Unsupervised Layer-Wise Dynamic Test Time Adaptation for LLMs
作者: Longhuan Xu, Cunjian Chen, Feng Yin
分类: cs.CL
发布日期: 2026-02-10
💡 一句话要点
提出层级动态测试时自适应方法,提升LLM在无监督环境下的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 测试时自适应 大型语言模型 无监督学习 动态学习率 超网络
📋 核心要点
- 现有无监督测试时自适应方法学习率固定,易过拟合prompt,导致生成质量下降。
- 提出层级动态TTA框架,根据prompt表示、LLM结构和自适应步骤动态调节TTA强度。
- 实验表明,该方法通过学习有效的缩放模式,显著增强TTA,提高稳定性和性能。
📝 摘要(中文)
本文提出了一种针对大型语言模型(LLMs)的测试时自适应(TTA)方法,该方法在部署时利用可用的信号更新模型参数。本文关注的是一种常见但未被充分探索的场景:无监督、样本特定的TTA,即模型仅使用提示本身独立地为每个提示进行调整,而无需黄金答案或外部监督。由于采用固定的、手工设计的学习率进行朴素的无监督TTA可能不稳定,更新可能会过度拟合提示特定的统计信息,偏离期望的答案分布,并最终降低生成质量。因此,本文提出了一种层级动态测试时自适应框架,该框架显式地将TTA强度调节为提示表示、LLM结构和自适应步骤的函数。在该设置中,TTA仅更新LoRA参数,而一个轻量级的超网络预测每层、每步的学习率乘数,从而实现细粒度的控制。在各种数据集和LLM上的实验一致表明,该方法通过学习自适应步骤和Transformer层投影上的有效缩放模式,显著增强了TTA,提高了稳定性,同时提供了更好的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在无监督测试时自适应(TTA)中,由于固定学习率导致的训练不稳定和性能下降问题。现有的无监督TTA方法,在没有黄金标准答案或外部监督的情况下,直接使用prompt本身进行模型参数更新。然而,这种方法容易受到prompt特定统计信息的过度拟合,导致模型输出偏离期望的答案分布,最终降低生成质量。
核心思路:论文的核心思路是引入动态学习率调整机制,根据prompt的表示、LLM的结构以及自适应的步骤,动态地调整每一层和每一步的学习率。通过这种细粒度的控制,可以避免过度拟合,提高TTA的稳定性和有效性。
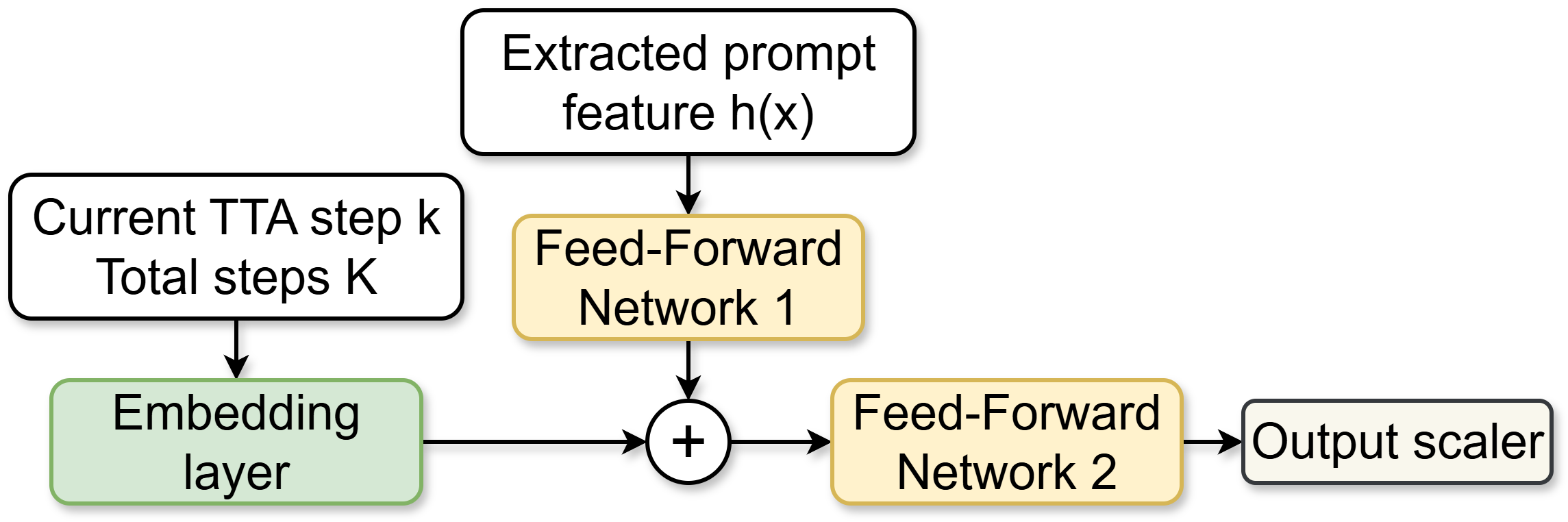
技术框架:整体框架包含以下几个主要模块:1) LoRA参数:TTA仅更新LoRA参数,减少计算量和存储需求。2) 超网络:一个轻量级的超网络,用于预测每层、每步的学习率乘数。3) 动态学习率调整:根据超网络的输出,动态调整每一层和每一步的学习率。4) 前向传播和反向传播:使用调整后的学习率进行前向传播和反向传播,更新LoRA参数。
关键创新:最重要的技术创新点在于提出了层级动态学习率调整机制。与传统的固定学习率方法不同,该方法能够根据prompt的特性和模型的状态,自适应地调整每一层和每一步的学习率,从而更好地适应不同的prompt,提高TTA的稳定性和性能。
关键设计:超网络的设计是关键。超网络接收prompt的表示、LLM的层信息和自适应步骤作为输入,输出每层、每步的学习率乘数。损失函数的设计目标是提高生成质量和稳定性。具体的网络结构和损失函数细节在论文中应该有更详细的描述。
🖼️ 关键图片

📊 实验亮点
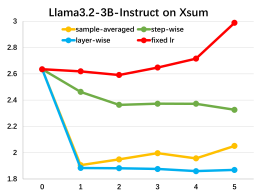
实验结果表明,该方法在各种数据集和LLM上均取得了显著的性能提升。与基线方法相比,该方法能够更有效地利用prompt信息,提高生成质量和稳定性。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要快速适应新任务或新数据的LLM应用场景,例如:个性化推荐、智能客服、机器翻译等。通过在测试时进行自适应调整,可以提高LLM在特定场景下的性能,减少对大量标注数据的依赖,降低模型部署和维护成本。未来,该方法可以进一步扩展到其他类型的模型和任务中。
📄 摘要(原文)
Test-time adaptation (TTA) for large language models (LLMs) updates model parameters at inference time using signals available at deployment. This paper focuses on a common yet under-explored regime: unsupervised, sample-specific TTA, where the model adapts independently for each prompt using only the prompt itself, without gold answers or external supervision. Although appealing, naive unsupervised TTA with a fixed, handcrafted learning rate can be unstable: updates may overfit to prompt-specific statistics, drift from the desired answer distribution, and ultimately degrade generation quality. This failure mode is not surprising, as in this case TTA must adapt to a single prompt within only a few gradient steps, unlike standard training that averages updates over large datasets and long optimization horizons. Therefore, we propose layer-wise dynamic test-time adaptation, a framework which explicitly modulates TTA strength as a function of prompt representation, LLM structure and adaptation step. In our setting, TTA updates only LoRA parameters, and a lightweight hypernetwork predicts per-layer, per-step learning-rate multipliers, enabling fine-grained control. Experiments across various datasets and LLMs consistently show that our method substantially strengthens TTA by learning effective scaling patterns over adaptation steps and transformer layer projections, improving stability while delivering better performance.