TraceMem: Weaving Narrative Memory Schemata from User Conversational Traces
作者: Yiming Shu, Pei Liu, Tiange Zhang, Ruiyang Gao, Jun Ma, Chen Sun
分类: cs.CL
发布日期: 2026-02-10
🔗 代码/项目: GITHUB
💡 一句话要点
TraceMem:从用户对话轨迹中构建叙事记忆模式,提升LLM长期交互能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长期对话 叙事记忆 语言模型 主题分割 分层聚类
📋 核心要点
- 现有LLM受限于上下文窗口,难以维持长期对话,且现有记忆系统忽略了对话的叙事连贯性。
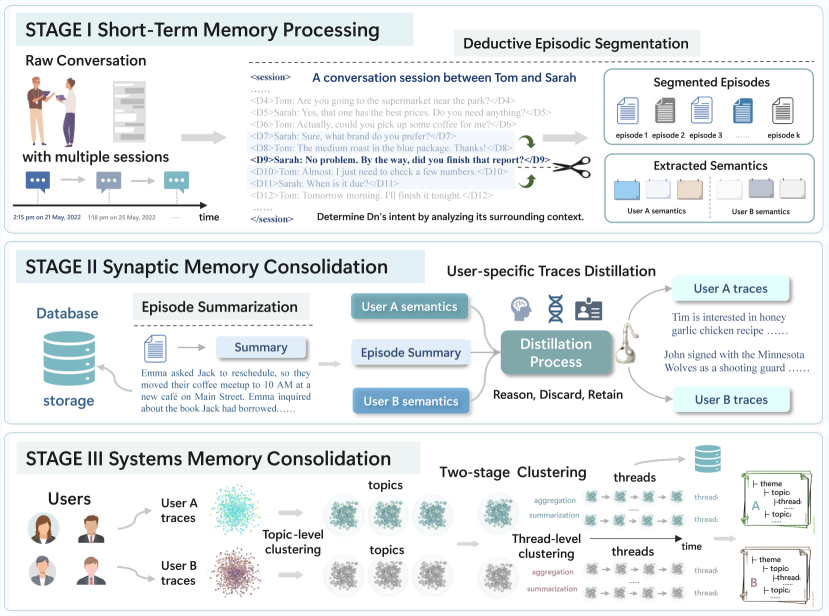
- TraceMem通过短期记忆处理、突触记忆巩固和系统记忆巩固三个阶段,从对话轨迹中构建叙事记忆模式。
- 在LoCoMo基准测试中,TraceMem取得了最先进的性能,并在多跳和时间推理方面超越了基线。
📝 摘要(中文)
大型语言模型(LLMs)在维持长期交互方面面临瓶颈,因为其有限的上下文窗口难以管理随时间推移的对话历史。现有的记忆系统通常将交互视为不连续的片段,未能捕捉对话流中潜在的叙事连贯性。我们提出了TraceMem,一个受认知启发的框架,通过一个三阶段流程从用户对话轨迹中编织结构化的叙事记忆模式:(1)短期记忆处理,采用演绎式主题分割方法来划分情节边界并提取语义表示;(2)突触记忆巩固,将情节总结为情节记忆,然后将其与语义一起提炼成用户特定的轨迹;(3)系统记忆巩固,利用两阶段分层聚类将这些轨迹组织成统一主题下连贯的、随时间演变的叙事线索。这些线索被封装成结构化的用户记忆卡,形成叙事记忆模式。在记忆利用方面,我们提供了一种代理搜索机制来增强推理过程。在LoCoMo基准上的评估表明,TraceMem以一种受大脑启发的架构实现了最先进的性能。分析表明,通过构建连贯的叙事,它在多跳和时间推理方面超越了基线,突显了其在深度叙事理解中的重要作用。此外,我们还对记忆系统进行了公开讨论,提供了我们对该领域的看法和未来展望。我们的代码实现在:https://github.com/YimingShu-teay/TraceMem
🔬 方法详解
问题定义:现有大型语言模型在处理长期对话时,由于上下文窗口的限制,无法有效地管理和利用长时间的对话历史。传统的记忆系统通常将对话视为独立的片段,忽略了对话中蕴含的叙事结构和连贯性,导致模型在理解和推理长期对话内容时表现不佳。因此,如何构建能够捕捉对话叙事结构的记忆系统,是解决长期对话理解的关键问题。
核心思路:TraceMem的核心思路是模拟人类认知过程,将对话历史组织成结构化的叙事记忆模式。它通过三个阶段的处理,将对话片段转化为情节记忆,再将情节记忆提炼成用户特定的轨迹,最终将这些轨迹组织成连贯的叙事线索。这种分层结构化的记忆方式,能够更好地捕捉对话的语义和叙事关系,从而提升模型在长期对话中的理解和推理能力。
技术框架:TraceMem的技术框架主要包含三个阶段: 1. 短期记忆处理:使用演绎式主题分割方法,将对话分割成不同的情节,并提取每个情节的语义表示。 2. 突触记忆巩固:将每个情节总结成情节记忆,然后将情节记忆与语义信息一起提炼成用户特定的轨迹。 3. 系统记忆巩固:使用两阶段分层聚类方法,将用户轨迹组织成连贯的叙事线索,形成结构化的用户记忆卡。
关键创新:TraceMem的关键创新在于其构建叙事记忆模式的方式。它不仅仅是简单地存储对话历史,而是通过主题分割、情节总结和分层聚类等方法,将对话组织成具有叙事结构的记忆。这种叙事记忆模式能够更好地捕捉对话的语义和叙事关系,从而提升模型在长期对话中的理解和推理能力。此外,TraceMem还提供了一种代理搜索机制,用于在叙事记忆模式中进行高效的检索和推理。
关键设计:TraceMem的关键设计包括: 1. 演绎式主题分割:用于将对话分割成情节,具体实现方式未知。 2. 两阶段分层聚类:用于将用户轨迹组织成叙事线索,具体聚类算法未知。 3. 代理搜索机制:用于在叙事记忆模式中进行检索和推理,具体实现方式未知。
🖼️ 关键图片

📊 实验亮点
TraceMem在LoCoMo基准测试中取得了最先进的性能,证明了其在长期对话理解方面的有效性。实验结果表明,TraceMem在多跳和时间推理方面显著超越了基线模型,这表明其构建的叙事记忆模式能够有效地捕捉对话的语义和叙事关系,从而提升模型的推理能力。具体的性能数据和提升幅度未知。
🎯 应用场景
TraceMem的潜在应用领域包括智能客服、虚拟助手、游戏AI等需要长期对话交互的场景。通过构建叙事记忆模式,TraceMem可以提升模型在长期对话中的理解和推理能力,从而实现更自然、更流畅的对话体验。未来,TraceMem还可以应用于个性化推荐、情感分析等领域,为用户提供更精准、更贴心的服务。
📄 摘要(原文)
Sustaining long-term interactions remains a bottleneck for Large Language Models (LLMs), as their limited context windows struggle to manage dialogue histories that extend over time. Existing memory systems often treat interactions as disjointed snippets, failing to capture the underlying narrative coherence of the dialogue stream. We propose TraceMem, a cognitively-inspired framework that weaves structured, narrative memory schemata from user conversational traces through a three-stage pipeline: (1) Short-term Memory Processing, which employs a deductive topic segmentation approach to demarcate episode boundaries and extract semantic representation; (2) Synaptic Memory Consolidation, a process that summarizes episodes into episodic memories before distilling them alongside semantics into user-specific traces; and (3) Systems Memory Consolidation, which utilizes two-stage hierarchical clustering to organize these traces into coherent, time-evolving narrative threads under unifying themes. These threads are encapsulated into structured user memory cards, forming narrative memory schemata. For memory utilization, we provide an agentic search mechanism to enhance reasoning process. Evaluation on the LoCoMo benchmark shows that TraceMem achieves state-of-the-art performance with a brain-inspired architecture. Analysis shows that by constructing coherent narratives, it surpasses baselines in multi-hop and temporal reasoning, underscoring its essential role in deep narrative comprehension. Additionally, we provide an open discussion on memory systems, offering our perspectives and future outlook on the field. Our code implementation is available at: https://github.com/YimingShu-teay/TraceMem