Covo-Audio Technical Report
作者: Wenfu Wang, Chenxing Li, Liqiang Zhang, Yiyang Zhao, Yuxiang Zou, Hanzhao Li, Mingyu Cui, Hao Zhang, Kun Wei, Le Xu, Zikang Huang, Jiajun Xu, Jiliang Hu, Xiang He, Zeyu Xie, Jiawen Kang, Youjun Chen, Meng Yu, Dong Yu, Rilin Chen, Linlin Di, Shulin Feng, Na Hu, Yang Liu, Bang Wang, Shan Yang
分类: cs.SD, cs.CL, eess.AS
发布日期: 2026-02-10
备注: Technical Report
💡 一句话要点
Covo-Audio:一个70亿参数的端到端音频大语言模型,实现多任务音频智能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频大语言模型 端到端学习 语音对话系统 全双工交互 预训练模型 语音理解 智能扬声器
📋 核心要点
- 现有语音交互系统通常依赖多个独立模块,导致性能瓶颈和部署成本高昂。Covo-Audio旨在构建一个统一的端到端模型,直接处理音频并生成音频,简化流程。
- Covo-Audio采用大规模预训练和针对性后训练,使其在多种音频任务上表现出色。同时,提出智能扬声器解耦策略,降低部署成本。
- 实验结果表明,Covo-Audio在语音-文本理解、语义推理和对话能力方面优于同等规模的开源模型,并在全双工交互中表现出卓越的性能。
📝 摘要(中文)
本文介绍了Covo-Audio,一个拥有70亿参数的端到端LALM(Large Audio Language Model),它采用统一的架构直接处理连续音频输入并生成音频输出。通过大规模的预训练和有针对性的后训练,Covo-Audio在包括语音-文本建模、口语对话、语音理解、音频理解和全双工语音交互等广泛的任务中,实现了与同等规模模型相比,最先进或具有竞争力的性能。广泛的评估表明,预训练的基础模型在多个基准测试中表现出强大的语音-文本理解和语义推理能力,优于具有代表性的同等规模开源模型。此外,面向对话的变体Covo-Audio-Chat展示了强大的口语对话能力,包括理解、上下文推理、指令遵循以及生成上下文适当且富有同情心的响应,验证了其在实际对话助手场景中的适用性。演进的全双工模型Covo-Audio-Chat-FD在口语对话能力和全双工交互行为方面均取得了显著优越的性能,证明了其在实际鲁棒性方面的能力。为了缓解部署端到端LALM用于自然对话系统的高成本,我们提出了一种智能扬声器解耦策略,该策略将对话智能与语音渲染分离,从而能够以最少的文本到语音(TTS)数据实现灵活的语音定制,同时保持对话性能。总的来说,我们的结果突出了70亿规模模型将复杂的音频智能与高层次语义推理相结合的强大潜力,并提出了一个通往更强大和通用的LALM的可扩展路径。
🔬 方法详解
问题定义:现有语音交互系统通常由多个独立的模块组成,例如自动语音识别(ASR)、自然语言理解(NLU)、对话管理(DM)和文本到语音(TTS)。这种pipeline式的架构存在多个问题:误差累积、优化困难、部署成本高昂。Covo-Audio旨在解决这些问题,构建一个端到端的音频大语言模型,直接处理音频输入并生成音频输出,从而简化流程并提高性能。
核心思路:Covo-Audio的核心思路是利用大规模预训练和针对性后训练,使模型能够学习到丰富的语音、语言和对话知识。通过统一的架构,模型可以同时处理多种音频任务,例如语音识别、语音理解、对话生成等。此外,为了降低部署成本,论文提出了智能扬声器解耦策略,将对话智能与语音渲染分离。
技术框架:Covo-Audio的整体架构是一个基于Transformer的端到端模型。该模型包含一个音频编码器、一个语言模型和一个音频解码器。音频编码器将输入的音频信号转换为高维特征表示,语言模型利用这些特征进行语义理解和对话生成,音频解码器将生成的文本转换为音频输出。Covo-Audio-Chat-FD在此基础上增加了全双工交互模块,以支持更自然的对话体验。
关键创新:Covo-Audio的关键创新在于其端到端的架构和大规模预训练策略。传统的语音交互系统通常依赖多个独立的模块,而Covo-Audio将这些模块集成到一个统一的模型中,从而避免了误差累积和优化困难。大规模预训练使模型能够学习到丰富的语音、语言和对话知识,从而提高了模型的性能。
关键设计:Covo-Audio的关键设计包括:1) 使用Transformer作为模型的基本架构;2) 采用大规模的预训练数据集,包括语音、文本和对话数据;3) 设计针对性的后训练任务,以提高模型在特定任务上的性能;4) 提出智能扬声器解耦策略,以降低部署成本。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述。
🖼️ 关键图片
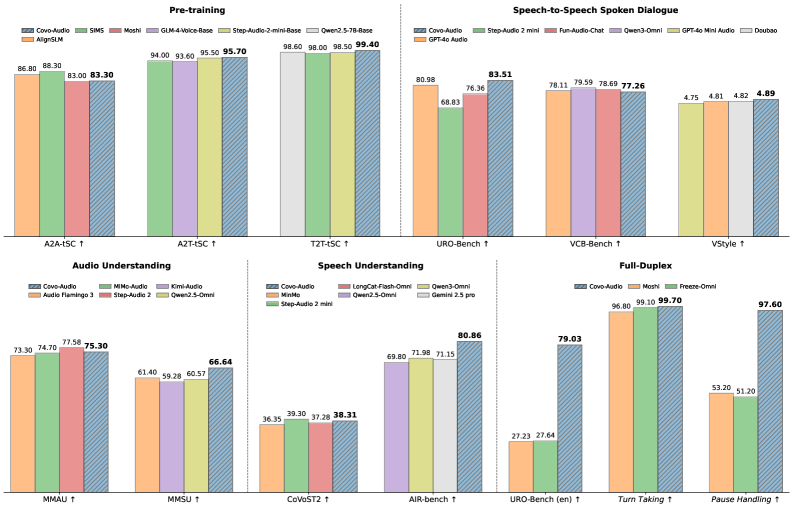
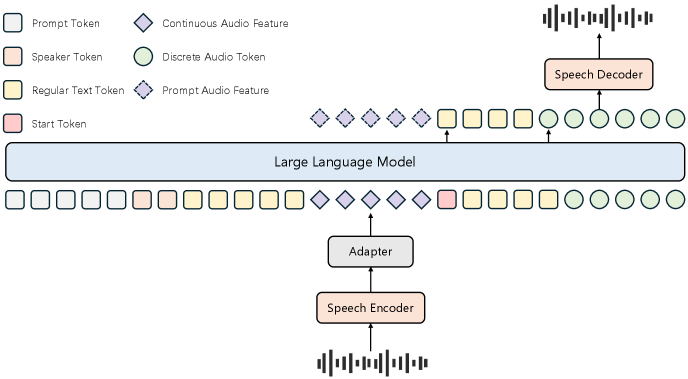

📊 实验亮点
Covo-Audio在多个基准测试中取得了优异的性能。例如,在语音-文本理解任务中,Covo-Audio优于同等规模的开源模型。Covo-Audio-Chat在口语对话能力方面表现出色,能够生成上下文适当且富有同情心的响应。Covo-Audio-Chat-FD在全双工交互方面取得了显著的性能提升,证明了其在实际鲁棒性方面的能力。
🎯 应用场景
Covo-Audio具有广泛的应用前景,包括智能助手、语音搜索、语音翻译、语音游戏等。它可以应用于各种设备,例如智能手机、智能音箱、智能汽车等。该研究的实际价值在于提高语音交互系统的性能和降低部署成本,未来可能推动语音交互技术在更多领域的应用。
📄 摘要(原文)
In this work, we present Covo-Audio, a 7B-parameter end-to-end LALM that directly processes continuous audio inputs and generates audio outputs within a single unified architecture. Through large-scale curated pretraining and targeted post-training, Covo-Audio achieves state-of-the-art or competitive performance among models of comparable scale across a broad spectrum of tasks, including speech-text modeling, spoken dialogue, speech understanding, audio understanding, and full-duplex voice interaction. Extensive evaluations demonstrate that the pretrained foundation model exhibits strong speech-text comprehension and semantic reasoning capabilities on multiple benchmarks, outperforming representative open-source models of comparable scale. Furthermore, Covo-Audio-Chat, the dialogue-oriented variant, demonstrates strong spoken conversational abilities, including understanding, contextual reasoning, instruction following, and generating contextually appropriate and empathetic responses, validating its applicability to real-world conversational assistant scenarios. Covo-Audio-Chat-FD, the evolved full-duplex model, achieves substantially superior performance on both spoken dialogue capabilities and full-duplex interaction behaviors, demonstrating its competence in practical robustness. To mitigate the high cost of deploying end-to-end LALMs for natural conversational systems, we propose an intelligence-speaker decoupling strategy that separates dialogue intelligence from voice rendering, enabling flexible voice customization with minimal text-to-speech (TTS) data while preserving dialogue performance. Overall, our results highlight the strong potential of 7B-scale models to integrate sophisticated audio intelligence with high-level semantic reasoning, and suggest a scalable path toward more capable and versatile LALMs.