Decomposing Reasoning Efficiency in Large Language Models
作者: Daniel Kaiser, Arnoldo Frigessi, Ali Ramezani-Kebrya, Benjamin Ricaud
分类: cs.CL, cs.AI, cs.LG
发布日期: 2026-02-10
备注: Preprint (under review). 29 pages, 4 figures
💡 一句话要点
提出可分解推理效率的框架,揭示大语言模型推理过程中的效率瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理效率 Token效率 效率分解 性能评估
📋 核心要点
- 现有大语言模型评估侧重最终准确率,忽略了推理过程中token的效率问题,无法有效分析token的利用情况。
- 论文提出一种trace-optional框架,将token效率分解为补全情况、条件正确性和冗余度等可解释的因素。
- 实验表明,准确率和token效率排名存在差异,效率瓶颈各异,提示需要针对性地进行效率优化干预。
📝 摘要(中文)
大型语言模型在推理过程中需要在推理token数量和准确率之间进行权衡,但标准评估方法只报告最终准确率,忽略了token的使用情况。本文提出了一种trace-optional框架,将token效率分解为可解释的因素:固定token预算下的补全情况(避免截断)、给定补全的条件正确性以及冗余度(token使用量)。当基准元数据提供每个实例的工作量代理时,进一步将冗余度分解为两个组成部分:平均verbalization开销(每个工作单元的token数)和一个耦合系数,用于捕获开销如何随任务工作量而变化。当推理trace可用时,添加确定性的trace质量度量(grounding、重复、prompt复制),以区分退化的循环和verbose但参与的推理,避免人工标注和LLM判断。在CogniLoad上评估了25个模型,发现准确率和token效率排名存在差异(Spearman $ρ=0.63$),效率差距通常由条件正确性驱动,并且verbalization开销变化约为9倍(与模型规模只有微弱关系)。分解结果揭示了不同的瓶颈,表明需要不同的效率干预措施。
🔬 方法详解
问题定义:现有的大语言模型评估方法主要关注最终的准确率,而忽略了推理过程中token的使用效率。这意味着我们无法了解模型在推理过程中是否浪费了token,或者token主要消耗在哪些环节。这阻碍了我们对模型推理过程的深入理解,也难以针对性地进行优化。
核心思路:论文的核心思路是将大语言模型的推理效率分解为多个可解释的因素,从而更细粒度地分析token的使用情况。通过分解,可以识别出影响推理效率的关键瓶颈,例如补全不完整、条件正确性差、冗余度过高等。
技术框架:该框架主要包含以下几个阶段: 1. Token效率分解:将token效率分解为三个主要因素:补全情况(completion under a fixed token budget)、条件正确性(conditional correctness given completion)和冗余度(verbosity)。 2. 冗余度细化:当基准元数据提供每个实例的工作量代理时,进一步将冗余度分解为平均verbalization开销和耦合系数。 3. Trace质量评估:当推理trace可用时,添加确定性的trace质量度量,例如grounding、重复和prompt复制。 4. 效率瓶颈分析:通过对分解后的因素进行分析,识别出影响推理效率的关键瓶颈。
关键创新:该论文的关键创新在于提出了一个可分解的推理效率评估框架。该框架能够将token效率分解为多个可解释的因素,从而更细粒度地分析token的使用情况。此外,该框架还能够利用推理trace来评估trace的质量,从而区分退化的循环和verbose但参与的推理。
关键设计:该框架的关键设计包括: 1. Trace-optional设计:该框架既可以用于没有推理trace的情况,也可以用于有推理trace的情况。 2. 确定性的trace质量度量:该框架使用确定性的trace质量度量,避免了人工标注和LLM判断。
🖼️ 关键图片

📊 实验亮点
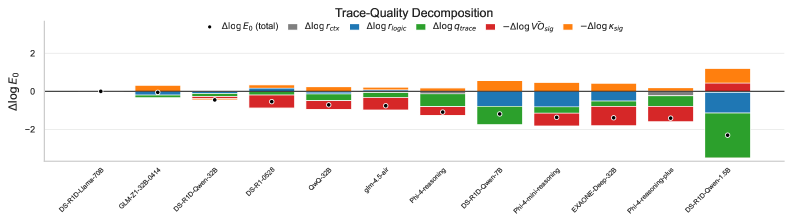
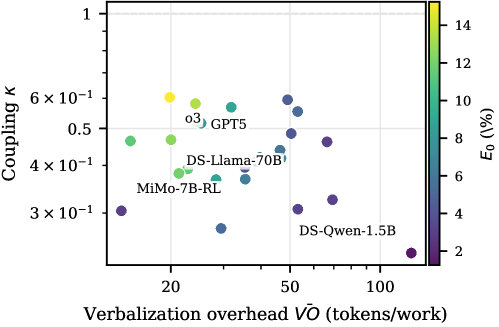
实验结果表明,准确率和token效率排名存在显著差异(Spearman $ρ=0.63$),表明高准确率并不一定意味着高效率。效率差距通常由条件正确性驱动,而verbalization开销变化约为9倍,且与模型规模的相关性较弱。这些发现揭示了不同模型在推理效率方面的差异,并为未来的优化方向提供了线索。
🎯 应用场景
该研究成果可应用于大语言模型的优化和改进,例如,通过识别效率瓶颈,可以针对性地优化模型的结构、训练方法或推理策略。此外,该框架还可以用于评估不同大语言模型的推理效率,为用户选择合适的模型提供参考。该研究还有助于提升大语言模型在资源受限环境下的应用能力。
📄 摘要(原文)
Large language models trained for reasoning trade off inference tokens against accuracy, yet standard evaluations report only final accuracy, obscuring where tokens are spent or wasted. We introduce a trace-optional framework that decomposes token efficiency into interpretable factors: completion under a fixed token budget (avoiding truncation), conditional correctness given completion, and verbosity (token usage). When benchmark metadata provides per-instance workload proxies, we further factor verbosity into two components: mean verbalization overhead (tokens per work unit) and a coupling coefficient capturing how overhead scales with task workload. When reasoning traces are available, we add deterministic trace-quality measures (grounding, repetition, prompt copying) to separate degenerate looping from verbose-but-engaged reasoning, avoiding human labeling and LLM judges. Evaluating 25 models on CogniLoad, we find that accuracy and token-efficiency rankings diverge (Spearman $ρ=0.63$), efficiency gaps are often driven by conditional correctness, and verbalization overhead varies by about 9 times (only weakly related to model scale). Our decomposition reveals distinct bottleneck profiles that suggest different efficiency interventions.