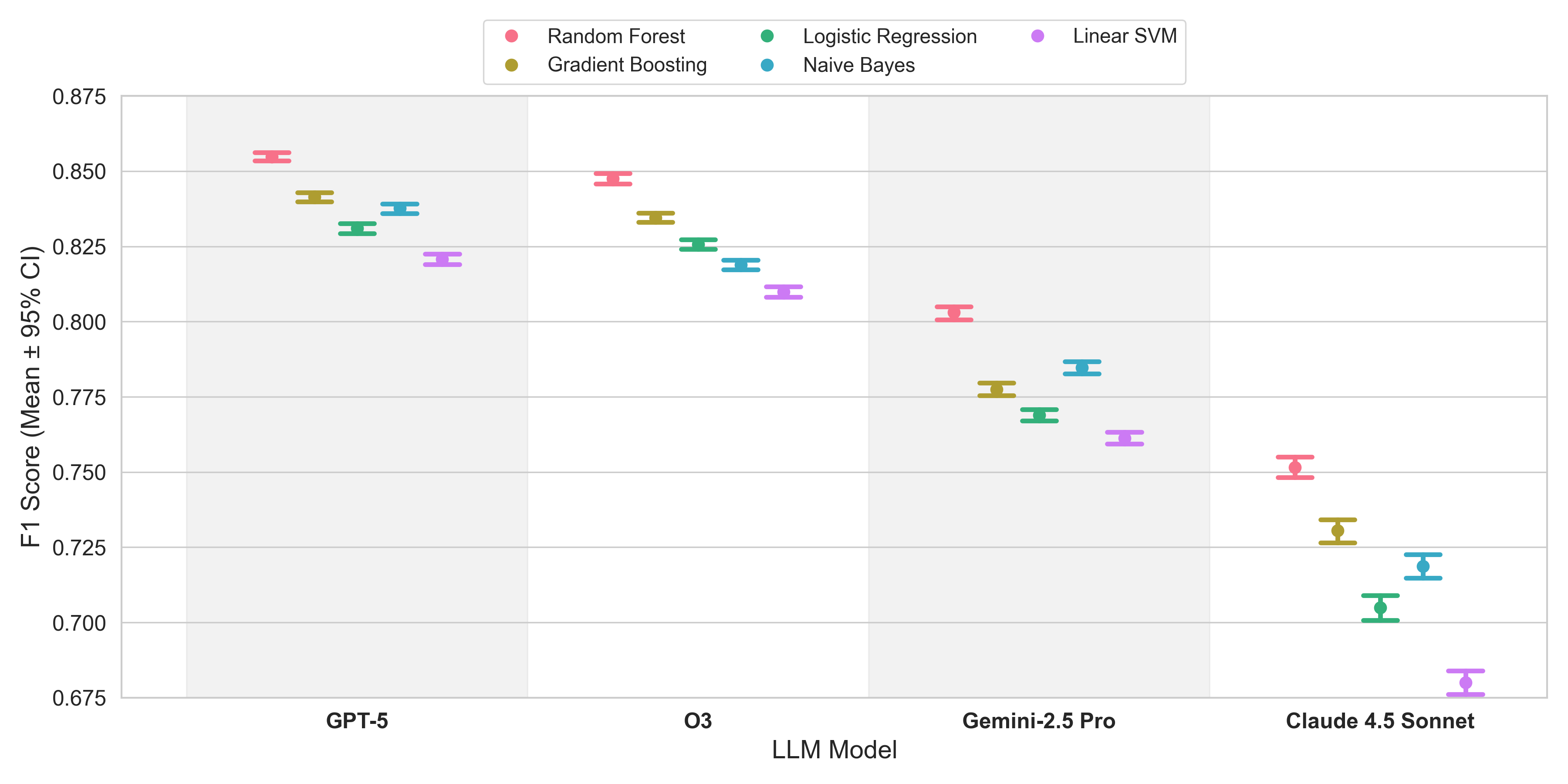
- 实验表明,基于推理的随机森林分类器能有效识别错误预测,F1值达0.83,显著优于基线。
📝 摘要(中文)
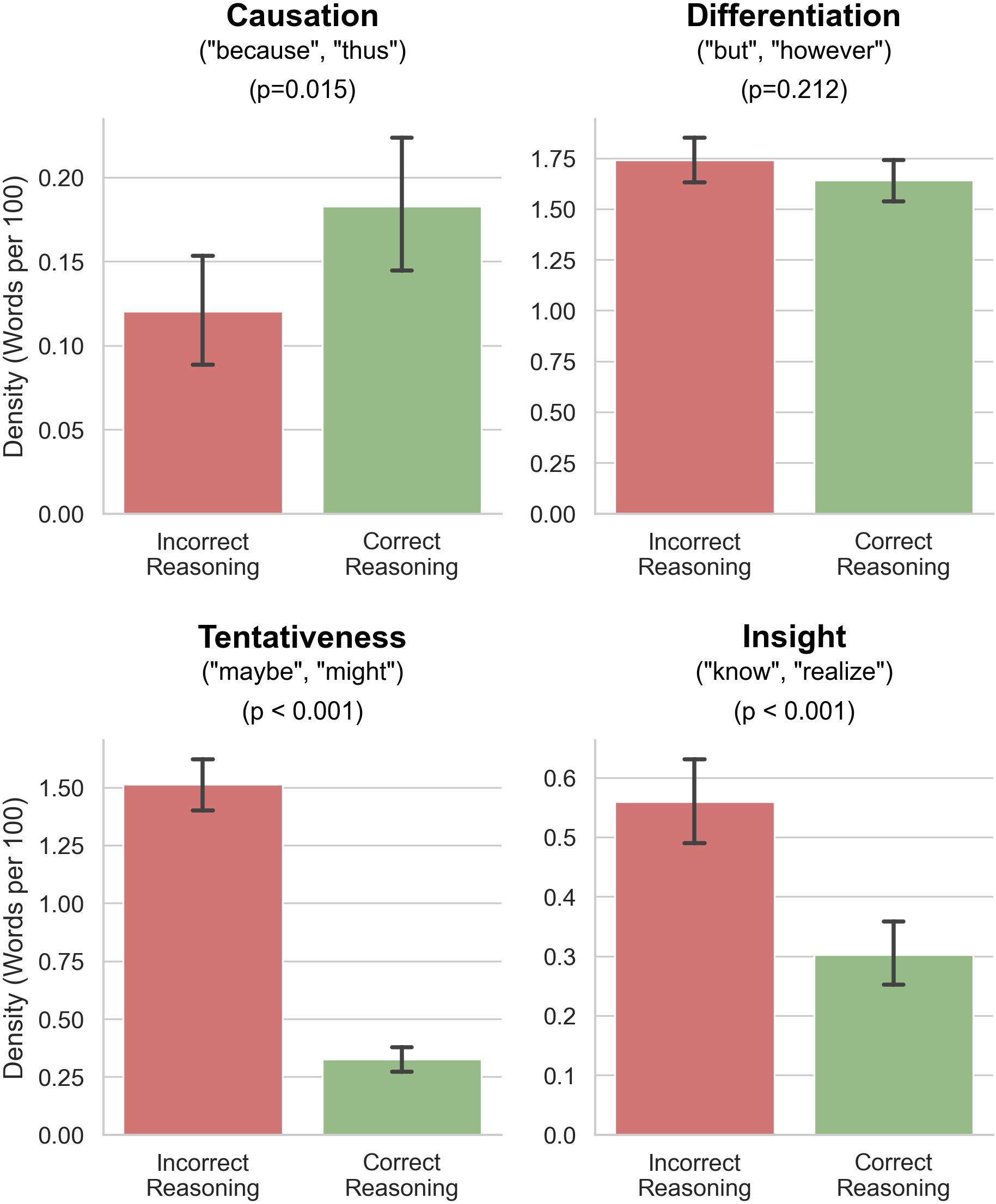
大型语言模型(LLM)越来越多地被用于大规模自动标注和分析教育对话,但目前的流程缺乏可靠的方法来检测模型的错误。本文研究了LLM生成的推理是否可以用来预测模型自身预测的正确性。我们分析了课堂对话中的30300条教师话语,每条话语都由多个最先进的LLM标注了教学行为结构,并附有推理。使用人工验证的ground-truth标签,我们将任务定义为预测模型为给定话语分配的标签是否正确。我们使用词频-逆文档频率(TF-IDF)对LLM推理进行编码,并评估了五个监督分类器。随机森林分类器实现了0.83的F1分数(召回率=0.854),成功识别了大多数不正确的预测,并优于基线。针对特定教学行为结构训练专门的检测器进一步提高了困难结构上的性能,表明错误检测受益于特定于结构的语言线索。使用语言调查和词计数(LIWC)框架,我们检查了正确性的四个语言标记:因果关系、差异化、试探性和洞察力。正确的预测表现出有根据的因果语言(例如,因为,因此),而不正确的推理更可能依赖于认知对冲(例如,可能,可以)和表现性元认知(例如,认为,意识到)。句法复杂性不能区分正确和不正确的推理,更长的推理并不更可靠。这些发现表明,基于推理的错误检测为自动化教育对话分析中的质量控制提供了一种实用且可扩展的方法。
🔬 方法详解
问题定义:论文旨在解决教育场景下,利用大型语言模型(LLM)自动标注课堂对话数据时,如何有效检测并纠正LLM产生的错误标注的问题。现有方法缺乏可靠的错误检测机制,导致下游分析结果可能存在偏差,影响教育研究的准确性。
核心思路:论文的核心思路是利用LLM在进行标注时生成的“推理过程”文本,作为判断标注正确性的依据。如果LLM的推理过程能够清晰、合理地支持其标注结果,则认为该标注更可能是正确的;反之,如果推理过程模糊、矛盾或包含不确定性,则认为该标注更可能是错误的。
技术框架:整体框架包含以下几个主要阶段: 1. 数据收集与标注:收集课堂对话数据,并使用多个LLM进行自动标注,同时记录LLM的推理过程。 2. 特征提取:使用TF-IDF方法对LLM生成的推理文本进行编码,提取文本特征。 3. 模型训练:使用人工标注的ground-truth数据,训练监督分类器(如随机森林)来预测LLM标注的正确性。 4. 语言学分析:使用LIWC框架分析正确和错误推理的语言特征,寻找与正确性相关的语言标记。
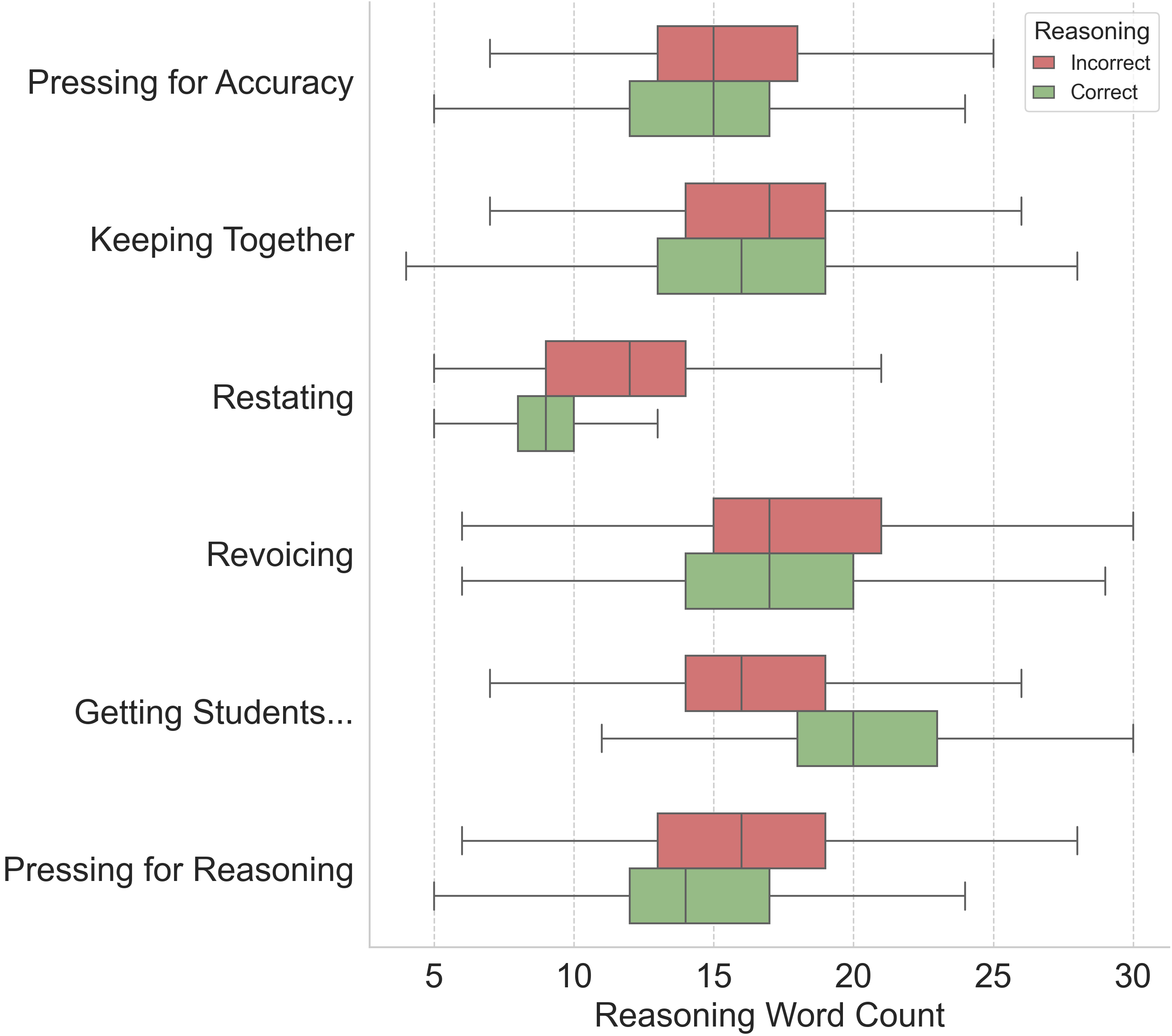
关键创新:论文的关键创新在于将LLM的推理过程作为一种可利用的信号,用于评估其自身标注的质量。这与以往主要关注模型输出结果的错误检测方法不同,提供了一种新的视角和解决方案。此外,针对特定教学行为结构训练专门的检测器,进一步提升了错误检测的精度。
关键设计: * TF-IDF编码:使用TF-IDF将LLM的推理文本转换为数值特征,以便用于机器学习模型的训练。 * 随机森林分类器:选择随机森林作为主要的分类模型,因为它具有较好的泛化能力和可解释性。 * LIWC分析:使用LIWC框架分析推理文本的语言特征,例如因果关系、差异化、试探性和洞察力等,以寻找与标注正确性相关的语言模式。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于LLM推理的随机森林分类器在预测标注正确性方面表现出色,F1值达到0.83,召回率达到0.854,显著优于基线方法。针对特定教学行为结构训练的专门检测器进一步提升了性能。LIWC分析揭示了正确和错误推理在语言特征上的差异,例如,正确的预测更倾向于使用因果语言。
🎯 应用场景
该研究成果可应用于大规模教育对话数据的自动分析与标注,提高标注质量,降低人工审核成本。通过识别LLM的错误标注,可以提升教育数据挖掘、个性化学习推荐等下游任务的准确性。此外,该方法也为其他领域中利用LLM进行自动化任务的质量控制提供了借鉴。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed to automatically label and analyze educational dialogue at scale, yet current pipelines lack reliable ways to detect when models are wrong. We investigate whether reasoning generated by LLMs can be used to predict the correctness of a model's own predictions. We analyze 30,300 teacher utterances from classroom dialogue, each labeled by multiple state-of-the-art LLMs with an instructional move construct and an accompanying reasoning. Using human-verified ground-truth labels, we frame the task as predicting whether a model's assigned label for a given utterance is correct. We encode LLM reasoning using Term Frequency-Inverse Document Frequency (TF-IDF) and evaluate five supervised classifiers. A Random Forest classifier achieves an F1 score of 0.83 (Recall = 0.854), successfully identifying most incorrect predictions and outperforming baselines. Training specialist detectors for specific instructional move constructs further improves performance on difficult constructs, indicating that error detection benefits from construct-specific linguistic cues. Using the Linguistic Inquiry and Word Count (LIWC) framework, we examine four linguistic markers of correctness: Causation, Differentiation, Tentativeness, and Insight. Correct predictions exhibit grounded causal language (e.g., because, therefore), while incorrect reasoning is substantially more likely to rely on epistemic hedging (e.g., might, could) and performative metacognition (e.g., think, realize). Syntactic complexity does not distinguish correct from incorrect reasoning, and longer reasoning is not more reliable. These findings demonstrate that reasoning-based error detection offers a practical and scalable approach to quality control in automated educational dialogue analysis.